
create()
本章介绍create()函数的多种用法。
create()
描述:
创建空序表。
语法:
create(Fi,…)
备注:
产生以Fi,…为字段的空序表 。
参数:
|
Fi |
字段名。 |
返回值:
空序表
示例:
|
|
A |
|
|
1 |
=create(id,name,gender) |
|
create( # F i ,… )
描述:
创建含有键的空序表。
语法:
create(#Fi,…)
备注:
产生以Fi,…为字段的空序表,带有#的字段名被认为是键,暂不能直接生成时间键。
参数:
|
Fi |
字段名。 |
返回值:
空序表
示例:
|
|
A |
|
|
1 |
=create(#id,#name,gender) |
id ,name 两个字段为键:
|
f.create( C ,…; x;b )
描述:
用文件创建组表。
f.create(C,…;x;b)
备注:
用组表文件f创建组表,C为组表的列,C前带#表示维,维及其前面的所有字段必须有序。当f是文件组时生成复组表,x是分表表达式。
参数:
|
f |
组表文件对象/文件组对象。 |
|
C |
组表的列。 |
|
x |
分表表达式,计算结果为对应分表号的整数。 |
|
b |
区块大小,单位为字节,缺省使用选项中设置的组表区块大小的值;第三方应用程序中集成使用时,缺省为raqsoftConfig.xml文件中配置的blockSize的值。 |
选项:
|
@u |
不压缩,缺省将压缩。 |
|
@r |
生成行存文件,缺省用列存,行存模式的组表不支持使用多路游标。 |
|
@y |
文件已存在时强制重新创建,缺省中断计算。 |
|
@p |
按第一个字段作为分段键。 |
|
@v |
列存方式下,数据维护时对比列是否纯,并保存数据类型。 |
|
@t |
维构成键,且最后一个键是时间键,此时不能再有附表;支持复组表。 |
|
@d |
用于复组表,键字段后的第一个字段认定为更新标识字段,字段值有三种:null表示新增,true表示删除;false表示修改。 程序可以根据更新标识字段值读取复组表数据。 |
返回值:
组表/文件组
示例:
|
|
A |
|
|
1 |
=file("employee1.ctx") |
生成组表文件employee1.ctx。 |
|
2 |
=A1.create(#EID,NAME,GENDER) |
创建组表employee1.ctx的基表,EID、NAME、GENDER为基表的列名,其中EID表示维。 |
|
3 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee where GENDER='M' ").sortx(EID) |
|
|
4 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee where GENDER='F' ").sortx(EID) |
|
|
5 |
=[A3,A4].mcursor() |
返回多路游标。 |
|
6 |
=file("emp.ctx":[1,2]) |
生成文件组,包含的文件分别为1.emp.ctx、2.emp.ctx。 |
|
7 |
=A6.create@y(#EID,NAME,GENDER,SALARY;if(GENDER=="F",1,2)) |
创建复组表,if(GENDER=="F",1,2)为分表表达式,使用@y选项,文件已存在时强制重新创建。 |
|
8 |
=A7.append@i(A5) |
将多路游标A5中的数据追加到复组表A7中,A5的每一路与A7的分表一一对应。 |
|
9 |
=file("1.emp.ctx").open().cursor().fetch() |
查看分表1.emp.ctx中的数据。 |
|
10 |
=file("2.emp.ctx").open().cursor().fetch() |
查看分表2.emp.ctx中的数据。 |
第一个字段作为分段键:
|
|
A |
|
|
1 |
=file("CITES.ctx") |
生成组表文件CITES.ctx。 |
|
2 |
=A1.create@p(STATEID,#CID,NAME,POPULATION) |
创建组表CITES.ctx的基表,使用@p选项将第一个字段STATEID作为分段键;选项缺省则将维字段CID作为缺省字段。 |
设置时间键:
|
|
A |
|
|
1 |
=file("transaction.ctx") |
|
|
2 |
=A1.create@yt(#UID,#Time,Change,Amount) |
创建组表的基表,使用@t选项,UID为基本键,Time为时间键。 |
|
3 |
=file("transaction.txt").cursor@t().sortx(UID,Time) |
返回对UID,Time字段有序的游标。 |
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到基表中。 |
|
5 |
=A2.import() |
获取基表中的数据:
|

使用更新标识字段:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME,GENDER from employee") |
|
|
2 |
=A1.derive(null:Defiled) |
|
|
3 |
=A2.new(EID,Defiled,NAME,GENDER) |
返回游标,内容如下:
|
|
4 |
=file("ed.ctx":[1,2]) |
文件组1.ed.ctx、2.ed.ctx。 |
|
5 |
=A4.create@yd(#EID,Defiled,NAME,GENDER;if(GENDER=="F",1,2)) |
创建复组表,EID为键,使用@d选项,将Defiled作为更新标识字段,GENDER值为F的记录分到1.ed.ctx中,其余分到2.ed.ctx中。 |
|
6 |
=A5.append@ix(A3) |
将A1游标中的数据追加到复组表中。 |
|
7 |
=create(EID,Defiled,NAME,GENDER).record([1,true,,2,false, "ABC","F"]).cursor() |
返回游标,内容如下:
|
|
8 |
=file("ed.ctx":[3]) |
|
|
9 |
=A8.create@yd(#EID,Defiled,NAME,GENDER;3) |
增加分表3.ed.ctx。 |
|
10 |
=A9.append@i(A7) |
将A7游标中的数据追加到分表3.ed.ctx中。 |
|
11 |
=file("ed.ctx":[1,2,3]) |
|
|
12 |
=A11.open() |
打开复组表。 |
|
13 |
=A12.cursor@w() |
将复组表返回成游标,使用@w选项,处理更新标记,即:删除EID为1的记录,修改EID为2的记录。 |
|
14 |
=A13.fetch() |
查看A13游标中的数据:
可以看到复组表中EID为1的记录没有被读出,且EID 为2的记录NAME值已更新。 |



P.create()
描述:
复制排列P的数据结构,以此产生一个新的空序表。
语法:
P.create()
备注:
如果P有键,则同时复制键。
参数:
|
P |
排列。 |
返回值:
空序表
示例:
Ø 由排列产生
|
|
A |
|
|
1 |
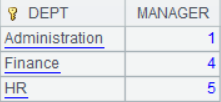
=demo.query("select top 1 * from DEPARTMENT") |
|
|
2 |
=A1.to() |
生成排列。 |
|
3 |
=A2.create() |
产生一个空序表,与A2数据结构一致。 |
Ø 复制键
|
|
A |
|
|
1 |
=demo.query("select top 1 * from DEPARTMENT ") |
|
|
2 |
=A1.keys(DEPT) |
|
|
3 |
=A1.to() |
生成排列。 |
|
4 |
=A3.create() |
产生一个空序表,与A3的数据结构一致,且同时复制了键。 |

T.create()
描述:
复制序表T的数据结构,以此产生一个新的空序表。
语法:
T.create()
备注:
如果T有键,则同时复制键。
参数:
|
T |
序表。 |
返回值:
新空序表
示例:
Ø 由普通序表产生
|
|
A |
|
|
1 |
=demo.query("select top 1 * from DEPARTMENT") |
|
|
2 |
=A1.create() |
产生一个空序表,与A1数据结构一致。 |

Ø 复制键
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT ") |
|
|
2 |
=A1.keys(DEPT) |
|
|
3 |
=A1.create() |
产生一个空序表,与A1序表的数据结构一致,且同时复制了键。 |
T.create(f:b;x)
描述:
用已存在的组表的数据结构创建新的组表文件。
语法:
T.create(f:b;x)
备注:
用组表T的数据结构创建新的组表文件f,包括T的附表。f是文件组时候创建成复组表。
参数:
|
T |
组表。 |
|
f |
组表文件或文件组。 |
|
b |
区块大小,单位为字节,缺省使用选项中设置的组表区块大小的值;第三方应用程序中集成使用时,缺省为raqsoftConfig.xml文件中配置的blockSize的值。 |
|
x |
整数,分表表达式。 |
选项:
|
@u |
不压缩,缺省将压缩。 |
|
@r |
生成行存文件,缺省用列存,行存模式的组表不支持使用多路游标。行存文件不压缩。 |
|
@y |
文件已存在时强制重新创建,缺省中断计算。 |
返回值:
组表
|
|
A |
|
|
1 |
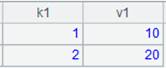
=create(k1,v1).record([1,10,2,20]).cursor() |
返回游标,数据内容如下:
|
|
2 |
=create(k1,k2,v2).record([1,11,111,2,22,222]).cursor() |
返回游标,数据内容如下:
|
|
3 |
=file("ctb.ctx").open() |
打开组表文件,该组表中含有名为table2的附表。 |
|
4 |
=A3.create@y(file("ctbCp.ctx")) |
根据组表ctb.ctx的数据结构创建新的组表文件ctbCp.ctx,同时创建附表。 使用@y选项,ctbCp.ctx文件存在时强制重新创建。 |
|
5 |
=A4.append@i(A1) |
将A1游标中的数据追加到组表ctbCp.ctx的基表中。 |
|
6 |
=A4.attach(table2) |
打开组表的附表table2。 |
|
7 |
=A6.append@i(A2) |
将A2游标中的数据追加到ctbCp.ctx的附表table2中。 |

使用@u选项,生成的组表文件不压缩:
|
|
A |
|
|
1 |
=file("em.ctx").open() |
打开组表文件em.ctx。 |
|
2 |
=A1.create@yu(file("ctbCp2.ctx")) |
用已存在的组表文件em.ctx创建不压缩的组表文件ctbCp2.ctx。 |
|
3 |
=file("ctbCp2.ctx").structure() |
查看ctbCp2.ctx组表文件结构,zip值为false表示不压缩:
|
使用@r选项,生成行存文件:
|
|
A |
|
|
1 |
=file("em.ctx").open() |
打开组表文件em.ctx。 |
|
2 |
=A1.create@yr(file("ctbCp3.ctx")) |
用已存在的组表文件em.ctx创建行存组表文件ctbCp3.ctx。 |
|
3 |
=file("ctbCp3.ctx").structure() |
查看ctbCp3.ctx组表文件结构,row值为true表示行存文件:
|

r.create ()
描述:
复制记录r的数据结构,以此产生一个新的空序表。
语法:
r.create()
备注:
如果r有键,则同时复制键。
参数:
|
r |
记录。 |
返回值:
空序表
示例:
Ø 由普通记录产生
|
|
A |
|
|
1 |
=demo.query("select top 1 * from DEPARTMENT") |
|
|
2 |
=A1(1).create() |
产生一个空序表,与A1(1)记录的数据结构一致:
|

Ø 复制键
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT ") |
|
|
2 |
=A1.keys(DEPT) |
|
|
3 |
=A1(1).create() |
产生一个空序表,与A1(1)记录的数据结构一致,且同时复制了键:
|