join()
本章介绍join()函数的多种用法。
join()
描述:
多序列连接。
join(Ai:Fi,xj,..;…)
备注:
将多个序列Ai按照关联字段/关联表达式xj和x1相等的关系连接,产生以Fi,…为字段的序表,Fi赋值为Ai对应成员,引用原排列Ai中的记录,xj全省略时用Ai的主键。某个xj 省略时该项条件不必匹配。
不管是多少个排列之间关联,都是和A1中的x1相等判断,因此是一表对多表的关系。
选项:
|
@f |
全连接,找不到匹配值时,则与null对应。 |
|
@1 |
左连接(注意:这里是数字1,不是字母l)。 |
|
@m |
假定所有Ai针对xj,…有序,则用归并法计算。 |
|
@p |
按位置连接,忽略xj参数。 |
|
@i |
仅用于过滤A1,忽略Fi参数,与@f@1互斥。 |
|
@d |
仅用于过滤A1,只保留找不到的,忽略Fi参数,与@f@1互斥。 |
参数:
|
Fi |
结果序表的字段名。 |
|
Ai |
被连接的序列或排列。 |
|
xj |
连接字段/表达式。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
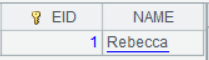
=demo.query("select top 3 EID,NAME from EMPLOYEE").keys(EID) |
|
|
2 |
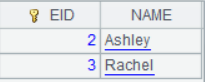
=demo.query("select top 3 EID,NAME from FAMILY").keys(EID) |
|
|
3 |
=join(A1:Employee,EID;A2:Familymembers,EID) |
常规连接,不匹配的项丢弃,每个字段值都是ref字段,指向原序表的一条记录。 |
|
4 |
=join@f(A1:Employee,EID;A2:Familymembers,EID) |
全连接,无匹配项的用null。 |
|
5 |
=join@1(A1:Employee,EID;A2:Familymembers,EID) |
左连接,以第一个序表为基准,无匹配项的用null。 |
|
6 |
=join@m(A1:Employee,EID;A2:Familymembers,EID) |
假定所有关联字段同序,用归并法计算;如果不同序则会出错。 |
|
7 |
=join@p(A1:Employee;A2:Familymembers) |
|
|
8 |
=join(A1:Employee;A2:Familymembers) |
|
|
9 |
=join(A1:Employee1;A2:Familymembers1) |
|
|
10 |
=join(A8:Employee2;A9:Familymembers2) |
|
|
11 |
=join@i(A1;A2) |
过滤A1,保留找到的。 |
|
12 |
=join@d(A1;A2) |
|






相关概念:
P.join()
描述:
序表与排列外键式连接。
语法:
P.join(C:.,T:K,x:F,…; …;…)
备注:
用序表/排列P的字段C,…匹配序表/排列T的键找到相应记录,在P上拼接T中的表达式x,作为字段F添加到P 上形成新序表。
K只能省略或者是#,K省略时默认为T的键,T有索引则使用索引,无索引则建立临时索引;K值为#时表示用T表记录的序号,即外键序号化处理,简单概括就是维表的主键是从1开始的自然数,也就是表记录所在行号,这种情况下就可以用键值直接按行号定位维表记录,从而加快与维表关联的速度,进一步提升性能。
如果F在P中已存在则改写现有字段。时间键值被省略时用now()。
选项:
|
@i |
匹配不上的外键删除整条记录,缺省将填成null。当参数x:F省略时,只做针对P的过滤操作。 |
|
@d |
删除匹配上外键的整条记录,只做针对P的过滤操作,此时省略参数x:F。 |
|
@m |
P对C有序,T对K有序,此时可用归并方式计算。 |
参数:
|
P |
序表/排列。 |
|
C |
P的外键,多个时以冒号隔开。 |
|
T |
|
|
K |
T的键。 |
|
x |
T的字段表达式,x可以是~和#,#表示记录在T中的序号,找不到填为null。 |
|
F |
表达式x的字段名。 |
返回值:
序表/排列
示例:
|
|
A |
|
|
1 |
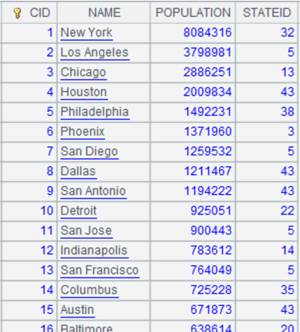
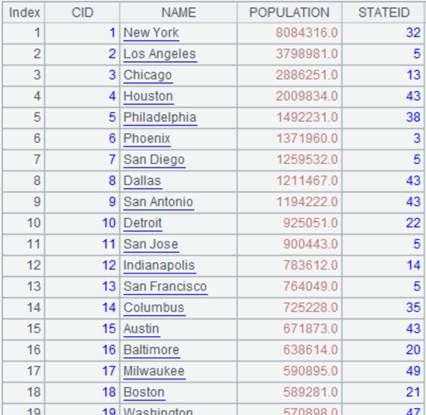
=connect("demo").query("SELECT * FROM CITIES") |
CITIES表数据内容:
|
|
2 |
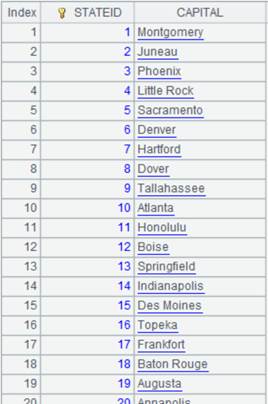
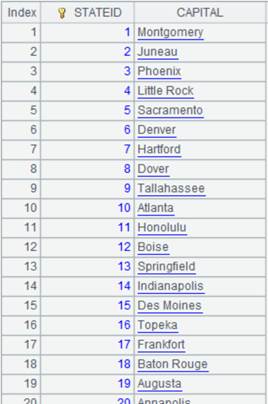
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID) |
STATECAPITAL表数据内容:
|
|
3 |
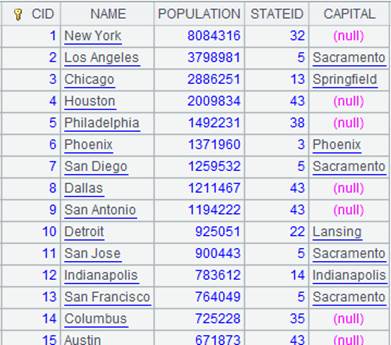
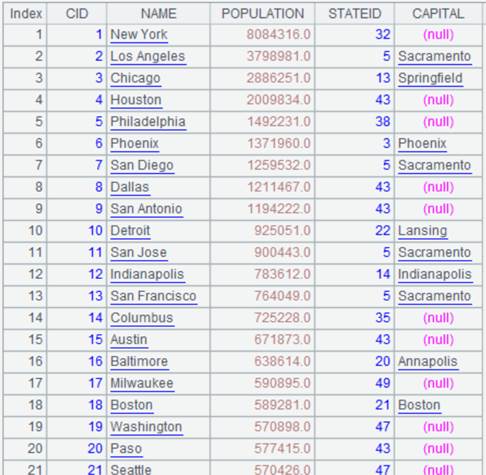
=A1.join(STATEID,A2,CAPITAL) |
将CITIES表与STATECAPITAL表外键式连接,参数K缺省为的STATECAPITAL键,即STATEID,并将STATECAPITAL表中的字段CAPITAL拼接到中成为新序表:
|
|
4 |
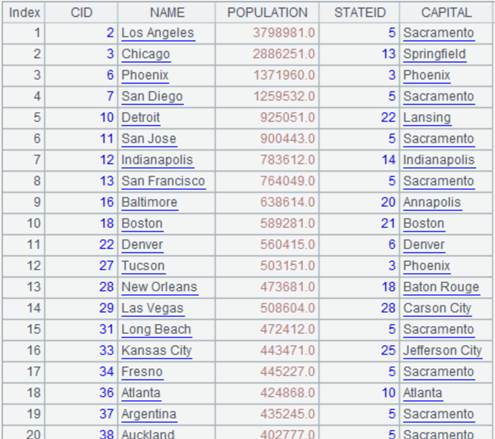
=A1.join(STATEID,A2:#,CAPITAL) |
可以看到STATEID字段是从1开始的自然数,与STATECAPITAL表的记录号是一致的,所以可以将参数K设为#,表示用STATECAPITAL表的序号,可提高计算效率,返回结果与A3相同。 |
|
5 |
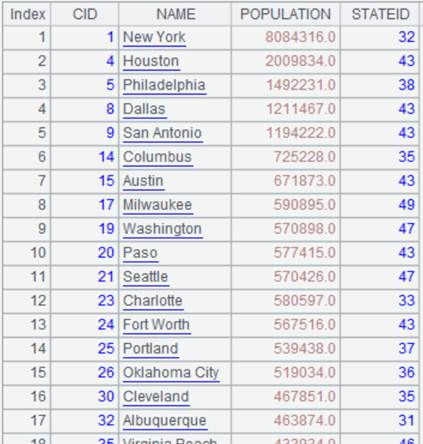
=A1.join@i(STATEID,A2,CAPITAL) |
使用@i选项,匹配不上的外键删除整条记录,缺省将填成null:
|
|
6 |
=A1.join@i(STATEID,A2) |
使用@i选项,当参数x:F省略时,只做针对CITIES表的过滤操作:
|
|
7 |
=A1.join@d(STATEID,A2) |
使用@d选项,当参数x:F省略时,删除匹配上外键的整条记录,只做针对CITIES表的过滤操作:
|
|
8 |
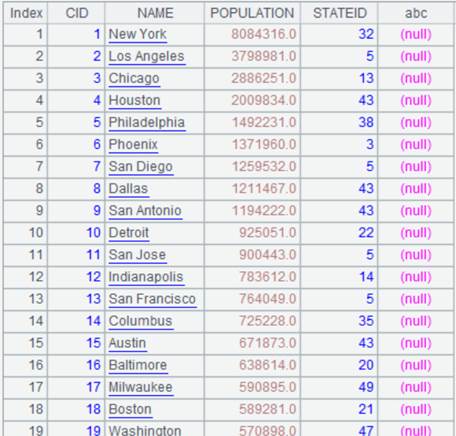
=A1.join(STATEID,A2,abc) |
x参数值在A2中找不到则填为nul:
|
|
9 |
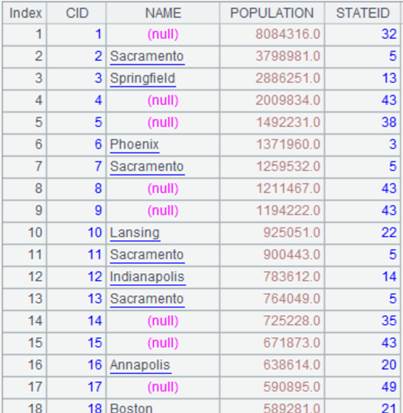
如果NAME在CITIES表中已存在则改写现有字段:
|

归并方式计算:
|
|
A |
|
|
1 |
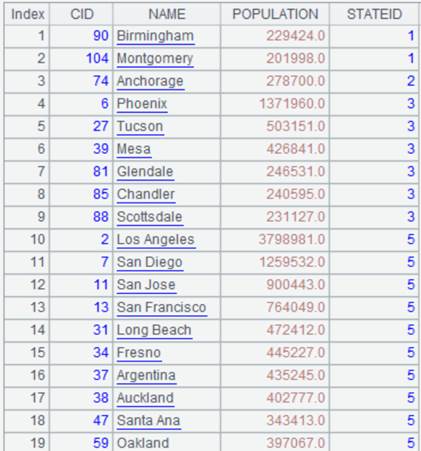
=connect("demo").query("SELECT * FROM CITIES").sort(STATEID) |
CITIES表数据内容:
|
|
2 |
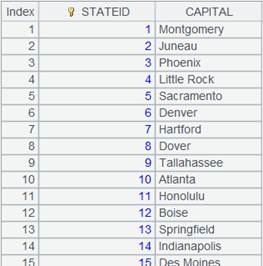
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID).sort(STATEID) |
STATECAPITAL表数据内容:
|
|
3 |
=A1.join@m(STATEID,A2,CAPITAL) |
CITIES对STATEID有序,STATECAPITAL对K有序,使用@m选项,此时可用归并方式计算:
|

ch.join()
描述:
管道附加与排列外键式连接动作后返回原管道。
语法:
ch.join(C:.,T:K,x:F,…; …;…)
备注:
管道ch附加计算,用ch的字段C,…匹配序表/排列T的键K,T计算表达式x后作为字段F的值拼接到ch上,返回原管道。
K可为#或者省略,K省略时默认为T的键;K值为#时表示用T表记录的序号,即外键序号化处理,简单概括就是维表的主键是从1开始的自然数,也就是表记录所在行号,这种情况下就可以用键值直接按行号定位维表记录,从而加快与维表关联的速度,进一步提升性能。
如果F在ch中已存在则改写现有字段。时间键值被省略时用now()。
该函数属于附加计算动作。
选项:
|
@i |
匹配不上的外键删除整条记录,缺省将填成null。 |
|
@o(Fi; C:.,T:K,x:F,…; …;…) |
原记录作为字段Fi生成新记录。 |
|
@d |
删除匹配上外键的整条记录,只做针对ch的过滤操作,此时省略参数x:F。 |
|
@m |
A对C有序,T对K有序,此时可用归并方式计算。 |
参数:
|
ch |
管道。 |
|
C |
管道ch的外键,多个时以冒号隔开。 |
|
T |
序表/排列。 |
|
K |
T的键。 |
|
x |
T的字段表达式。 |
|
F |
表达式x的字段名。 |
返回值:
管道
示例:
|
|
A |
B |
C |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
|
|
A1格返回游标。 |
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
|
|
A2格返回STATEID为键的序表:
|
|
3 |
=channel() |
=A3.join(STATEID,A2,CAPITAL) |
=B3.fetch() |
A3格中创建管道; B3格中给管道附加计算,将CITIES表与STATECAPITAL表外键式连接,参数K缺省为的STATECAPITAL键,即STATEID,将STATECAPITAL表中的字段CAPITAL拼接到管道中,返回到A3管道。 C3格中执行结果集函数,保留管道当前数据。 |
|
4 |
=channel() |
=A4.join(STATEID,A2:#,CAPITAL) |
=B4.fetch() |
A4格中创建管道; B4格中给管道附加计算,可以看到STATEID字段是从1开始的自然数,与STATECAPITAL表的记录号是一致的,所以可以将参数K设为#,表示用STATECAPITAL表的序号,可提高计算效率,返回到A4管道。 C4格中执行结果集函数,保留管道当前数据。 |
|
5 |
=channel() |
=A5.join@i(STATEID,A2,CAPITAL) |
=B5.fetch() |
A5格中创建管道; B5格中给管道附加计算,使用@i选项,匹配不上的外键删除整条记录,缺省将填成null,返回到A5管道。 C5格中执行结果集函数,保留管道当前数据。 |
|
6 |
=channel() |
=A6.join@d(STATEID,A2) |
=B6.fetch() |
A6格中创建管道; B6格中给管道附加计算,使用@d选项,当参数x:F省略时,删除匹配上外键的整条记录,只做针对CITIES表的过滤操作,返回到A6管道。 C6格中执行结果集函数,保留管道当前数据。 |
|
7 |
=channel() |
=A7.join@o(cities;STATEID,A2,CAPITAL) |
=B7.fetch() |
A7格中创建管道; B7格中给管道附加计算,使用@o选项,管道原记录作为字段cities生成新记录,返回到A7管道。 C7格中执行结果集函数,保留管道当前数据。 |
|
8 |
=A1.push(A3,A4,A5,A6,A7) |
|
|
将游标A1中的数据推送到管道A3、A4、A5、A6和A7,此时数据不会立即被推送到管道。 |
|
9 |
=A1.fetch() |
|
|
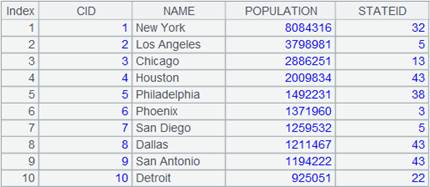
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。返回数据如下:
|
|
10 |
=A3.result() |
|
|
获取A3管道计算结果:
|
|
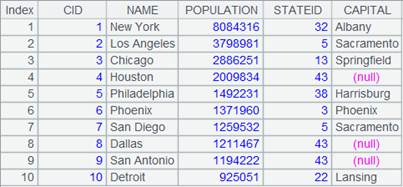
11 |
=A4.result() |
|
|
获取A4管道计算结果:
|
|
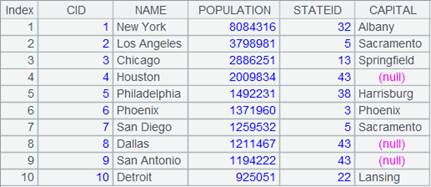
12 |
=A5.result() |
|
|
获取A5管道计算结果:
|
|
13 |
=A6.result() |
|
|
获取A6管道计算结果:
|
|
14 |
=A7.result() |
|
|
获取A7管道计算结果:
|



cs.join()
描述:
语法:
cs.join(C:.,T:K,x:F,…; …;…)
备注:
游标cs附加计算,用cs的字段C,…匹配T的键K,T计算表达式x后作为字段F的值拼接到cs上,返回原游标cs。支持多路游标。
K值可为#或者省略,K省略时默认为T的键;K值为#时表示用T表记录的序号,即外键序号化处理,简单概括就是维表的主键是从1开始的自然数,也就是表记录所在行号,这种情况下就可以用键值直接按行号定位维表记录,从而加快与维表关联的速度,进一步提升性能。
如果F在cs中已存在则改写现有字段。时间键值被省略时用now()。
该函数属于延迟计算函数。
选项:
|
@i |
匹配不上的外键删除整条记录,缺省将填成null。 |
|
@o(Fi; C:.,T:K,x:F,…; …;…) |
原记录作为字段Fi生成新记录。 |
|
@d |
删除匹配上外键的整条记录,只做针对cs的过滤操作,此时省略参数x:F。 |
|
@m |
cs对C有序,T对K有序,此时可用归并方式计算。 |
参数:
|
cs |
游标/多路游标。 |
|
C |
游标cs的外键,多个时以冒号隔开。 |
|
T |
序表/排列。 |
|
K |
T的键。 |
|
x |
T的字段表达式。 |
|
F |
x的字段名。 |
返回值:
游标
示例:
K省略时:
|
|
A |
|
|
1 |
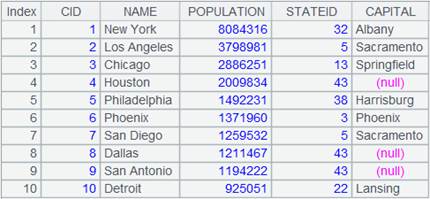
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
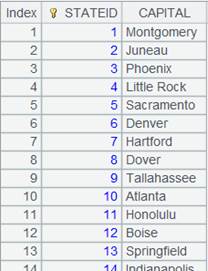
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
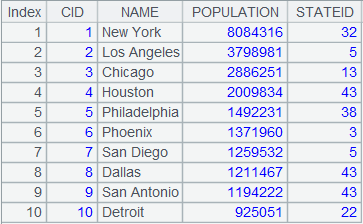
3 |
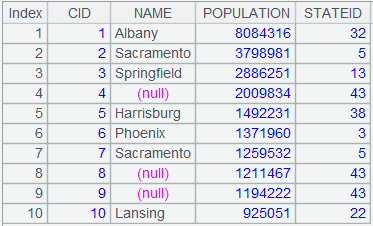
=A1.join(STATEID,A2,CAPITAL) |
游标A1附加计算,将CITIES表与STATECAPITAL表外键式连接,参数K缺省为的STATECAPITAL键,即STATEID,将STATECAPITAL表中的字段CAPITAL拼接到游标中,返回到A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据(数据量较大时建议分批读取):
|

K为#时:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join(STATEID,A2:#,CAPITAL) |
游标A1附加计算,可以看到STATEID字段是从1开始的自然数,与STATECAPITAL表的记录号是一致的,所以可以将参数K设为#,表示用STATECAPITAL表的序号,可提高计算效率,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|


使用@i选项:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join@i(STATEID,A2,CAPITAL) |
游标A1附加计算,使用@i选项,匹配不上的外键删除整条记录,缺省将填成null,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|

使用@i选项, 参数x:F省略时:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join@i(STATEID,A2) |
游标A1附加计算,使用@i选项,当参数x:F省略时,只做针对CITIES表的过滤操作,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|


使用@d选项:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join@d(STATEID,A2) |
游标A1附加计算,使用@d选项,当参数x:F省略时,删除匹配上外键的整条记录,只做针对CITIES表的过滤操作,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|

x参数值在T中找不到时:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join(STATEID,A2,abc) |
游标A1附加计算,x参数值在A2中找不到则填为null,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|


使用@o选项:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join@o(cities;STATEID,A2,CAPITAL) |
游标A1附加计算,使用@o选项,A1原记录作为字段cities生成新记录,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|

F在cs中已存在则改写现有字段:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,数据内容如下:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
返回以STATEID为键的序表:
|
|
3 |
=A1.join(STATEID,A2,CAPITAL:NAME) |
游标A1附加计算, NAME在CITIES表中已存在所以改写现有字段,返回A1游标。 |
|
4 |
=A1.fetch() |
读取游标A1执行A3计算后的数据:
|
相关概念:
cs.join ()
描述:
集群游标与排列外键式连接。
语法:
cs.join(C:.,T:K,x:F,…; …;…)
备注:
用游标cs中的字段C,…匹配T的键找到相应记录,在cs上拼接T中的表达式x,作为字段F添加到cs上,返回原游标。
K只能省略或者是#,K省略时默认为T的键;K值为#时表示用T表记录的序号,即外键序号化处理,简单概括就是维表的主键是从1开始的自然数,也就是表记录所在行号,这种情况下就可以用键值直接按行号定位维表记录,从而加快与维表关联的速度,进一步提升性能。
如果F在cs中已存在则改写现有字段。时间键值被省略时用now()。
支持多路游标。
选项:
|
@c |
集群表有分布时,计算也均不做跨机引用,认为引用记录总在本机。 |
参数:
|
cs |
游标/多路游标/集群游标。 |
|
C |
游标cs的外键,多个时以冒号隔开。 |
|
T |
集群内表。 |
|
K |
T的键。 |
|
x |
T的字段表达式。 |
|
F |
表达式x的字段名。 |
返回值:
原游标
示例:
|
|
A |
|
|
1 |
[192.168.18.143:8281] |
|
|
2 |
=file("emp_1.ctx":[2], A1) |
|
|
3 |
=A2.open() |
|
|
4 |
=A3.cursor() |
集群游标。 |
|
5 |
[192.168.0.110:8281] |
|
|
6 |
=file("PERFORMANCE.ctx":[1],A5) |
|
|
7 |
=A6.open() |
|
|
8 |
=A7.cursor() |
|
|
9 |
=A8.memory() |
集群内表。 |
|
10 |
=A4.join(EID,A9:EMPLOYEEID, BONUS*12:total) |
用集群游标中的字段EID匹配集群内表中的键EMPLOYEEID,并将集群内表中的表达式BONUS*12作为字段total 拼接到集群游标中,结果返回原游标。 |
|
11 |
取游标中的数据:
|

T.join()
描述:
虚表定义与排列外键式连接操作后返回新虚表。
T.join(C:.,A:K,x:F,…; …;…)
备注:
虚表定义计算,用T的字段C,…匹配排列A的键K,A计算表达式x后作为字段F的值拼接到T上,返回新虚表。
K可为#或者省略,K省略时默认为A的键;K值为#时表示用A表记录的序号,即外键序号化处理,简单概括就是维表的主键是从1开始的自然数,也就是表记录所在行号,这种情况下就可以用键值直接按行号定位维表记录,从而加快与维表关联的速度,进一步提升性能。
如果F在T中已存在则改写现有字段。时间键值被省略时用now()。
选项:
|
@i |
匹配不上的外键删除整条记录,缺省将填成null。 |
|
@o(Fi; C:.,T:K,x:F,…; …;…) |
原记录作为字段Fi生成新记录。 |
|
@d |
删除匹配上外键的整条记录,只做针对T的过滤操作,此时省略参数x:F。 |
|
@m |
T对C有序,A对K有序,此时可用归并方式计算。 |
参数:
|
T |
虚表。 |
|
C |
虚表T的外键,多个时以冒号隔开。 |
|
A |
序表/排列。 |
|
K |
A的键。 |
|
x |
A的字段表达式。 |
|
F |
表达式x的字段名。 |
返回值:
虚表
示例:
|
|
A |
B |
|
|
1 |
|
组表cities.ctx数据内容:
|
|
|
2 |
=pseudo(A1) |
|
由组表产生虚表。 |
|
3 |
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID) |
|
STATECAPITAL表数据内容:
|
|
4 |
=A2.join(STATEID,A3,CAPITAL) |
=A4.cursor().fetch() |
执行A4格中的表达式,虚表A2定义计算,将虚表与A3中STATECAPITAL表外键式连接,参数K缺省为的STATECAPITAL键,即STATEID,并将STATECAPITAL表中的字段CAPITAL拼接到中成为新虚表。 执行B4格中的表达式,读取A4虚表中的数据,此时A2虚表执行A4中定义的计算操作,返回内容如下内容如下:
|
|
5 |
=A2.join(STATEID,A3:#,CAPITAL) |
=A5.import() |
执行A5格中的表达式,虚表A2定义计算,可以看到STATEID字段是从1开始的自然数,与STATECAPITAL表的记录号是一致的,所以可以将参数K设为#,表示用STATECAPITAL表的序号,可提高计算效率。执行B5格中的表达式,返回结果与B4相同。 |
|
6 |
=A2.join@i(STATEID,A3,CAPITAL) |
=A6.import() |
使用@i选项,匹配不上的外键删除整条记录,缺省将填成null,执行B6格返回结果如下:
|
|
7 |
=A2.join@i(STATEID,A3) |
=A7.import() |
使用@i选项,当参数x:F省略时,只做针对虚表的过滤操作,执行B7格返回结果如下:
|
|
8 |
=A2.join@d(STATEID,A3) |
=A8.import() |
使用@d选项,当参数x:F省略时,删除匹配上外键的整条记录,只做针对虚表的过滤操作,执行B8格返回结果如下:
|
|
9 |
=A2.join(STATEID,A3,abc) |
=A9.import() |
x参数值在A2中找不到则填为nul,执行B9格返回结果如下:
|
|
10 |
=A2.join@o(cities;STATEID,A3,CAPITAL) |
=A10.import() |
使用@o选项,原记录整个作为字段cities生成新记录,此时相当于参数x为~ ,执行B10格返回结果如下:
|
|
11 |
=A2.join(STATEID,A3,CAPITAL:NAME) |
=A11.import() |
如果NAME在虚表中已存在则改写现有字段,执行B11格返回结果如下:
|