分组报表
本节我们将介绍一个常规的分组报表的例子,学习group()函数的用法。
一个例子
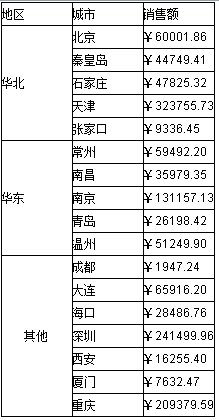
我们先看下面这个分组报表:

从上面的这个报表可以看出,这是一个分组报表,左边按照地区维度进行了完全的分组,整个报表被分成东北、华北、华东、华南、西北、西南等6组,我们看一下这样的报表在润乾报表中是如何设计的:
1、 首先通过报表 - 数据集菜单,定义数据集:
ds1:SELECT 客户.城市,客户.地区,订单明细.数量,订单明细.单价 FROM 客户,订单,订单明细 WHERE 客户.客户ID = 订单.客户ID AND 订单.订单ID=订单明细.订单ID
2、 写入单元格表达式,如下图所示:

此报表保存为11.1.1.rpx。
从上图可以看出,该报表最关键的是A2格和B2格,利用group函数对数据集进行了分组,并把分组结果在报表中进行纵向扩展。
这个例子用到了group函数,下面我们做一下介绍:
group()
函数说明:
根据分组表达式,从数据集中选出一组组集。
语法:
datasetName.group(<selectExp:order1>{,filterExp};;{ groupSortExp }:{ groupOrderExp }) //适用于不需要排序或数据集中已排好序
datasetName.group(<selectExp>{,filter_exp};{sort1}{:order1},…;{ groupSortExp }:{ groupOrderExp })
参数说明:
selectExp 选出的分组表达式,可以是字段列名/列号,也可以是表达式。列号用#n表示,例如#0代表第0列,#1代表第1列,依此类推
filterExp 过滤表达式
sort1 分组前记录的排序依据表达式
order1 分组前记录的排序顺序,省略为不排序,>0升序,<0降序;order1,..,ordern省略时升序
groupSortExp 分组后对组的排序表达式,一般是汇总运算的表达式,如组合计等
groupOrderExp 组排序顺序,>0升序,<0降序
选项:
@r 是否为根数据集表达式
返回值:
一组数据的集合,数据类型由selectExp的运算结果来决定
示例:
例1:ds1.group(class)
把数据集ds1中所有记录按照class字段不排序只进行分组,相邻相同的值分到一组,并返回每组的class值组成的集合
例2:ds1.group(class:-1 )
把数据集ds1中所有记录按照class字段降序排列,然后根据class进行分组,并返回每组的class值组成的集合
例3:ds1.group(class,gender=='1'; class)
从数据源ds1中选取性别为"1"的记录,按照class字段升序排列,然后根据class进行分组,并返回每组的class值组成的集合,order1缺省为升序
例4:ds1.group(class, gender=='1'; id:-1 )
从数据源ds1中选取性别为"1"的记录,按照id字段降序排列,然后根据class进行分组,并返回每组的class值组成的集合
例5:ds1.group(省份;省份:1; sum(工业产值):-1)
对数据集ds1按照省份进行分组,分组后求出每组的sum(工业产值),然后按照这个汇总值对组进行逆序排列
例6:ds1.group@r(GENDER;GENDER;ds1.sum(SALARY))
对根数据集ds1按照GENDER进行分组,分组后求出每组的sum(SALARY,然后按照这个汇总值对组进行升序排列
●注意:
group函数是对数据集按照某个字段或者表达式进行分组,获得一组组的集合,然后从每组中取出一个指定字段或者表达式的值,放到单元格中进行扩展,扩展出来的每个单元格都保留了一个指针指向当前的组集,该组集称为当前组。
因此在附属单元格中,需要对该组集进行操作时,不需要用任何条件和主单元格关联了,如果加设了条件,反倒画蛇添足,导致报表引擎还对组集中的记录进行遍历检索。
正确的group 用法:
不合理的group用法:
group函数的原理图示: