
sortx()
本章介绍sortx()的多种用法。
ch.sortx()
描述:
对管道中的成员排序。
语法:
ch.sortx(x,…)
备注:
根据x对ch管道排序,返回成管道。
该函数为结果集函数。
参数:
|
ch |
管道。 |
|
x |
表达式,根据管道ch的成员升序排序。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
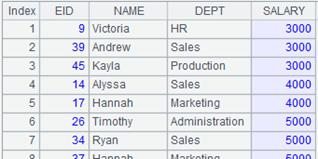
=demo.cursor("select EID,NAME,DEPT,SALARY from EMPLOYEE order by EID desc") |
返回取数游标。 |
|
2 |
=channel() |
创建管道。 |
|
3 |
=A2.sortx(SALARY,EID) |
根据字段SALARY,EID对管道成员排序。 |
|
4 |
=A1.push(A2) |
将游标A1中的数据推送到管道A2。 |
|
5 |
=A1.fetch() |
从A1游标中取数。 |
|
6 |
=A2.result() |
结果返回成游标。 |
|
7 |
=A6.fetch() |
|
cs.sortx()
描述:
对游标排序。
语法:
cs.sortx(x,…;n)
备注:
根据x对cs游标排序,返回成游标。该函数返回的游标不可回转。
参数:
|
cs |
游标。cs为多路游标时并行取数计算,返回结果为单路游标。 |
|
x |
表达式,根据游标cs的成员升序排序。 |
|
n |
缓冲区行数,运算过程中如果分组数达到n,则把分组结果写入临时文件中;n<1时缓冲区用缺省值的n倍;缺省值由集算器自动计算。 |
选项:
|
@0 |
将值为null的数据排在最后;@0和@n不能一起使用。 |
|
@n |
提高效率,x返回值是正整数时才可用该选项,可以直接用序号定义;@0和@n不能一起使用。 |
|
@g |
参数n解释为分段表达式,先根据表达式n分段,分段后再排序。 |
返回值:
游标
示例:


cs.sortx()
描述:
对集群游标排序。
备注:
选项:
|
@c |
分机结果间不再归并,返回成集群游标,继承分布方式。 |
参数:
|
cs |
集群游标。 |
|
x |
表达式,根据集群游标cs的成员升序排序。 |
|
n |
缓冲区行数,运算过程中如果分组数达到n,则把分组结果写入临时文件中;n<1时缓冲区用缺省值的n倍;缺省值由集算器自动计算。 |
返回值:
集群游标
示例:
|
|
A |
|
|
1 |
[192.168.0.110:8281,192.168.18.143:8281] |
|
|
2 |
=file("emp.ctx", A1) |
|
|
3 |
=A2.open() |
打开集群组表文件。 |
|
4 |
=A3.cursor() |
返回集群游标。 |
|
5 |
=A4.sortx(EID) |
将集群游标根据EID排序,结果返回集群游标。 |
f.sortx()
描述:
将数据文件/文件序列排序后生成新的文件。
语法:
|
f.sortx(Fi,…;fn ,s) |
将数据文件根据Fi排序后生成新的文件。 |
|
[fi,…].sortx(Fi,…;fn ,s) |
将数据文件序列根据Fi排序后生成新的文件。参数Fi省略时表示简单合并。 |
备注:
将数据文件f /文件序列[fi,…]根据Fi排序后生成新的文件fn,返回非null表示成功。
参数:
|
f |
集文件/文本文件对象。 |
|
[fi,…] |
集文件/文本文件序列,其中fi,…为同构文件。 |
|
Fi |
f中的字段名,用于排序的字段。 |
|
fn |
集文件/文本文件对象,省略时生成临时文件并返回其上的游标。 |
|
s |
自选分隔符,缺省默认分隔符是tab。省略参数s时,s前边的逗号可以省略。 f/[fi,…]为集文件/集文件序列时忽略s。 |
选项:
|
@b |
对集文件排序,f/[fi,…]为集文件/集文件序列时必须使用@b选项。 |
|
@t |
第一行记录作为字段名,f/[fi,…]为文本文件时使用。 |
|
@c |
s缺省时用逗号作为分隔符,f/[fi,…]为文本文件时使用。 |
返回值:
Boolean值/游标
示例:
集文件排序:
|
|
A |
|
|
1 |
=file("PERFORMANCE.btx") |
集文件对象,文件内容如下:
|
|
2 |
=file("PER-cp.btx") |
集文件对象 |
|
3 |
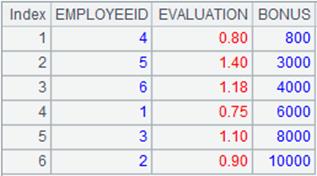
=A1.sortx@b(BONUS;A2) |
将PERFORMANCE.btx根据BONUS字段排序后生成新的集文件PER-cp.btx,内容如下:
|
|
4 |
=A1.sortx@b(BONUS) |
省略参数fn,在临时目录中生成临时文件,并返回游标,游标中数据内容同A3。 |

集文件序列排序:
|
|
A |
|
|
1 |
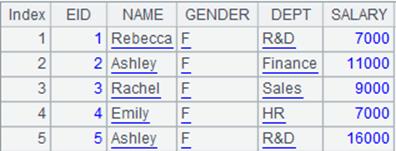
=file("f_emp.btx") |
集文件对象,文件内容如下:
|
|
2 |
=file("m_emp.btx") |
集文件对象,文件内容如下:
|
|
3 |
=file("emp_all.btx") |
|
|
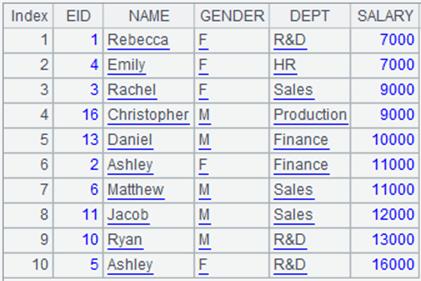
4 |
将f_emp.btx及m_emp.btx根据SALARY、EID字段排序后生成新的集文件emp_all.btx,内容如下:
|
|
|
5 |
=[A1,A2].sortx@b(SALARY) |
省略参数fn,返回游标。 |

省略参数Fi,集文件序列简单合并:
|
|
A |
|
|
1 |
=file("f_emp.btx") |
集文件对象,文件内容如下:
|
|
2 |
=file("m_emp.btx") |
集文件对象,文件内容如下:
|
|
3 |
=file("emp_gb.btx") |
|
|
4 |
=[A1,A2].sortx@b(;A3) |
将f_emp.btx与m_emp.btx简单合并后生成新的集文件emp_gb.btx,内容如下:
|


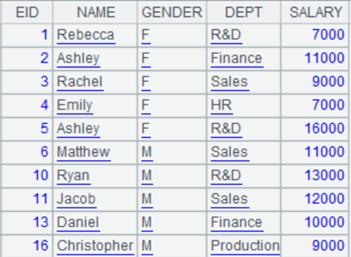
文本文件排序:
|
|
A |
|
|
1 |
=file("emp.txt") |
emp.txt文件内容如下:
|
|
2 |
=file("emp-cp.csv") |
|
|
3 |
=A1.sortx@ct(NAME;A2) |
将emp.txt内容按照NAME排序后,写入到文件emp-cp.csv中,emp.txt中字段分隔符为逗号,将第一行作为字段名。 |
|
4 |
=A2.import@t() |
读取emp-cp.csv文件,返回结果如下:
|

