
循环函数中的表达式书写规则
描述:
循环函数表达式的共同规则。
备注:
针对循环函数,如r.( x )、r.run(x)、A.( x )、A. run(x)中的x表达式,定义如下规则:
1, 基成员:~与A.~,~特指当前正在处理的记录。
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE") |
|
|
2 |
=A1.(age(~.HIREDATE)) |
[9,6,3,7,9,8,…] |
|
3 |
=A1.new(~.NAME:Name,age(~.HIREDATE):Workage) |
|
2,序号:#、A.#,#特指基成员的次序号。
|
|
A |
|
|
1 |
=demo.query("select top 10 * from EMPLOYEE") |
|
|
2 |
=A1.(#) |
获取A1序表中记录的序号组成的序列,返回结果为:[1,2,3,4,5,6,7,8,9,10]。 |
|
|
A |
|
|
1 |
=create(UID, Time, Amount) |
创建包含字段UID, Time, Amount的空白序表。 |
|
2 |
=10.(10000+rand(200)*100) |
10个生成随机数组成的序列。 |
|
3 |
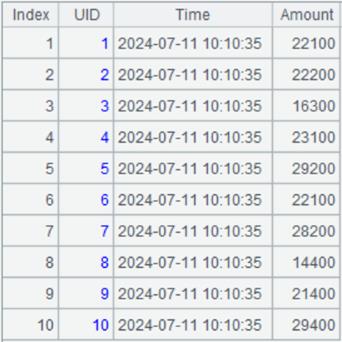
>A2.run(A1.insert(0, A2.#, datetime(now()),A2.~)) |
向A1序表中插入10条记录,A2.#表示A2中的成员序号,A2.~表示A2的成员值,执行成功后A1序表内容如下:
|
3,字段:F、~.F、r.F、A.F 相当于A.~.F,不循环时,A.F相当于A(1).F
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE") |
|
|
2 |
=A1.(age(HIREDATE)) |
|
|
3 |
=A1.(age(~.HIREDATE)) |
结果同A2。 |
|
4 |
=A1.(age(A1.HIREDATE)) |
结果同A2。 |
|
5 |
=A1.HIREDATE |
2005-03-11,不循环相当于A1(1).HIREDATE。 |

4, A[i],~[i],在循环中,相当于A(#+i),即从A的当前成员往后数。
5,第i个成员返回,越界不报错,返回null。F[…]则相当于A[…].F 。
|
|
A |
|
|
1 |
=demo.query("select ORDERID,AMOUNT,'' as ACCUMULATION from SALES") |
|
|
2 |
=A1.run(ACCUMULATION=AMOUNT+ACCUMULATION[-1]) |
用上一条记录的ACCUMULATION加当前的AMOUNT,得到当前记录的ACCUMULATION。 |
6,A[a:b]、~[a:b],在循环中,以A(#+a)为起始值,以 A(#+b)为结束值。
7,返回这个区间的成员组成的序列。a缺省为1-#,b缺省为A.len()-# 。
|
|
A |
|
|
1 |
=demo.query("select STOCKID,DATE,CLOSING,'' as FirstThree from STOCKRECORDS") |
|
|
2 |
=A1.run(FIRSTTHREE=~[-3:-1].(CLOSING).avg()) |
~[-3:-1]表示当前行往前数三条记录组成的集合。 |
8,迭代:A1.f1(A2.f2(x)),x中的符号将优先解释为从属于A2。 如果x从属于A1要写成A1.f1(A2.f2(A1.x))。
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE") |
|
|
2 |
=demo.query("select * from DEPARTMENT") |
|
|
3 |
=A2.run(MANAGER=A1.select@1(EID==A2.~.MANAGER).NAME) |
对循环嵌套的引用。 |
9,聚合: A.f(x) ,相当于A.(x).f(),f是聚合函数,x可为空。注意,与其它聚合函数规则不同,A.count(x)中x为布尔表达式。
10,get(level,F;a:b),在多层循环函数中取出上层的基成员信息。
|
|
A |
|
|
1 |
[1,2,3] |
|
|
2 |
=A1.(A1.(abs(~-get(1)))) |
计算每个值与其他值的最大距离。 |
|
3 |
=demo.query("select * from employee") |
|
|
4 |
=A3.derive(A3.max(abs(SALARY-get(1,SALARY))):MaxDiff) |
计算当前工资和其他人的最大工资差。 |