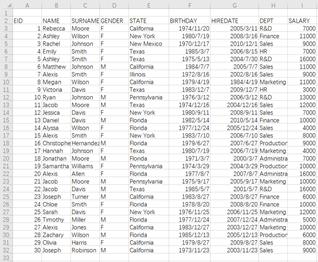
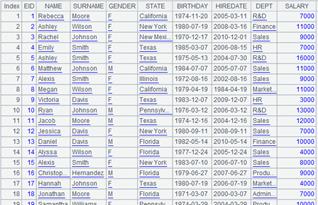
xlsimport ()
本章介绍xlsimport()函数的多种用法。
f.xlsimport()
描述:
语法:
备注:
从Excel文件f的s页中,读取b行到e行的字段Fi,返回成序表;参数b和e都省略时表示从第一行读取到最后一行。
参数:
|
f |
Excel文件。 |
|
Fi |
读出的字段,缺省读出所有,用#时表示用序号定位。 |
|
s |
sheet页的页名/序号,缺省找第一个sheet。 |
|
b |
起始行,b省略表示从第一行开始读到e行,此时“:”可以省略。 |
|
e |
结束行,e省略表示从b行读取到最后一行,此时“:”不可以省略。若e比实际行数大,则以实际最后行数为准。e<0表示倒数。 |
|
p |
Excel文件密码。 |
选项:
|
@t |
f中第一行记录作为标题,缺省使用_1,_2,…。有b参数时认为b行是标题。 |
|
@c |
返回成游标,只支持xlsx格式;此时e不能小于0。 |
|
@b |
读取时去除前后的空白行,与@c选项组合使用时无效。 |
|
@w |
数据返回形式为序列组成的序列,成员为格值;与@t、@c、@b选项互斥。 |
|
@p |
必须与@w同时使用,返回由Excel列组成的序列的序列。 |
|
@s |
返回成由回车/tab作为分隔符的串。 |
|
@n |
读入时去除字符串两端的空白字符,空串则读成null。 |
返回值:
序表
示例:
读取整个xls文件:
|
|
A |
|
|
1 |
=file("emp1.xls").xlsimport() |
|
|
2 |
=file("password_abc.xls").xlsimport(;;"abc") |
读取带密码的xls文件,password_abc.xls的密码为abc。 |

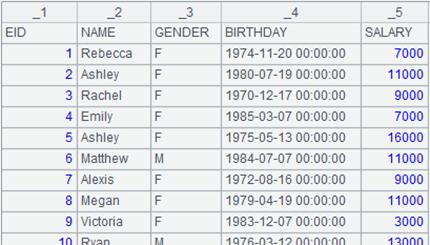
读取xls文件时将第一行作为标题,并读取指定字段:
|
|
A |
|
|
1 |
=file("emp1.xls").xlsimport@t(NAME,GENDER;) |
读取字段NAME,GENDER中的数据:
|
|
2 |
=file("emp1.xls").xlsimport@t(#1,#2;) |
读取xls中第1个和第2个字段中的数据:
|
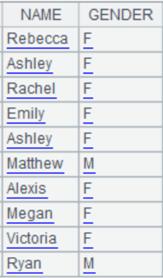
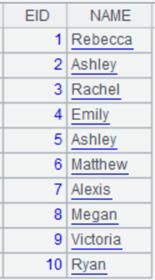
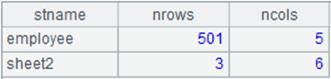
多sheet页文件的读取:
|
|
A |
|
|
1 |
=file("emp2.xlsx").xlsimport@t(;"t1") |
emp2.xlsx中包含两个sheet页,sheet页名称分别为t1,t2。 通过sheet页名称读取t1页中的数据:
|
|
2 |
=file("emp2.xlsx").xlsimport@t(;2) |
读取第2个sheet页中的数据:
|
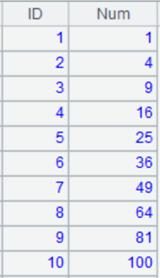
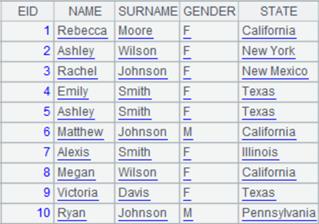
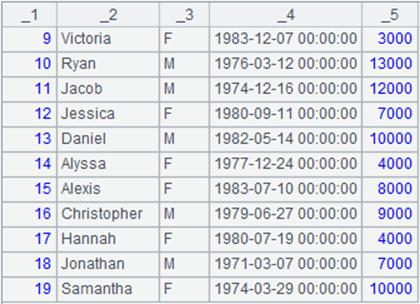
指定起始行、结束行:
|
|
A |
|
|
1 |
=file("emp2.xlsx").xlsimport(;2,3:6) |
读取emp2.xlsx第2个sheet页中的第3行至第6行:
|
|
2 |
=file("emp2.xlsx").xlsimport@t(;2,3:6) |
使用@t选项,将第3行数据作为标题:
|
|
3 |
=file("emp2.xlsx").xlsimport@t(;"t2",:6) |
省略参数b,认为第1行为标题行,并从第1行读读到第6行,这里“:”不可省略:
|
|
4 |
=file("emp2.xlsx").xlsimport(;"t2",7:) |
省略参数e,从第7行读到最后一行,“:”可省略:
|
|
5 |
=file("emp2.xlsx").xlsimport(;"t2",3:-4) |
从第3行读到倒数第4行:
|
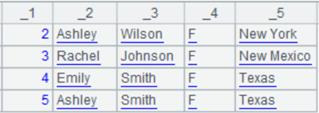
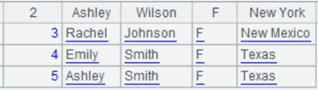



读取xlsx文件内容,并返回成游标:
|
|
A |
|
|
1 |
=file("emp3.xlsx").xlsimport@c() |
返回游标。 |
|
2 |
=A1.fetch() |
|
读取时去除Excel内容前后的空白行:
|
|
A |
|
|
1 |
=file("emp4.xls") |
|
|
2 |
=A1.xlsimport@tb() |
使用@b选项,读取时去除Excel内容前后的空白行,且将第一行记录作为标题:
|

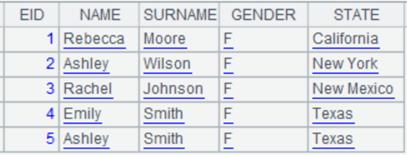
数据返回形式为序列组成的序列:
|
|
A |
|
|
1 |
=file("emp1.xls").xlsimport@w() |
使用@w选项,返回序列组成的序列,每一行作为序列的成员:
|
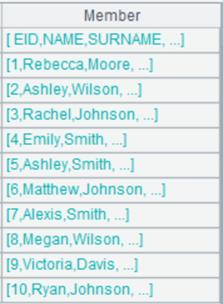
返回Excel列组成的序列:
|
|
A |
|
|
1 |
=file("emp1.xls").xlsimport@wp() |
使用@wp选项,返回Excel列组成的序列,每一列作为序列的成员:
|
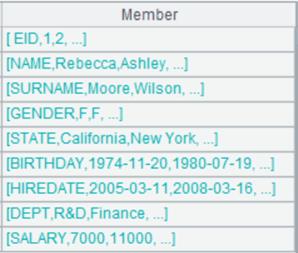
返回以/tab作为分隔符的串:
|
|
A |
|
|
1 |
=file("emp1.xls").xlsimport@s() |
使用@s选项,返回以回车/tab作为分隔符的串:
|

读取时去除字符串两端的空白字符,空串读成null:
|
|
A |
|
|
1 |
=file("emp5.xls") |
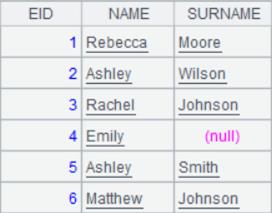
emp5.xls内容如下:
|
|
2 |
=A1.xlsimport@nt() |
读取时去除“ Rebecca ”两端的空白字符,空串读成null:
|

相关概念:
xo.xlsimport()
描述:
从Excel对象中取出序表。
语法:
xo.xlsimport(Fi,..;s,b:e)
备注:
从Excel指定sheet页中取出b到e行的内容,返回序表;参数b和e都省略时表示从第一行读取到最后一行。
参数:
|
xo |
非@w方式读出的Excel对象。 |
|
Fi |
Excel列名;省略时取出全部列,用#时表示用序号定位。 |
|
s |
sheet页的页名/序号,缺省找第一个sheet。 |
|
b |
起始行,b省略表示从第一行开始读到e行,此时“:”可以省略。 |
|
e |
结束行,e省略表示从b行读取到最后一行,此时“:”不可以省略。若e比实际行数大,则以实际最后行数为准。e<0表示倒数;xo为@r方式读出的Excel对象时,e必须是正整数。 |
选项:
|
@t |
xo中第一行记录作为标题,缺省使用_1,_2,…,有b参数时认为b行是标题。 |
|
@c |
返回成游标,Excel对象必须是用@r读出的,且e不能小于0。 |
|
@b |
读取时去除前后的空白行,与@c选项组合使用时无效。 |
|
@w |
数据返回形式为序列组成的序列,成员为格值;与@t、@c、@b选项互斥。 |
|
@p |
必须与@w同时使用,返回由Excel列组成的序列的序列。 |
|
@s |
返回成由回车/tab作为分隔符的串。 |
|
@n |
读取时去除字符串两端的空白字符,空串则读成null。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=file("E1.xls").xlsopen() |
读取E1.xls文件,并返回excel对象:
|
|
2 |
=A1.xlsimport() |
无参数时,读取第1个sheet页中的所有数据:
|
|
3 |
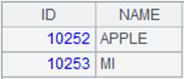
=A1.xlsimport@t(ID,NAME;2) |
取出第2页中列名为ID及NAME的列,并将第一行作为标题:
|
|
4 |
=A1.xlsimport(;"employee",10:20) |
取出名为employee的sheet页中的第10行到第20行的内容:
|
|
5 |
D:/excel/emp.xls |
emp.xls内容如下:
|
|
6 |
=file(A5).xlsopen().xlsimport@tb() |
使用@b选项,去除前后的空白行:
|
|
7 |
=file("E2.xlsx").xlsopen@r() |
以@r方式读取Excel文件。 |
|
8 |
=A7.xlsimport@c() |
将文件内容返回成游标。 |
|
9 |
=file("E3.xls").xlsopen().xlsimport@w(;2) |
使用@w选项,返回序列组成的序列,每一行作为序列的成员:
|
|
10 |
=file("E4.xls").xlsopen().xlsimport@wp() |
使用@wp选项,返回Excel列组成的序列,每一列作为序列的成员:
|
|
11 |
=file("E5.xls").xlsopen().xlsimport@s() |
使用@s选项,返回以回车/tab作为分隔符的串:
|
|
12 |
=file("E6.xls") |
E6.xls文件内容如下:
|
|
13 |
=A12.xlsopen().xlsimport@n() |
读取时去除“ Rebecca ”两端的空白字符,空串读成null:
|