
top()
本章节介绍top()函数的用法。
A.top()
描述:
序列成员计算表达式后获取前n个值组成的序列。
语法:
|
A.top(n,x) |
针对序列A的成员计算表达式x后排序,返回前n个x值组成的序列。 |
|
A.top(n;x,...) |
针对序列A的成员计算表达式x,…后排序,返回前n个A成员组成的序列。 |
|
A.top(n,y,x) |
针对序列A的成员先计算表达式x,再对x结果值进行y计算,然后根据y值对x排序,获取前n个x值组成的序列。 |
备注:
针对序列的每个成员计算表达式,排序后返回前n个值组成的序列。
序列存在重复成员时,默认采用连续排名方式。
n>0时取前n个最小值,n<0时取前n个最大值,n为0时返回null,n不可省略,x省略解释为~。
参数:
|
A |
序列。 |
|
n |
整数。 |
|
y |
表达式。 |
|
x |
表达式。 |
选项:
|
@1 |
n为±1时返回单值。 |
|
@0 |
不忽略null,缺省忽略null。 |
|
@r |
采用美式排序,即并列名次占用名次。 |
|
@i |
采用中式排序,即并列名次不占用名次。 |
序列
示例:
使用A.top(n,x):
|
|
A |
|
|
1 |
=connect("demo").query("select top 10 NAME,SALARY from employee") |
返回序表:
|
|
2 |
=A1.top(3,SALARY+500) |
将序表根据SALARY+500计算后的结果值排序,取前3个最小计算值组成的序列:
|
|
3 |
=A1.top(-3,SALARY) |
将序表根据SALARY排序,n<0,取前3个最大SALARY值组成的序列:
|
|
4 |
=[2,6,4,12,6,5,2].top(4) |
参数x缺省为~,返回结果为:
|




使用A.top(n;x,…):
|
|
A |
|
|
1 |
=connect("demo").query("select top 10 NAME,SALARY from employee") |
返回序表:
|
|
2 |
=A1.top(3;SALARY+500) |
将序表根据SALARY+500计算后的结果值排序,取前3个最小计算值对应的序表成员组成的序列:
|
|
3 |
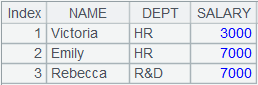
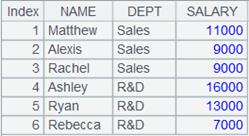
=A1.top(-6;DEPT,SALARY) |
将序表根据DEPT,SALARY排序后,取前6个最大值对应的序表成员组成的序列:
|

使用A.top(n,y,x):
|
|
A |
|
|
1 |
[21,3,12,5] |
|
|
2 |
=A1.top(3,~%10,~+6) |
先对序列计算表达式x: ~+6,此时x结果为[27,9,18,11],然后再对x计算表达式y: ~%10,此时y结果为[7,9,8,1],结果返回前3个最小y值对应的x值组成的序列,返回结果如下:
|
|
3 |
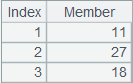
=A1.top(-3,~%10,~+6) |
n为-3,返回前3个最大y值对应的x值组成的序列,返回结果如下:
|

使用@1选项,n为±1时返回单值:
|
|
A |
|
|
1 |
=[2,6,4,12,6,5] |
|
|
2 |
=A1.top(1) |
返回前1个最小值组成的序列:
|
|
3 |
=A1.top@1(1) |
使用@1选项,n为1则返回序列成员的最小值:
|
|
4 |
=A1.top@1(-1) |
使用@1选项,n为-1则返回序列成员的最大值:
|



使用@0选项,不忽略null:
|
|
A |
|
|
1 |
=[5,7,2,null,3] |
|
|
2 |
=A1.top(3) |
取序列中前3个最小成员值,默认忽略null:
|
|
3 |
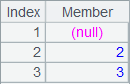
=A1.top@0(3) |
使用@0选项,不忽略null:
|

使用@r/@i选项,对于序列中存在重复成员时排序方式不同:
|
|
A |
|
|
1 |
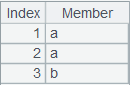
[a,b,e,b,d,a,c,c,b] |
返回存在重复成员的序列。 |
|
2 |
=A1.top(3) |
默认采用连续排名方式,取前三个最小值:
|
|
3 |
=A1.top@r(3) |
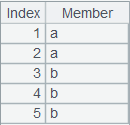
使用@r选项,采用美式排名,即并列名次占用名次,相当于排序后名次为[1,1,3,3,3,6,6,8,9],返回结果如下:
|
|
4 |
=A1.top@i(3) |
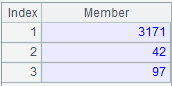
使用@r选项,采用中式排名,即并列名次不占用名次,相当于排序后名次为[1,1,2,2,2,3,3,4,5] ,返回结果如下:
|
相关概念: