
groupc()
本章节介绍groupc()函数的用法。
A.groupc( g ; v )
描述:
对序列的序列执行行列转换计算。
语法:
A.groupc(g;v)
备注:
对序列A的成员序列执行行列转换计算。默认为行转列。
A是由序列组成的序列,g和v是由A成员序列中的部分成员组成的序列,引用A成员的成员时用~(i)或~i形式表示。
将A成员根据g分组,然后将v对应分布到每组序列中,返回序列组成的序列。
参数g、v中只有一个成员时可以写成单值的形式。
参数:
|
A |
由序列组成的序列。 |
|
g |
由A成员序列中的部分成员组成的序列。 |
|
v |
由A成员序列中的部分成员组成的序列。 |
选项:
|
@r(g;v;k) |
列转行。k为整数,v中每k个成员作为一组与g组成新的序列,返回这些序列组成的序列。 |
返回值:
序列组成的序列
示例:
|
|
A |
|
|
1 |
=file("t3.txt").cursor@w().fetch() |
返回由序列组成的序列:
|
|
2 |
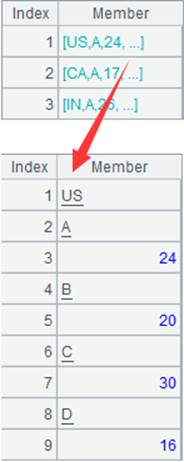
=A1.groupc(~(1);[(~2),(~3)]) |
对A1的成员序列执行行转列计算,先将A1按照成员的第1个成员分组,然后将成员序列中的第2、3个成员对应分布到每个组序列中,返回结果如下:
|
|
3 |
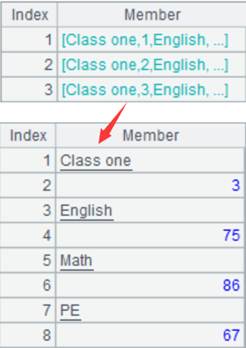
=A2.groupc@r(~1;[~2,~3,~4,~5,~6,~7];2) |
使用@r选项,对A2执行列转行计算,A2成员序列中的第2到第7个成员按照次序每两个作为一组,与A2成员序列中的第1个成员组成一个新的成员序列,返回结果如下:
|
|
4 |
=A2.groupc@r(~1;~.to(2,);2) |
使用@r选项,对A2执行列转行计算,A2成员序列中的第2到最后一个成员按照次序每两个作为一组,与A2成员序列中的第1个成员组成一个新的序列,返回结果同A1。 |

g中包含多个成员时:
|
|
A |
|
|
1 |
=connect("demo").query("select top 9 * from scores").array@b() |
返回由序列组成的序列:
|
|
2 |
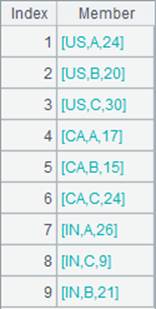
=A1.groupc([~1,~2];[~3,~4]) |
对A1的成员序列执行行转列计算,先将A1按照成员的第1、2个成员分组,然后将成员序列中的第3、4个成员对应分布到每个组序列中,返回结果如下:
|
|
3 |
=A2.groupc@r([~1,~2];~.to(3,);2) |
使用@r选项,对A2执行列转行计算,A2成员序列中的第3到最后一个成员按照次序每两个作为一组,与A2成员序列中的第1、2个成员组成一个新的序列,返回结果同A1。 |

相关概念:
P.groupc( g:G , … ; F ,…; N ,… )
描述:
对序表执行多列的行列转换计算。
语法:
P.groupc(g:G,…;F,…;N,…)
备注:
对序表/排列P执行多列的行列转换计算,默认为行转列。
P根据字段/表达式g分组,G为g列的列名,N,…为新的列字段名称,将每个G组中的字段F,…的值根据新列N,…依次对照分布,忽略多余的N。
参数:
|
P |
序表/排列。 |
|
g |
分组字段/表达式。 |
|
G |
结果集中的字段名,缺省为g。 |
|
F |
P中的字段名称,缺省使用P中除g,…以外的所有字段。 |
|
N |
新的列字段名称,缺省使用序号表示列名。 |
选项:
|
@r |
列转行。 将F,…字段值依次分布到新的列N,…下,丢弃所有N都为空的记录行。 |
返回值:
序表
示例:
行转列:
|
|
A |
|
|
1 |
=file("t1.txt").import@t() |
返回序表内容如下:
|
|
2 |
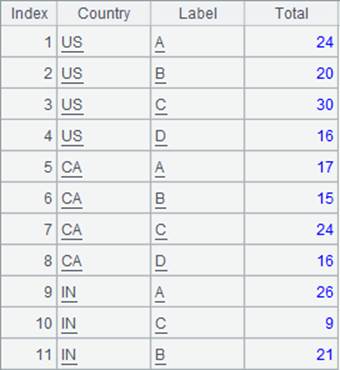
=A1.groupc(Country:COUNTRY;Label,Total;L1,T1,L2,T2,L3,T3,L4,T4,L5,T5) |
A1序表根据字段Country分组,并定义列名为:COUNTRY。 然后将每组中的Label,Total字段值根据新列L1,T1,L2,T2,L3,T3,L4,T4,L5,T5依次对照分布,返回结果如下:
L5,T5为多余的列,所以忽略。 |
|
3 |
=A1.groupc(Country;Label,Total;) |
参数N,…缺省使用序号,参数G缺省使用g,返回结果如下:
|
|
4 |
=A1.groupc(Country;;) |
参数F,…缺省为A1中除Country以外的所有字段,返回结果同A3。 |
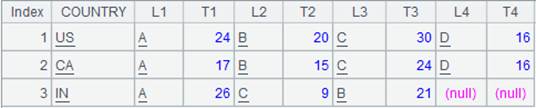

列转行:
|
|
A |
|
|
1 |
=file("t2.txt").import@t() |
返回序表内容如下:
|
|
2 |
=A1.groupc@r(Country;Label1,Total1,Label2,Total2,Label3,Total3,Label4,Total4;Label,Total) |
使用@r选项,执行列转行计算,A1根据Country分组,将每组中的Label1,Total1,Label2,Total2,Label3,Total3,Label4,Total4字段值根据新列Label,Total依次对照分布,返回结果如下:
|
|
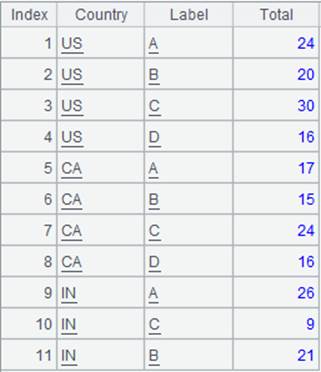
3 |
=A1.groupc@r(Country;;Label,Total) |
参数F,…缺省为A1中除Country以外的所有字段,返回结果同A2。 |

相关概念: