iselect()
本章节介绍iselect()函数的用法。
f.iselect()
描述:
根据有序文件创建游标返回。
语法:
|
f.iselect(A,x;Fi,…;s) |
|
f.iselect(a:b,x;Fi,…;s) |
备注:
文件f对字段/字段表达式x有序,从f中筛选出x在序列A或者区间[a:b]中的记录,返回成游标。
参数:
|
f |
文件对象。 |
|
A |
单值或序列。 |
|
[a:b] |
x的取值区间,a省略表示从头开始取,b省略表示取到结尾。 |
|
x |
字段名/表达式,用#时表示用序号定位。 |
|
Fi |
读出的字段,缺省读出所有。 |
|
s |
自选分隔符,缺省默认分隔符是tab。省略参数s时,s前边的分号可以省略。 |
选项:
|
@t |
f中第一行记录作为字段名,不使用本选项时默认使用_1,_2,…作为字段名。 |
|
@b |
读取由export方式写出的二进制文件,支持参数A、x和Fi,不支持参数s,忽略选项@t@c@r@q@o@k@d@v@n。记录数少的文件在分段读取时可能会有空段。 |
|
@c |
s缺省时用逗号分隔。 |
|
@r |
x不唯一,缺省认为x在f中唯一。 |
|
@q |
如果字段串外有引号则先剥离,包括标题部分,并处理转义。 |
|
@o |
用引号作为转义符。 |
|
@k |
保留数据项两端的空白符,缺省将自动删除两端空白符。 |
|
@e |
Fi在文件中不存在时将生成null,缺省将报错。 |
|
@d |
行内有数据不匹配类型和格式时删除该行,此时会按type检查类型。 |
|
@v |
@d@n检查出错时抛出违例,中断程序,输出出错行的内容。 |
|
@n |
列数和第一行不匹配也作为错误处理,不匹配的记录行将被抛弃。 |
返回值:
游标
示例:
|
|
A |
|
|
1 |
=to(1:10) |
|
|
2 |
=file("E:/files/employee.txt").iselect(A1,#1;;"|") |
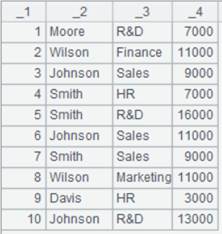
employee.txt内容如下:
第一列有序且以"|"分隔。省略指定字段,读出文件中第一列值与A1序列中相同的所有字段,返回成游标。 |
|
3 |
=A2.fetch() |
|
|
4 |
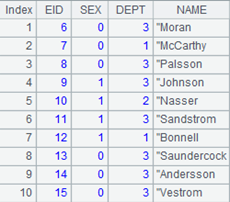
=file("E:/files/employee1.txt").iselect@t(A1,EID;EID,SALARY) |
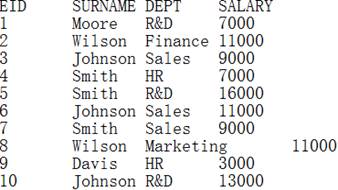
employee1.txt内容如下:
读出文件中EID与A1序列中相同的EID和SALARY字段,返回成游标。 |
|
5 |
=A4.fetch() |
|
|
6 |
=file("E:/files/employee2.txt").iselect@tc(A1,EID) |
employee2.txt内容如下:
文件内容以逗号分隔。 |
|
7 |
=A6.fetch() |
|
|
8 |
=file("E:/files/employee3.btx").iselect@b(A1,EID) |
读取f.export@z(A,x:F,…;s)导出的集文件employee3.btx,取EID为1-10的记录数据。 |
|
9 |
=A8.fetch() |
|
|
10 |
=file("E:/files/employee1.txt").iselect@t(1:10,EID;EID,SALARY) |
读取EID区间值为1到10的记录,记录字段为EID和SALARY。 |
|
11 |
=A10.fetch() |
结果和A5一样。 |
|
12 |
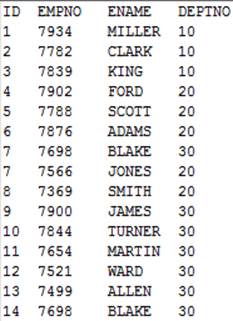
=file("D:/Sale2.txt").iselect@tr(7,ID;ID,ENAME) |
Sale2.txt内容如下,读取出ID为7的所有记录:
|
|
13 |
=A12.fetch() |
|
|
14 |
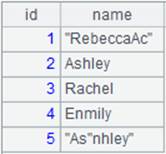
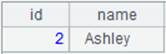
=file("D:/Department1.txt").iselect@t(1:5,id;id,name;"|").fetch() |
|
|
15 |
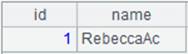
=file("D:/Department1.txt").iselect@tk(2,id;id,name;"|").fetch() |
使用@k选项保留数据项两端的空白符。 |
|
16 |
=file("D:/Department1.txt").iselect@tq(1,id;id,name;"|").fetch() |
剥离字符串外的引号。 |
|
17 |
=file("D:/Department1.txt").iselect@tqo(5,id;id,name;"|").fetch() |
|
|
18 |
=file("D:/emp1.txt").iselect@et(2:5,EID;EID,SALARY,SEX).fetch() |
emp1.txt数据内容如下:
SEX在txt中不存在,使用@e选项使其返回空:
|
|
19 |
=file("D:/emp1.txt").iselect@tn(7:10,EID;EID,NAME,SALARY).fetch() |
EID为10的列与第一列列数不一致,故抛弃:
|
|
20 |
=file("D:/emp2.txt ").iselect@t(A1,EID-5;;",").fetch() |
选出1-10的,x表达式使EID在5-15的数据都符合。
|
|
21 |
=file("D:/emp2.txt ").iselect@t(1:10,EID-5;;",").fetch() |
同理,使用[a:b]区间结果同上:
|