
组游标
在大数据运算中,除了遍历数据或者分组聚合运算,有时也需要每次取出一组的数据做分析。如按日期分析销售情况,统计每种产品的销售情况曲线,统计每个客户的进货习惯等。
按表达式分组取数
在集算器中,可以使用cs.fetch(;x)或cs.skip(;x)来获取或跳过记录,直到表达式x的值变化,以此来获取连续的一组数据。如,每次取出一个产品,准备考察每种产品的销售信息:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt") |
|
|
2 |
=file("Order_Electronics.txt") |
|
|
3 |
=file("Order_Foods.txt") |
|
|
4 |
=file("Order_Books.txt") |
|
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
|
6 |
=A5.merge(PID) |
|
|
7 |
for 19 |
=A6.skip(;PID) |
|
8 |
=A6.fetch(;PID) |
|
|
9 |
>A6.close() |
|
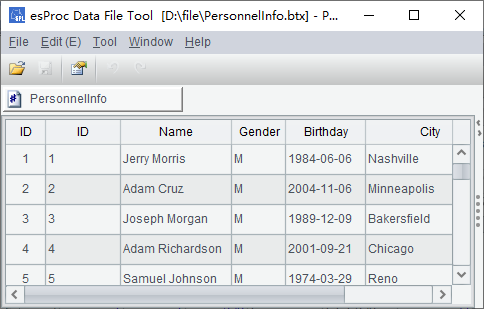
A6的游标中,包含着4种类型商品的销售数据,并按照PID排序。从A8中可以读出第20件商品的记录如下:
需要注意,游标中的数据在集算器中是单向单次遍历的,因此,在需要每次读取其中一组记录时,游标中的数据必须是有序的。
文件游标中的分段读取
在文本数据与集文件中,都讲述了cs.fetch() 的使用。我们知道,在cursor或者export函数中,添加分段参数,可以分段(分块)读取文件或游标中的数据。但是,分段读取时,数据会如何划分是由集算器决定的,有的时候会出现一些麻烦。
首先,我们准备一个数据文本:将上面用到的,按商品序号排序的数据,存储到一个新的集文本Order_Products.btx中:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
6 |
=A5.merge(PID) |
|
7 |
=file("Order_Products.btx") |
|
8 |
>A7.export@b(A6) |
在后面的计算中,如果将分段读取,我们看一下情况:
|
|
A |
|
1 |
=file("Order_Products.btx") |
|
2 |
=A1.cursor@b(;1:100) |
|
3 |
=A2.fetch() |
|
4 |
=A1.cursor@b(;2:100) |
|
5 |
=A4.fetch() |
在将全部数据分为100段后,A3中读出的第1段数据,和A5中读出的第2段数据如下:
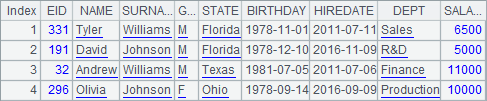
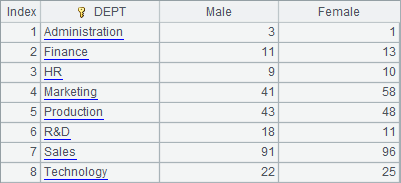
此时,就出现了这样的问题:同样是编号B1435的产品,它的销售记录在两组中都出现。如果每次取数后需要做聚合运算,那么在返回的结果中,就会出现重复的产品编号,不得不再次聚合后才能获得最终结果。这样的分段计算在大数据的并行运算中很常见,而上述情况会使计算变得复杂。此时,就应该在存储数据时,设定字段按组分段。
在使用游标存储集文件数据时,只需设定分段字段,此时写出数据时将根据字段按组分段,只有字段值变化时才会分段。这样在分段读取数据时,同一组的数据将被确保一次读出。如下:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
6 |
=A5.merge(PID) |
|
7 |
=file("Order_Products_G.btx") |
|
8 |
>A7.export@b(A6;PID) |
将按商品序号排序的数据,存储到一个集文件Order_Products_G.btx中,根据PID按组分段;和前面写出文件Order_Products.btx的方法略有不同。需要注意的是,分段存储需要存储时设定分段字段才有效,存储时是按照哪个字段来按组分段的,由输出时函数中的参数决定,如A8中指定将A6中的游标,按照PID字段按组分段,此时A6中游标中的数据必须对PID有序。
此时,再分段读取时,情况就不同了:
|
|
A |
|
1 |
=file("Order_Products_G.btx ") |
|
2 |
=A1.cursor@b(;1:100) |
|
3 |
=A2.fetch() |
|
4 |
=A1.cursor@b(;2:100) |
|
5 |
=A4.fetch() |
用游标读取时与使用普通的集文件是相同的,但如果存储时使用了按组分段,分段读取时的结果就有区别了。此时,A3和A5中读出的数据如下:
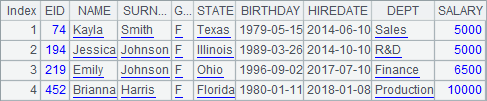
此时,第1段数据将读出所有编号B1445的商品销售记录为止,第2段数据将从下个商品开始。可见,如果在写出集文件时设定了按组分段,那么在从游标中分段读取数据时,将会把整组的数据放在一段中读出。通过设定按组分段,可以保证分段时每组数据的完整性,使得大数据的分段计算变得更简捷。