
导入历史数据
本小节主要介绍数据来源类型、检测变量类型、导出数据质量报告以及导出数据探索报告。
数据来源类型
在菜单栏中点击文件 - 新建模型或者直接在工具栏中点击![]() 按钮,弹出导入数据窗口,数据来源类型有两种,分别为本地数据文件、数据库:
按钮,弹出导入数据窗口,数据来源类型有两种,分别为本地数据文件、数据库:
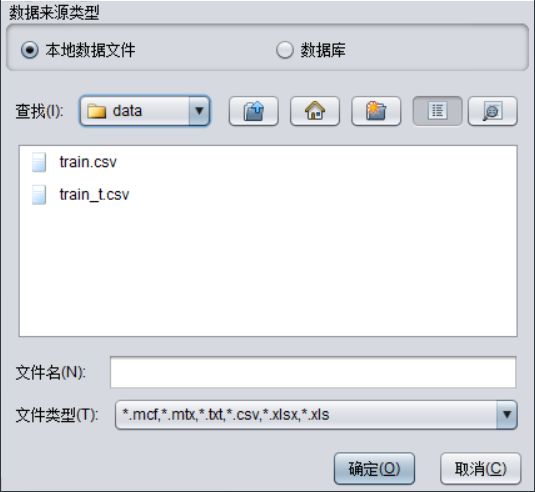
选择【本地数据文件】如上图,在【查找】中选择文件目录后,窗口中即可列出该目录下所有可用的建模数据文件,文件类型包括:*.mcf、*.mtx 、*.txt、*.csv、*.xlsx、*.xls。
导入mtx数据文件
选择预先生成的建模用表mtx文件,由于生成建模文件时,已经配置了文件选项,所以选择mtx数据文件,点击【确定】后会直接将数据文件导入。
导入非mtx数据文件
选择非mtx数据文件,需要导入数据配置并配置导入变量。以train.csv为例:
选择文件train.csv,点击【确定】进入导入数据界面,如下图所示:

配置界面功能选项说明:
【第一行是标题】:勾选此项时,表示将数据文件中的第一行数据作为标题;不勾选时标题默认显示为“_n”,n表示第n列,例如_1,_2,…
【如果字段串外有引号则先剥离,包括标题部分】:勾选此项时,当字段名及字符串类型的字段值外含有引号时,会自动去掉引号;
【检查数据合法性(列数是否一致)】:勾选此项时,在生成建模用表文件时会自动检查本地数据文件列数是否一致;
【列数和第一行不匹配时删除该行】:勾选此项时,当某行数据列数与第一行列数不一致,生成建模用表时会自动删除该行数据;
【使用双引号作为转义字符】:勾选此选项时,将双引号做为转义字符处理;不勾选时,默认将斜杠作为转义字符处理;
【字段分隔符】:根据数据文件中的实际情况选择分隔符;
【字符集】:选择要操作的数据文件所支持的字符集;
【日期格式】、【时间格式】、【日期时间格式】:用户可自定义日期、时间、日期时间格式;
【区域和语言】:根据实际情况选择语言;
【缺失值(竖线分割)】:默认为NULL|N/A,也就是数据中出现的NULL或N/A时,表示数据缺失。用户还可以自己手动添加缺失值,设置多个缺失值时使用“|”分隔。
导入选项配置完成后,点击【下一步】进入导入变量配置界面,如下图所示:

左侧的变量面板中,勾选出要导入的变量,默认选出所有变量。
【选出】:勾选状态表示导入,不勾选则不导入。
【类型】:下拉列表中可以修改变量的数据类型。除此之外,也可以点击![]() 选择预先定义好的数据字典文件,来导入变量类型。
选择预先定义好的数据字典文件,来导入变量类型。
数据字典支持xls、xlsx、txt、csv 4种格式的文件,文件格式如下:

(1) 第一列为变量名称;
(2) 第二列为变量类型,变量类型包含:Identity(ID)、Categorical(分类变量)、Binary(二值变量)、Unary(单值变量)、Count(计数变量)、Numerical(数值变量)、Datetime(时间日期)、Text(长文本),根据实际数据配置;
(3) 第三列是时间日期的数据格式,例如:日期格式yyyy-MM-dd、时间格式HH:mm:ss、时间日期格式yyyy/MM/dd HH:mm:ss等;
(4) 第四列是此变量类型是否使用,true表示使用;false不使用;
(5) 第五列是此变量的重要度。
例如:csv格式的数据字典文件

注意:使用csv文件时,变量之间用逗号分隔列。使用txt文件时,变量之间用tab分隔列。
右边预览数据界面中,用户还可以自定义设定显示前多少行数据,然后点击重载,可以刷新页面中显示的数据。
导入变量配置完成后,点击【完成】,会弹出检测变量类型窗口,如下图:

具体配置可参考检测变量类型 小节,配置完成后点击【确定】以后即可导入数据。
使用数据库作为数据来源之前,需要先配置数据源,
在易明建模中,需要通过数据源配置来连接数据库,操作步骤如下:
1、点击工具 - 数据源进入如下窗口:

2、点击【新建】按钮,弹出数据库类型对话框,数据库类型有“JDBC”、“ODBC”两种

JDBC
数据库类型对话框中选择“JDBC”,点击 【确定】按钮,弹出关系数据库数据源配置对话框,如下图所示:

1、数据源名称:可以任意指定,如ora、SQL17等;
2、数据库供应商:选择对应数据库类型,如果没有符合类型,请选择UNKNOW;
3、驱动程序:可以使用下拉框中默认,也可以输入其他的驱动信息;
需提前将所用到的数据库的JDBC驱动程序拷贝到[安装目录]/common/jdbc下;
4、数据源URL:根据实际数据库URL配置,例如oracle数据库:jdbc:oracle:thin:@192.168.0.68:1521:orcl;
5、用户:数据库用户名;
6、口令:访问数据库的密码;
7、批处理大小:设置与数据库交互的批处理大小;
8、对象名带模式:指的是数据表表名前是否带有模式名,比如:dbo.员工;
9、对象名带限定符:是否使用带引号的SQL。
扩展属性:除了设置以上所述的常规属性外,有些数据库还要求设置一些扩展参数,这时候就可以进入到扩展属性tab页下进行设置了。不同的数据库,扩展属性中的参数名称是不一样的,这些参数名称都是在设置完成了常规属性以后,系统根据数据库类型自动添加的。有些数据库是没有扩展参数的,例如access。
设置完成后,点击【确定】按钮,回到数据源配置界面,关系数据库类型的数据源就配置完成了,数据源配置界面中就列出了你新建的数据源,如下:

点击【连接】按钮,数据源名称显示粉色已连接则表示连接成功。
ODBC
数据库类型对话框中选择“ODBC”,点击 【确定】按钮,弹出ODBC数据源配置对话框,如下图所示:

1、数据源名称:可以任意指定,如ora、SQL17等;
2、ODBC名称:在ODBC数据源管理器中为所连数据库定义的ODBC数据源名称;
3、用户名:数据库用户名;
4、密码:访问数据库的密码;
5、使用带模式的表名称:指的是数据表表名前是否带有模式名,比如:dbo.employee;
6、大小写敏感:指的是sql语句是否区分大小写;
7、对象名带限定符:是否带限定符。
设置完成,点击【确定】按钮,回到数据源配置界面,ODBC类型的数据源就配置完成了,数据源配置界面中就列出了你新建的数据源。
加密级别
可在加密级别中设置对数据源定义中的口令是否加密,对应着userconfig.xml文件中encryptLevel属性,属性取值0(明文)或1(密码加密)。
明文:当加密级别选择明文时,对应userconfig.xml文件的数据源配置中会自动设置encryptLevel = 0。此时,密码不加密,如下图:

密码加密:当加密级别选择密码加密时,对应userconfig.xml文件的数据源配置中会自动设置encryptLevel = 1。此时,密码会以加密后的文本串方式显示,如下图:

选择数据库表

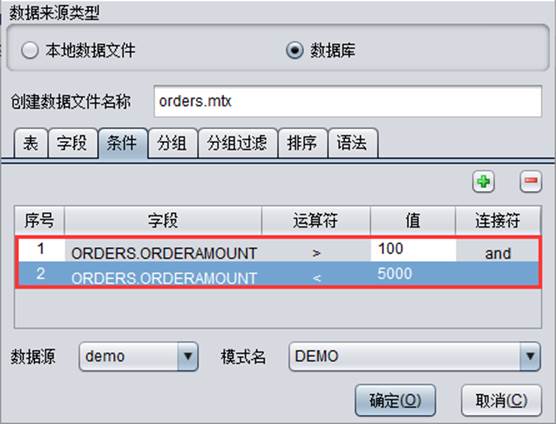
【创建数据文件名称】:配置生成的建模用表文件名,文件后缀为:*.mtx;
【数据源】:选择数据源;
【模式名】:选择数据源中的模式;
【表】:选择数据库表;
【字段】:选择数据库表中的字段;
【条件】:对所选表中数据增加筛选条件;
【分组】:对数据进行分组;
【分组过滤】:对数据进行分组过滤,相当于数据库语言中的Having;
【排序】:对数据进行升序/降序排序;
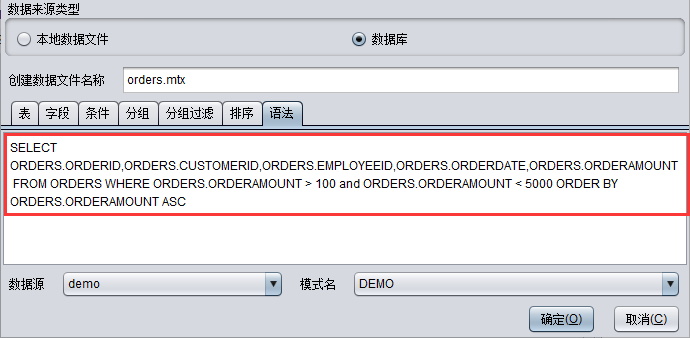
【语法】:使用数据库语法选择数据。
在数据库中配置数据源、模式名、数据库表、字段等信息,具体操作以demo数据库中的“ORDERS”表为例导入数据:



检测变量类型
在新建模型时,导入非mtx数据文件或数据库表过程中会提示检测变量类型。
检测范围配置
为了导入正确类型的变量数据,成功建模。在导入数据时,可以选择立即检测变量类型, 来检测确保导入正确类型的变量数据;但对于数据量大的文件,如果想要快速导入数据,进入设计器,也可以后续通过变量检测菜单进行检测。界面如下图:

当选择不检测时,导入数据的变量类型默认为分类变量。若选择了不检测,进入设计器以后需要在变量检测菜单进行检测,或者手动设置每个变量的变量类型。需要注意的是,不检测或者不设置正确的变量类型,那么在建模过程中就会报错。
是否提示检测
如果选中某一项后勾选了不再提示,那下次进入数据导入界面就会默认按照以前的选项进行处理,若后期想要更改默认选项可以在菜单栏中的工具 - 配置窗口中进行配置,如下图:

导出数据质量报告
导入建模数据后,可以通过该功能导出数据质量报告,点击文件 - 导入/导出 - 导出数据质量报告,导出文件为pdf格式。
质量报告中信息内容包括数据中的变量个数、行数、缺失率统计、数值变量偏度统计、分类变量的势统计等信息。
导出数据探索报告
导入建模数据,执行变量统计后,可以通过该功能导出数据探索报告,点击文件 - 导入/导出 - 导出数据探索报告,导出文件为xlsx格式。
数据探索报告中,针对“目标变量类型 + 当前变量类型”的组合做一些信息统计。
目标变量类型分为两类,一类是离散型:分类、二值、单值;一类是连续型:数值、计数、日期。不同类型的目标变量,导出的数据探索报告的内容是不同的。