
id()
本章介绍id()函数的用法。
A.id()
从序列中获取distinct值。
语法:
A.id(xi,…;n)
备注:
取前n个xi。。。的distinct值,如果x的distinct值小于n,则返回所有;然后将distinct值生成新的序列,只有一个xi时返回成一个序列。
参数:
|
xi |
distinct 表达式,可省略,x省略为~。 |
|
n |
前n个xi…的distinct值,可省略,省略返回所有。 |
选项:
|
@o |
不排序,仅去掉相邻的重复成员。 |
|
@u |
结果集不再按x排序;与@o互斥。 |
|
@h |
用于分段有序的数据,可提高计算效率。 |
|
@0 |
丢弃x的计算结果为空的成员。 |
|
@m |
数据量大的复杂运算中,并行计算提升性能,计算次序不确定,与@o互斥。 |
|
@n |
只有一个xi且是自然数,可用位置判断。 |
|
@b |
只有一个xi且是自然数,使用字节的位来判断以减少存储占用。 |
返回值:
序列
示例:
|
|
A |
|
|
1 |
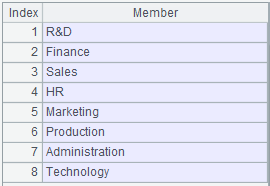
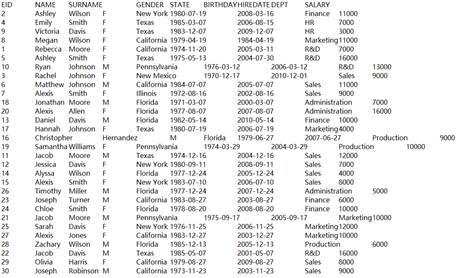
=demo.query("select * from EMPLOYEE") |
|
|
2 |
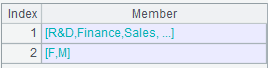
=A1.id(DEPT) |
升序排序。
|
|
3 |
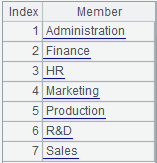
=A1.id@o(DEPT) |
不排序。 |
|
4 |
=A1.id([DEPT,GENDER]) |
按DEPT & GENDER组合排序后取唯一值 。 |
|
5 |
=["a","b","c","a"].id() |
x省略,表示序列成员本身,返回["a","b","c"]。 |
|
6 |
=A1.id@u([DEPT,GENDER]) |
结果集不按x排序。 |
|
7 |
=A1.id(DEPT,GENDER) |
N省略时,返回所有。
|
|
8 |
=A1.id(DEPT,GENDER;4) |
返回前4个,GENDER 的distinct值小于4,返回所有:
|
|
9 |
=file("D:/emp10.txt").import@t() |
数据文件emp10.txt中,每10条数据根据DEPT进行了一次排序:
|
|
10 |
=A9.id@h(DEPT) |
A19是以DEPT分段有序的数据,使用@h选项提高分组效率:
|




|
|
A |
|
|
1 |
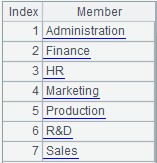
=demo.query("select * from DEPT") |
|
|
2 |
=A1.id(FATHER) |
返回内容:[null,1,2,11,12]。 |
|
3 |
=A1.id@0(FATHER) |
ch.id()
描述:
获取管道中字段不同值形成的管道。
语法:
ch.id(xi,…;n)
备注:
获取管道ch中每个字段xi的不同值形成的多个序列的序列构成的管道,每个xi找到n个后不再找,只有一个xi时返回成一个序列构成的管道。该函数为结果集函数。
参数:
|
ch |
管道。 |
|
xi |
表达式,多个表达式时用逗号隔开。 |
|
n |
整数,不可省略。 |
返回值:
示例:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,SALARY from EMPLOYEE") |
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=channel() |
创建管道。 |
|
4 |
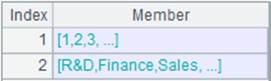
=A2.id(#1,DEPT;10) |
|
|
5 |
=A3.id(DEPT;5) |
|
|
6 |
=A1.push(A2,A3) |
将游标A1中的数据推进管道A2和A3。 |
|
7 |
=A1.fetch() |
|
|
8 |
=A2.result() |
|
|
9 |
=A3.result() |
|

cs.id()
描述:
获取游标中字段的不同值形成的序列。
语法:
cs.id(xi,…;n)
备注:
获取游标cs中每个字段xi的不同值形成的多个序列的序列,每个xi找到n个后不再找,只有一个xi时返回成一个序列。
参数:
|
cs |
游标。 |
|
xi |
表达式,多个表达式时用逗号隔开。 |
|
n |
整数,可省略,省略时返回所有。 |
选项:
|
@o |
不排序,仅去掉相邻的重复成员,要求数据对x有序。 |
|
@u |
结果集不再按x排序;与@o互斥。 |
|
@h |
用于分段有序的数据,可提高计算效率。 |
|
@0 |
丢弃x的计算结果为空的成员。 |
|
@n |
只有一个xi且是自然数,可用位置判断。 |
|
@b |
只有一个xi且是自然数,使用字节的位来判断以减少存储占用。 |
返回值:
序列
示例:
|
|
A |
|
|
1 |
=demo.cursor("select * from EMPLOYEE" ) |
|
|
2 |
=A1.id(#1,DEPT;5) |
|
|
3 |
=demo.cursor("select * from EMPLOYEE" ) |
|
|
4 |
=A3.id(DEPT;5) |
|
|
5 |
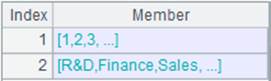
=demo.cursor("select * from EMPLOYEE" ).sortx(DEPT).id@o(DEPT) |
不排序,仅去掉相邻的重复成员:
|
|
6 |
=demo.cursor("select * from EMPLOYEE" ).id@u(DEPT) |
结果集不再按x排序:
|

|
|
A |
|
|
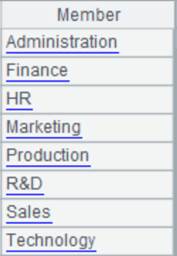
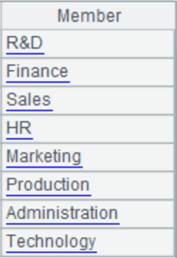
1 |
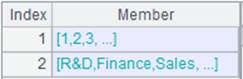
=demo.cursor("select * from DEPT") |
DEPT表内容如下:
|
|
2 |
=A1.id(FATHER) |
返回内容:[null,1,2,11,12]。 |
|
3 |
=A1.reset() |
|
|
4 |
=A1.id@0(FATHER) |
返回内容:[1,2,11,12]。 |
