
merge()
本章节介绍merge()函数的用法。
A.merge()
描述:
归并计算,将多个序表/排列合并。
语法:
备注:
将序列A的成员按照字段xi有序归并。
缺省认为A(i)对[xi,…]有序;xi省略且A(i)无主键或者A(i)无序时,必须使用@o选项,仅简单合并。
参数:
|
A |
结构相同的多个序表/排列组成的序列。 |
|
xi |
字段名,如果是按照多字段合并,字段间用逗号分隔,例如:x1,x2...。 xi缺省为A(i)的主键。 |
选项:
|
@u |
A(i)的成员按顺序合并到一起组成新的序表/排列,去掉重复的成员。xi相同则认为对应的A(i)成员相同。 |
|
@i |
返回A(i)共同的成员组成的序表/排列。 |
|
@d |
从A(1)中去掉A(2) &…A(n)中的成员后形成的新序表/排列。 |
|
@o |
不假定A(i)对[xi,…]有序,不使用归并计算仅简单合并。 |
|
@0 |
null排最后。 |
|
@x |
返回A(i)去掉共同的成员组成的序表/序列。 |
返回值:
序表/排列
示例:
有序归并:
|
|
A |
|
|
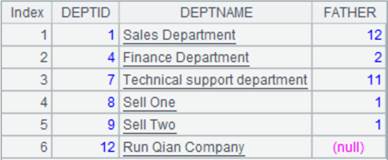
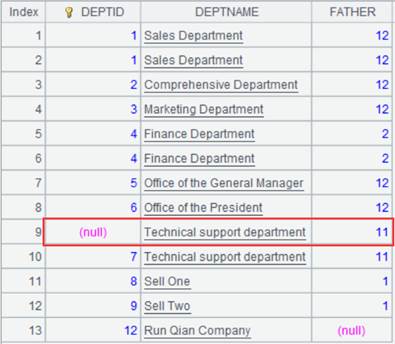
1 |
=demo.query("select top 6 * from DEPT order by FATHER ").sort(DEPTID,DEPTNAME) |
返回字段DEPTID,DEPTNAME对有序的序表:
|
|
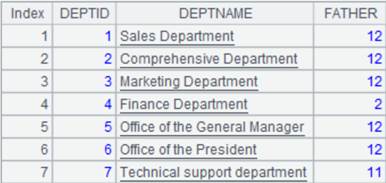
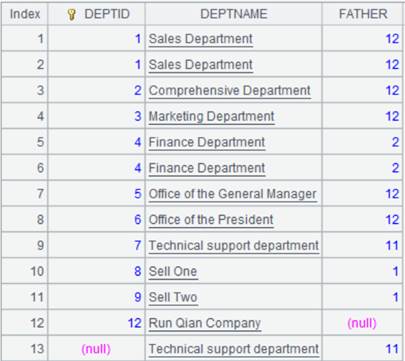
2 |
=demo.query("select * from DEPT where DEPTID <8 order by FATHER").sort(DEPTID,DEPTNAME) |
返回字段DEPTID,DEPTNAME对有序的序表:
|
|
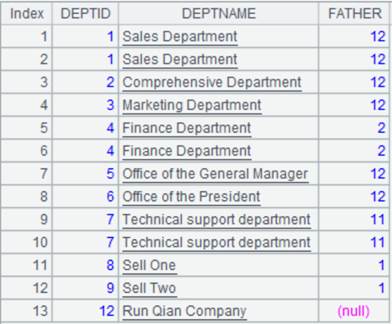
3 |
=[A1,A2].merge(DEPTID,DEPTNAME) |
将A1和A2按照DEPTID,DEPTNAME有序合并:
|
xi缺省为A(i)的主键,按主键归并:
|
|
A |
|
|
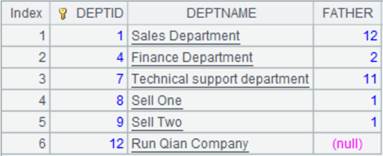
1 |
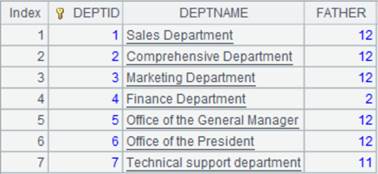
=connect("demo").query("select top 6 * from DEPT order by FATHER ").keys(DEPTID).sort(DEPTID) |
返回以DEPTID为主键的序表:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER").keys(DEPTID).sort(DEPTID) |
返回以DEPTID为主键的序表:
|
|
3 |
=[A1,A2].merge() |
省略xi参数,按主键DEPTID归并:
|
多种有序归并方式:
|
|
A |
|
|
1 |
=connect("demo").query("select top 6 * from DEPT order by FATHER ").keys(DEPTID).sort(DEPTID) |
返回以DEPTID为主键的序表:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER").keys(DEPTID).sort(DEPTID) |
返回以DEPTID为主键的序表:
|
|
3 |
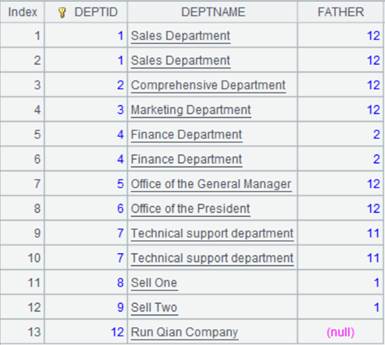
=[A1,A2].merge@u() |
xi参数省略,按主键有序归并,使用@u选项,并去掉DEPTID重复的成员:
|
|
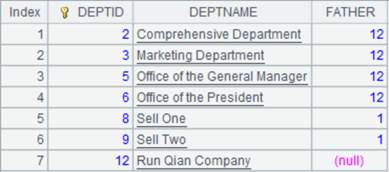
4 |
=[A1,A2].merge@i() |
xi参数省略,按主键有序归并,使用@i选项,只保留[A1,A2]中重复的成员:
|
|
5 |
=[A1,A2].merge@d() |
xi参数省略,按主键有序归并,使用@d选项,返回A1中去除A2成员后的剩余成员组成的序列:
|
|
6 |
=[A1,A2].merge@x() |
xi参数省略,按主键有序归并,使用@x选项,返回[A1,A2]去掉共同成员后剩余成员组成的序列:
|
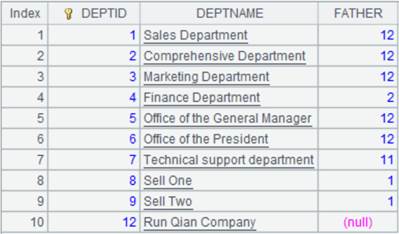

使用@o选项,不使用有序归并,仅简单合并:
|
|
A |
|
|
1 |
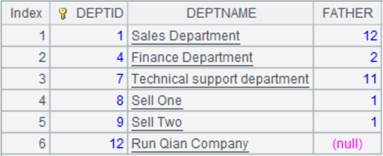
=connect("demo").query("select top 6 * from DEPT order by FATHER ") |
返回序表:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER") |
返回序表:
|
|
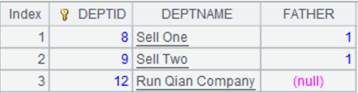
3 |
=[A1,A2].merge@o() |
A1、A2数据无序,使用@o选项,仅简单合并,不排序:
|



用@0选项,null排到最后:
|
|
A |
|
|
1 |
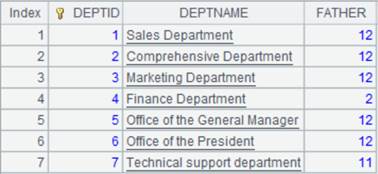
=connect("demo").query("select top 6 * from DEPT order by FATHER ").keys(DEPTID).sort(DEPTID) |
A1返回序表如下:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER").keys(DEPTID).sort(DEPTID) |
|
|
3 |
=A2(7).modify(null:DEPTID) |
此时A2序表内容如下:
|
|
4 |
=[A1,A2].merge() |
|
|
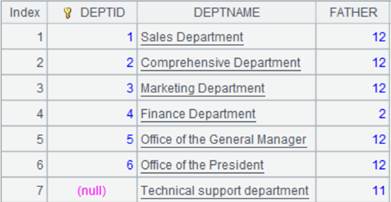
5 |
=[A1,A2].merge@0() |
xi参数省略,按主键有序归并,使用@0选项,将DEPTID 为null的记录排到最后:
|

CS.merge()
描述:
针对游标序列成员做归并运算后返回多路游标。
备注:
CS是对[xi,…]有序的游标的序列,针对其成员输出的对应序列按照表达式xi做有序归并运算,结果返回多路游标。
游标中序列的成员必须同构。支持多路游标, 若成员是多路游标,则必须路数相同且同步分段。
该函数属于延迟计算函数。
选项:
|
@u |
并集运算,CS游标序列的成员按顺序合并到一起组成新的游标,去掉重复的成员。缺省包含所有重复成员。 |
|
@i |
交集运算,返回CS游标序列中共同的成员组成的游标。 |
|
@d |
差集运算,从游标CS1中去掉游标CS2、…CSn中的成员后形成的新游标。 |
|
@0 |
null排最后。 |
|
@x |
从游标CS1、CS2、...CSn中取出不重复的成员组成的新游标。 |
参数:
|
CS |
游标组成的序列。 |
|
xi |
表达式,如果是按照多字段归并,字段间用逗号分隔,例如:x1,x2... |
示例:
|
|
A |
|
|
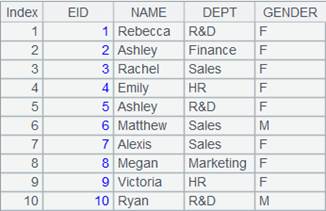
1 |
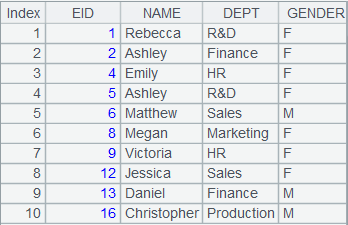
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
返回游标,数据内容如下:
|
|
3 |
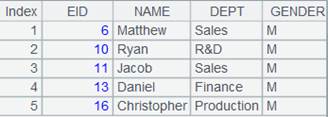
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
返回游标,数据内容如下:
|
|
4 |
=[A1,A2,A3] |
返回游标序列。 |
|
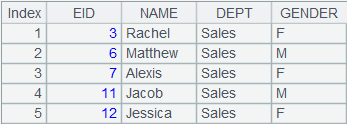
5 |
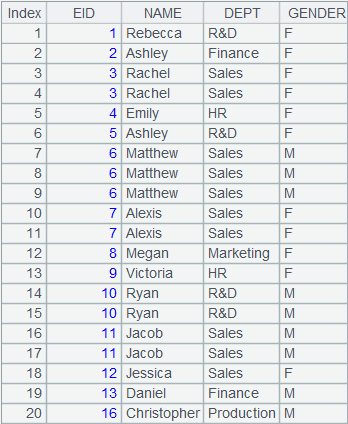
=A4.merge(EID) |
游标序列成员中的记录根据EID字段有序归并。 |
|
6 |
=A5.fetch() |
读取游标A5中的数据(数据量较大时建议分批读取):
|

使用@u选项,并集计算:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
返回游标,数据内容如下:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
返回游标,数据内容如下:
|
|
4 |
=[A1,A2,A3] |
返回游标序列。 |
|
5 |
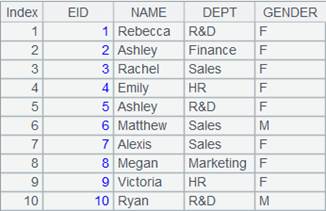
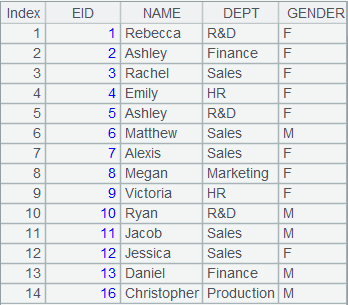
=A4.merge@u(EID) |
使用@u选项,游标序列成员中的记录根据EID字段有序归并,去掉重复的成员。 |
|
6 |
=A5.fetch() |
读取游标A5中的数据:
|

使用@i选项,交集计算:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
返回游标,数据内容如下:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
返回游标,数据内容如下:
|
|
4 |
=[A1,A2,A3] |
返回游标序列。 |
|
5 |
=A4.merge@i(EID) |
使用@i选项,交集运算,返回游标序列中共同成员组成的游标。 |
|
6 |
=A5.fetch() |
读取游标A5中的数据:
|
使用@d选项,差集计算:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
返回游标,数据内容如下:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
返回游标,数据内容如下:
|
|
4 |
=[A1,A2,A3] |
返回游标序列。 |
|
5 |
=A4.merge@d(EID) |
使用@d选项,差集运算,从游标A1中去掉游标A2、A3中的成员后形成的新游标。 |
|
6 |
=A5.fetch() |
读取游标A5中的数据:
|

使用@x选项,取出游标序列中不重复的成员组成新的序列:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
返回游标,数据内容如下:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
返回游标,数据内容如下:
|
|
4 |
=[A1,A2,A3] |
返回游标序列。 |
|
5 |
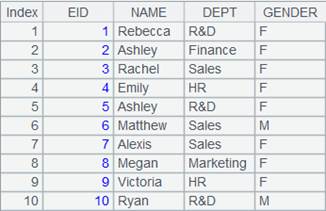
=A4.merge@x(EID) |
使用@x选项,差集运算,从取出游标序列中不重复的成员组成新的序列。 |
|
6 |
=A5.fetch() |
读取游标A5中的数据:
|
相关概念: