
数据模型
如上所述,报表是由表格、数据、数据间的运算逻辑组成的,因此数据是报表的基础,我们首先来讲讲润乾报表的数据模型。
基本概念:
数据集
我们定义数据集为一个由数据数组构成的二维数据表,其同列的元素数据类型都相同,为了方便,我们给数据集的列都起了一个可唯一标识的名字,列的名字和数据类型都保存在数据集中。
记录和字段
考虑到关系数据库的习惯,同时为了和报表的行、列加以区分,我们把数据集的行称为记录,列称为字段。
数据集中的记录都有行号,依次为1,2,3,4,……,获取数据集行号的书写规则为:
dsName.#0 //获得当前行的行号
或 dsName.select(#0) //获得数据集所有记录的行号
其中dsName代表数据集的名字,#0代表第0列,即说明数据集的行号保存在第0列中。
行集
数据集的行集定义为一些由数据集的行按某种顺序构成的数组,数据集本身也是一个行集。从组成元素上看,行集是数据集的子集,但排列次序未必与数据集的行序相同。
分组与组集
将数据集的所有记录按照一定的规则划分成N个行集的过程称为分组,分组后的每个行集称为一个组,多个组构成了组集。
数据集函数
能够对数据集的记录进行操作(取数、分组、运算等)的函数,我们称为数据集函数,其书写规则如下:
dsName.f(…)
其中,dsName为数据集的名字,f为函数名。
单源报表与多源报表
润乾报表中,报表数据来源是由一个或者多个数据集构成的集合,每个数据集都有唯一的名字,一般用ds1,ds2,…来表示。
当某个报表的数据来源只有一个数据集时,该报表称为单源报表;当某个报表的数据来源包括了多个数据集时,该报表称为多源报表。
由于单源报表的模型是多源报表的子集,因此我们这里仅仅介绍多源报表。
多数据集模型
多数据集模型图
润乾报表的多个数据集不需要进行整合运算,而是直接用于报表的运算,在报表的运算过程中,通过一定的规则把多个数据集关联起来。其模型图示如下:
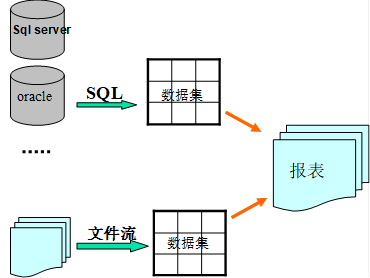
多数据集的设计背景
在制作报表的过程中,有时候各个单元格中的运算会基于不同的数据集甚至是基于不同的数据源。
举例:
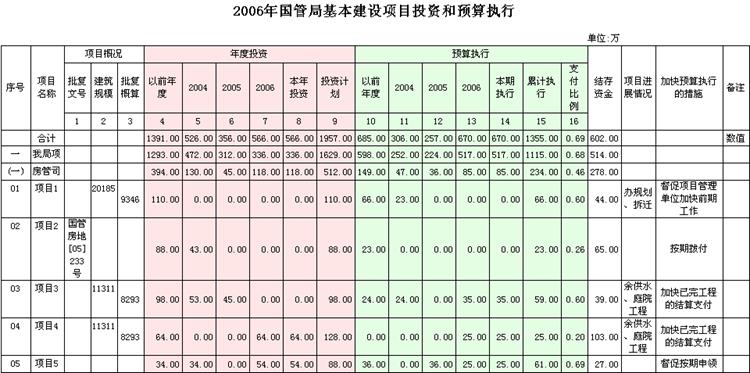
这是一个比较典型的多源报表,图中背景为白色、粉红色、浅蓝色的格子数据分别来自三个不同的数据集,分别通过左表头的项目名称关联起来。
更有甚者,这三个数据集很有可能存在不同的数据库中,或者是异构的数据来源,因此迫切的需要多数据集的模型。
多数据集和单数据集模型比较
真正意义上的多数据集模型,最典型的特征是不需要数据集间的整合运算,直接将数据集运用于报表的运算,在运算过程中关联。
数据集间的整合运算是指将多个数据集通过类似数据库的union、join等操作,整合成一个数据集的过程。整合运算极大的占用cpu资源,很多时候会导致数据量大大增加,对内存的占用也随之增加。
目前很多传统的报表工具号称支持多数据集,其实是把多个数据集通过整合运算,合并成一个数据集后,再运用于报表的运算,其实质还是单数据集模型。
当报表数据来自多个数据集时,如果采用单数据集模型,那么势必把三个数据集通过整合运算合并成一个数据集,然后进行交叉分组,其运算的复杂度大大增加,性能大大降低。
因此我们说,对于多源分片的报表,采用多数据集模型是最佳选择。