
多片扩展
本节将以一个主子表为例,深入了解主格认定规则,学习select() 函数的用法。
一个例子
我们看下面这个报表:
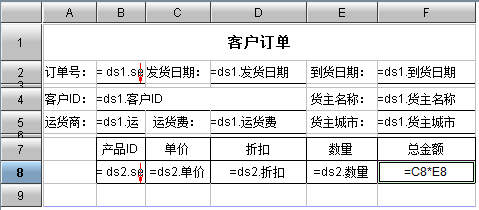
这是一个很常见的主子报表,主表和子表往往存储在不同的物理表中,而且通常是一对多的关系。在一般的报表工具中,这种报表往往利用专门的子表控件来实现,虽然功能实现了,但是存在的缺点是:主子表之间不容易共享数据,不容易进行表间数据的运算。润乾报表利用其多源关联分片模型,很轻松地在单个报表中实现了主子表的功能。下面我们介绍一下该报表的制作方法:
1、 首先定义数据集:
ds1:SELECT DISTINCT 订单.订单ID,订单.客户ID,订单.发货日期,订单.到货日期,订单.货主名称,订单.运货商,订单.运货费,订单.货主城市 FROM 订单
ds2:SELECT 订单明细.产品ID,订单明细.单价,订单明细.折扣,订单明细.数量,订单明细.订单ID FROM 订单明细
2、 定义单元格的表达式
(1) 在B2单元格输入表达式:= ds1.select(订单ID:1,,,订单ID)
(2) 在D2单元格输入表达式:= ds1.发货日期
设置显示格式为:yyyy年MM月dd日
(3) 在F2单元格输入表达式:= ds1.到货日期
设置显示格式为:yyyy年MM月dd日
(4) 在B4单元格输入表达式:= ds1.客户ID
(5) 在F4单元格输入表达式:= ds1.货主名称
(6) 在B5单元格输入表达式:= ds1.运货商
(7) 在D5单元格输入表达式:= ds1.运货费
设置显示格式为:¥#0.00
(8) 在F5单元格输入表达式:= ds1.货主城市
(9) 在B8单元格输入表达式:= ds2.select(产品ID:1,订单ID==B2,,产品ID)
(10) 在C8单元格输入表达式:= ds2.单价
设置显示格式为:¥#0.00
(11) 在D8单元格输入表达式:= ds2.折扣
设置显示格式为:#0.0
(12) 在E8单元格输入表达式:= ds2.数量
(13) 在F8单元格输入表达式:=C8*E8
设置显示格式为:¥#0.00
3、 设置左主格属性
将A1、A2、A3、A4、A5、A6、A7、A8、A9单元格的左主格设为B2单元格。
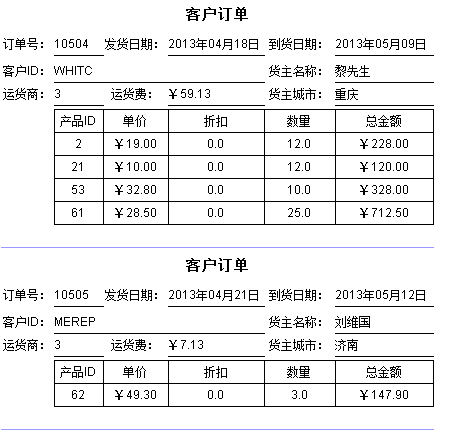
4、 报表保存为10.6.1.rpx,预览报表

这个例子中,我们发现,左主格是人为指定的,并不是缺省的,这用到了报表主格模型中的主格认定规则,主格的认定包括缺省认定和人为认定,下面我们对该理论进行介绍:
主格认定规则
缺省主格认定
单元格横向扩展时,上方横向扩展单元格缺省为它的上主格,下方单元格缺省为它的附属格;如果上方没有横向扩展格,则上主格缺省为 `0 格
单元格纵向扩展时,左边纵向扩展单元格缺省为它的左主格,右边单元格缺省为它的附属格;如果左边没有纵向扩展格,则左主格缺省为 `0 格
人为改变主格规则
除了上面提到的缺省情况外,我们允许人为地改变单元格的主格。可以将某个单元格的左主格设置成某个纵向扩展格、上主格设置的某个横向扩展格,左主格和上主格是分别设置的。
为了符合扩展变化的规则,我们可以知道人为设置主格需要满足一些条件:
Ø 左主格必须是纵向扩展格,上主格必须是横向扩展格,否则设置无效。
Ø 不允许出现循环设置的情况,即设置A的主格是B,B的主格是C,C的主格又是A,出现循环设置时认为设置有误,报表无法计算。显然,在缺省的情况下是不可能出现循环设置的,而在人为设置时必须避免这种情况的出现。
Ø 横向扩展格不允许有左主格,纵向扩展格不允许有上主格。
人为设置时,可能发生左(上)主格在右(下)边的情况,而且主格也不一定和附属格在同一行(列)上。
例10.6.2-1:
select()
函数说明:
从数据集的当前行集中选取符合条件的记录
语法:
datasetName.select(<select_exp>{: order_exp},{ filter_exp },{num_exp},{distinct_exp})
datasetName.select(<select_exp>{,filter_exp},{num_exp},{distinct_exp}; {sort1_exp}:{order1_exp},….) //适用于不需排序或数据集中已排好序
参数说明:
select_exp:选择的字段列名/列号,也可以是表达式。列号用#n表示,例如#0代表第0列,#1代表第1列,依此类推
order _exp: 指定数据排序的顺序,<0表示降序排列,>0表示升序排列。
filter_exp: 数据过滤表达式,如果全部选出,则此参数省略,仅用“,”占位。
num_exp: 获取查询结果的前n条记录
distinct_exp: 筛选某字段,返回唯一不同的值
sort1_exp: 数据排序表达式。当此项为空时先检查order_exp是否为空,如果为空,则不排序,否则使用select_exp排序。
返回值:
一组数据的集合,数据类型由select_exp的运算结果决定
选项:
@r 是否为根数据集表达式
@z 从后往前取数,num_exp省略时返回全部
示例:
例1:ds1.select( name )
从数据集ds1中选取name字段列的所有值, 不排序
例2:ds1.select( #2:-1)
从数据集ds1中选取第二个字段列的所有值并降序排列
例3:ds1.select( name:1, gender =='1')
从数据集ds1中选取性别为男性的name字段列的值并升序排列
例4:ds1.select( name:-1, gender =='1',50, id )
从数据集ds1中筛选掉id字段重复值,选取50条性别为男性的name字段列的值并按name字段降序排列
例5:ds1.select(int(EMPID), gender =='1',50,id;BONUS:1)
从数据集ds1中筛选掉id字段重复值,将数据集按BONUS升序排列,选取50条性别为男性的EMPID字段列的值
例6:ds1.select@r(#9:-1,SALARY>=10000)
从根数据集ds1中筛选SALARY大于10000的第9列的值并降序排列
例7:ds1.select@z(#9:1,SALARY>=10000)
从数据集ds1中筛选SALARY大于10000的第9列的最后3个值并降序排列
●注意
select()函数选出了一组字段值,该组字段值保留了一个指针,指向数据集中的源记录,也就是说,该组字段值和数据集中的记录保持一一对应的关系,因此在当前格的附属单元格里(如B2、C2),如果采取dsn.colname 的表达式从当前数据集里取其他字段的值,默认从当前主格指向的记录里取值,而不需要到数据集中检索。因此,在当前格的附属格里建议尽量使用dsn.colname表达式,而不采用dsn.select(colname, filterexp, number),因为后者需要对表达式进行解析,速度慢。