
组表的生成
集算器的组表使用特殊的格式来存储,组表文件的扩展名通常是ctx。下面先通过一个例子来了解组表的生成及其基本使用:
|
|
A |
B |
|
1 |
=demo.query("select NAME, SURNAME, GENDER from employee") |
|
|
2 |
=A1.select(GENDER=="M") |
=A1\A2 |
|
3 |
=A2.(NAME).id() |
=A3.len() |
|
4 |
=B2.(NAME).id() |
=A4.len() |
|
5 |
=A1.(SURNAME).id() |
=A5.len() |
|
6 |
[Sales,Technology,R&D,Financial,Admin] |
[0,0.5,0.75,0.9,0.97,1] |
|
7 |
=to(100000).new(#:EID,A6(B6.pseg(rand())):Dept, if(rand()<0.5,"F","M"):Gender, if(Gender=="M",A3(rand(B3)+1), A4(rand(B4)+1))/" "/A5(rand(B5)+1):Name) |
|
|
8 |
=A7.select(Dept=="Sales") |
=A8.len() |
|
9 |
2023-01-01 |
=workdays(A9,A9+365) |
|
10 |
=B9.((a=string(~,"yyMMdd"), to(rand(1000)+ 500).new(a/string(#, "0000"):OID, B9.~:Date,A8(rand(B8)+1).EID:EID, rand(100)*10+200:Amount))).conj().sort(EID, OID) |
=A10.groups(EID;count(~):OCount, sum(Amount):OAmount) |
|
11 |
=file("D:/file/dw/employees.ctx") |
=A11.create(#EID,Dept,Gender, Name) |
|
12 |
|
>B11.append@i(A7.cursor()) |
|
13 |
=B11.attach(stable,OCount,OAmount) |
>A13.append@i(B10.cursor()) |
|
14 |
=file("D:/file/dw/orders.ctx") |
=A14.create@p(#EID, OCount, OAmount) |
|
15 |
|
>B14.append(B10.cursor()) |
|
16 |
=B14.attach(otable,#OID,Date,Amount) |
>A16.append(A10.cursor().new(EID, OID,Date,Amount)) |
|
17 |
>B11.close() |
>B14.close() |
A1中从demo数据库中取出员工资料,并在A3和A4中分别整理出男女员工的名字,在A5中整理出员工的姓,准备用来随机成姓名。
A6中列出可选的部门名称,在B6中设置测试数据中各个部门员工的累积占比。如销售部Sales员工占比0.5,财务部Financial员工占比0.97-0.9=0.07,等等。
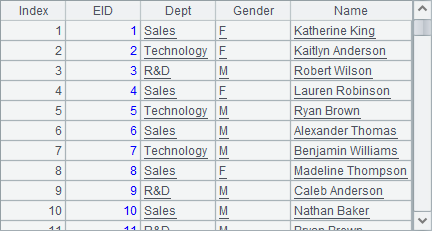
A7中随机生成了100,000位员工的测试数据,结果如下:
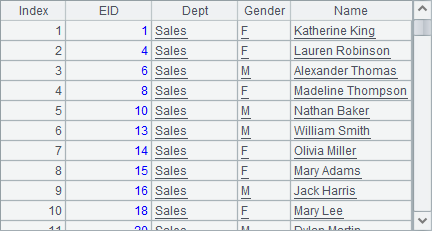
A8中从中选择出了销售部的员工,准备用来生成订单的测试数据:
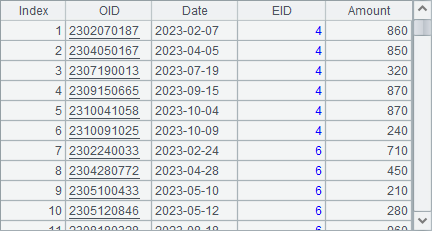
B9中简单生成了2023年的工作日序列,作为测试数据中的订单日期。A10中在每个工作日中随机生成订单数据,并按照EID和OID排序,结果如下:
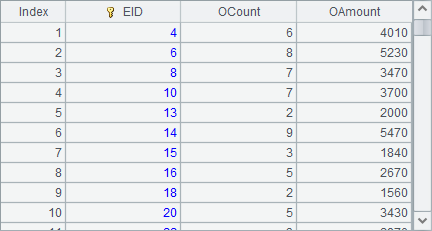
B10中统计出销售部每位员工的订单总数和总金额,如下:
现在,数据已经准备好了,可以来看组表是如何生成了。B11中,用f.create(C1,C2,…) 函数在组表文件employees.ctx中,生成了组表中的第一个实表员工实表,并定义了它的字段,其字段和A7中的员工数据是完全相同的。在组表中,员工实表不依附于任何表,它被称为基表,组表中有且仅有一个基表。其中,用#开头的字段是实表的维,维由实表中的某些列构成,实表中的记录对于维必须是有序的。组表employees.ctx的基表中定义了1个维EID,表示员工的编号,另外还有其它的一些字段,包括部门Dept、员工性别Gender和员工姓名Name。
组表默认将按列存储,如果需要按行存储,可以在create函数后添加@r选项。如果需要在组表中执行某条或某几条数据的查询,可以选择按行存储,以便于在查询时获得更好的性能,但行式存储的组表不便于处理整表的遍历计算,也不支持用多路游标访问数据。组表中的数据将压缩存储,以节省磁盘空间,如果不需要压缩可以在create函数后添加@u选项。如果生成组表时,指定名称的文件已存在,会失败报错,添加@y选项可以强制覆盖。
在B12中用T'.append(cs) 函数,用A7中的员工数据表构成游标,填入组表的基表中。使用T.append(cs) 函数时,必须保证cs的数据结构与实表T相同,这里的数据结构相同是指字段数和字段名称都要一致,否则添加数据时会产生错误。这里填入数据时使用了@i选项,立即将数据写人实表,如果没有使用这个选项则会积累到足够数据后执行写入,或者在组表用T'.close() 函数关闭时写入。在使用T.append()函数添加数据时,组表T不允许在多个位置打开,以防止数据冲突。
A13中用T.attach(T',C1,…)函数在同一个组表中,添加了实表stable,其字段包括订单个数OCount和订单总金额OAmount。类似的,在B13中将数据填入实表。需要注意的是,销售统计表stable是依附于基表,即员工实表的,是组表基表的附表,而相对的作为基表的员工实表称为stable的主表。附表除了具有自己的字段,还必须包括主表的键字段,因此填入数据时,B10中的数据也必须具备前表的键EID。
再来看14~16行,B14中定义了组表orders.ctx的基表销售员实表的字段,这个基表中定义了1个维:销售员编号EID。特别的,这里使用了@p选项存储时按首个字段EID分段,防止在分段读取时将同一个销售员的订单数据拆分。
B15中将销售统计表数据填入组表orders.ctx的基表。
A16中在组表中添加了订单实表otable,B16填入A10中的订单数据。
在组表orders.ctx中,订单实表otable,是依附于基表销售员实表的,是销售员实表的附表,相对的组表的基表销售员实表是otable的主表。在这个组表中,主表的键只有1个EID,而附表otable除了要具备主表的键EID外,还多一个键OID。这种情况下,主表与附表是主子表关系。
从上面的例子中可以了解,组表有可能包含多个实表,组表中的多个实表必须构成主表和附表的关系,其中有且仅有1个基表。组表使用后,在第17行中被关闭,关闭时只需关闭基表即可,如果组表使用时并未被写入则也可以不执行关闭。