
游标使用
在集算器中使用游标,可以分批完成对大批量数据的读取,在大数据运算中是最常使用的。无论是外存文件游标、数据库游标或者内存排列游标,它们的使用方法基本都是相同的。下面将主要以外存文件游标为例,讲述在集算器中,游标的一些基本使用方法。
使用游标读取数据
在游标创立后,可以用cs.fecth() 函数读取数据。与读取普通数据表不同,在用游标读取数据时,并不会一次读出全部数据,而是需要指定返回记录的条数,或者读取数据的条件。如:
|
|
A |
|
1 |
=file("Order_Books.txt") |
|
2 |
=A1.cursor@t() |
|
3 |
=A2.fetch(1000) |
|
4 |
>A2.close() |
|
5 |
=A2.fetch(1000) |
在A2中创建外存文件游标,A3中读取出前1000条数据如下:
使用fetch函数时,每次从游标中读取出的数据都会构成一个序表返回。A4中,调用cs.close() 函数关闭。游标关闭后,就无法再从中读取数据,如A5中的结果是null:

游标使用后,如果不再需要,应该调用cs.close() 函数关闭,以确保释放所占内存。
除了读出文件或者数据库结果集中的数据,还可以在游标中用cs.skip() 跳过指定条数的记录,如:
|
|
A |
|
1 |
=file("Order_Books.txt") |
|
2 |
=A1.cursor@t() |
|
3 |
>A2.skip(45000) |
|
4 |
=A2.fetch() |
|
5 |
=A2.fetch(1000) |
在A2中创建游标,A3中跳过45,000条记录,此时A4从游标中读取数据如下:
从交易ID中可以看到,读取数据时,是从第45001条记录开始的。可以注意到A4中的fetch函数中未指定返回记录的条数,此时将读取出游标中剩余的所有数据。当游标中数据被读取完毕后,游标会自动关闭,在这种情况下,可以不必再调用close。
如果此时在A5中再试图从A2的游标中读取数据,是读取不到结果的:
实际上,游标中的数据,无论是skip或是fetch,只会从前向后执行一次遍历,读取完毕或者直接调用close关闭后,就无法再次使用。
使用fetch函数读取游标中的数据时,还有一种方式是cs.fetch(;x) 指定读取条件,读取时会一直执行到条件表达式x的值发生变化为止。如:
|
|
A |
|
1 |
=file("Order_Books.txt") |
|
2 |
=A1.cursor@t() |
|
3 |
=A2.fetch(;Date) |
|
4 |
=A2.fetch(1000) |
|
5 |
>A2.close() |
在A2中创建游标,A3从游标中读取数据,一直到Date发生改变为止,读出的数据如下:
可以看到,A3中读取出了所有日期是2013-01-01的数据。如果A4中再继续从A2的游标中读取数据,将从2013-01-02开始:

需要注意的是,读取数据时,不能同时指定记录条数和读取条件,否则只有读取条件是有效的。另外,本例中游标A2中的数据并未全部取出,使用之后在A5中将其关闭。
类似的,使用skip函数跳过游标中的记录时,同样可以指定条件,如:
|
|
A |
|
1 |
=file("Order_Books.txt") |
|
2 |
=A1.cursor@t() |
|
3 |
>A2.skip(;Date) |
|
4 |
>A2.skip(;Date) |
|
5 |
>A2.skip(;Date) |
|
6 |
=A2.fetch(1000) |
|
7 |
>A2.close() |
A2中创建游标,在A3、A4和A5中分别跳过1天的记录。此时A6再从游标中读取数据,将从第4天开始:
同样的,当游标中的数据未全部取出时,在A7中调用close函数关闭游标。
循环游标
在用游标读取数据时,还可以用for语句来循环游标中的数据。如:
|
|
A |
B |
|
1 |
=file("Order_Books.txt") |
|
|
2 |
=A1.cursor@t() |
0 |
|
3 |
for A2,1000 |
=A3.select(SalesID==1).sum(Amount) |
|
4 |
|
>B2=B2+B3 |
在A2中创建游标,并在A3中循环游标,每次读出1000条记录,所有记录遍历完成后自动关闭游标。在A3的代码块中,根据每次取出的序表来计算1号销售员的总销售额,并记录在B2中,结果如下:
![]()
在循环游标时,有时并不会遍历所有数据,如:
|
|
A |
B |
C |
|
1 |
=file("Order_Books.txt") |
|
|
|
2 |
=A1.cursor@t() |
[] |
|
|
3 |
for A2,1000 |
=A3.select(SalesID==1) |
>B2=B2|B3 |
|
4 |
|
if B2.len()>=5 |
>B2=B2(to(5)) |
|
5 |
|
|
break |
|
6 |
>A2.close() |
|
|
在A2中创建游标,并在A3中循环游标,每次读出1000条记录。在A3的代码块中,根据每次取出的数据选出1号销售员的销售记录,并记录在B2中。当找到前5条记录后,停止循环。此时,B2中结果如下:
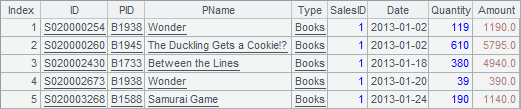
必须要注意的是,当完成计算,用break退出循环时,游标中的数据并未全部读取出来,这和前一个例子中的情况不同,游标并不会自动关闭。因此,A6中调用了close函数,关闭游标以清除其占用内存。
与fetch和skip类似,循环游标时,也可以设定条件,每次读取数据时都执行到条件表达式发生变化为止,如:
|
|
A |
B |
C |
|
1 |
=file("Order_Books.txt") |
|
|
|
2 |
=A1.cursor@t() |
=create(Date,Count,Amount) |
|
|
3 |
for A2;Date |
=A3.count() |
=round(A3.sum(Amount)) |
|
4 |
|
>B2.insert(0,A3.Date,B3,C3) |
|
此时在A3中每次读出1天的销售数据,在其代码块中计算出每天的交易笔数及总金额,记录在B2的序表中。计算完成后,B2中的结果如下:
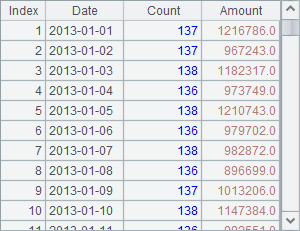
用游标执行计算
除了从游标中读取数据,在集算器中还可以直接使用一些函数,用游标完成常用的数据计算。如从游标中根据条件选出数据:
|
|
A |
B |
|
1 |
=file("Order_Books.txt") |
=A1.cursor@t() |
|
2 |
=B1.select(SalesID==1) |
=A2.fetch() |
|
3 |
=A2.fetch() |
=B1.fetch() |
B1生成外存文件游标,A2根据B1的游标中选出1号销售员的销售数据。查看A2中的数据如下:
![]()
可以发现,A2中的结果,和B1中是相同的。和序表或排列中的select函数不同,在游标中使用select函数时,返回的结果是游标本身,计算A2时其实并未真正从游标中获取数据,而是在游标上附加运算。在B2中执行fetch时,才会根据条件在B1游标中检索数据,结果如下:
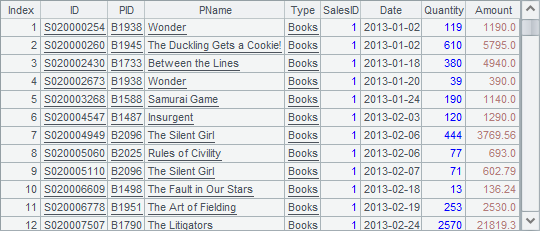
在B2中使用fetch时,未指定返回条数,也未设定读取条件,此时会返回游标A2中的所有数据,即1号销售员的所有销售数据。A2中游标的数据全部读取后,会自动关闭。同时,由于A2中的游标和B1中的游标是相同的,在检索数据时,实际上是在B1的游标中遍历并执行附加的运算,因此A2游标中的数据读取完成时,B1游标中的数据同样完成了读取,会被关闭。所以,此时在A3和B3中,无法再从A2或者B1的游标中读取数据。
如果文件中的数据是有序的,可以用f.iselect(A,x,Fi,…;s) 或f.iselect(a:b, x,Fi,…;s) 函数来选择数据生成游标,以提高效率。如:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").iselect@t(["S020000012", "S020000022"],ID; ID,PID,Date,Amount) |
=A1.fetch() |
|
2 |
=file("Order_Books.txt").iselect@ti(date(2013,2,1): date(2013,2,28),Date; ID,PID,Date,Amount) |
=A2.fetch@x(100) |
由于文件中包含字段名,因此添加@t选项,类似的,如果使用的是集文件,可以添加@b选项。A1中使用f.iselect(A,x,Fi,…;s)中,按照订单ID查找销售记录,在默认情况下,使用iselect函数检索数据时,要求对应的数据是唯一的。A2中使用f.iselect(a:b, x,Fi,…;s) 函数来查找一段日期期间内的销售记录,这里添加了@i选项,表明Date不是唯一的,检索时会返回符合要求的全部数据。执行后,B1和B2中的结果分别如下:

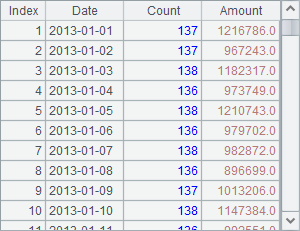
另外,还可以根据游标来生成新记录,或者添加计算字段,如:
|
|
A |
B |
|
1 |
=file("employee.txt") |
=A1.cursor@t(EID, NAME,SURNAME, GENDER, STATE,BIRTHDAY) |
|
2 |
=B1.new(EID, NAME+" "+SURNAME: FullName, GENDER,STATE,BIRTHDAY) |
=B1.derive(age(BIRTHDAY):Age) |
|
3 |
=A2.fetch(100) |
=B2.fetch(100) |
|
4 |
>A2.close() |
=B2.fetch() |
|
5 |
>B2.close() |
|
在B1中使用外存文件employee.txt生成文件游标,生成时选出部分字段。在A2中根据B1游标中的NAME和SURNAME字段,拼成员工的全名。B2中则在B1游标中计算出每位员工的年龄添加到Age列。与cs.select() 相同,cs.new() 与cs.derive() 这两个函数同样返回游标,而并不会直接开始返回数据。运行后,A2和B2中的游标和B1中是相同的:
![]()
A3中检索出前100条数据如下:
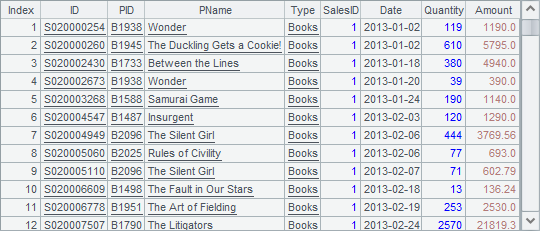
使用cs.new() 函数生成数据,相当于对每一条记录执行new计算。
B3中检索出100条数据如下:

使用cs.derive() 函数生成数据,相当于在返回的序表中添加计算列。
可以发现,B3中的数据与A3中的结构是相同的,而且是从第101位员工开始的。这是由于A2与B2中只是在游标中添加了计算,实际使用的是同一个游标,而游标中的数据只会从前往后执行单次遍历。因此A3执行后,游标已经查询了100条,B3再执行fetch时,就只会继续读取数据,也就会从第101位员工开始了。
由于游标中的数据并未全部读出,因此使用完毕后应该用close关闭游标。当A4中关闭了A2中的游标时,由于A2和B1中的游标是相同的,因此B1中的游标也会同时被关闭。如果试图继续读取数据,结果为空。
另外,还可以用cs.run() 来修改游标读取的数据中,某个字段的值,如:
|
|
A |
B |
|
1 |
=file("employee.txt") |
=A1.cursor@t(EID, NAME,SURNAME, GENDER, STATE,BIRTHDAY) |
|
2 |
=demo.query("select STATEID, NAME, ABBR from STATES") |
=B1.run((a=STATE, STATE=A2.select@1(NAME==a).ABBR)) |
|
3 |
=B2.fetch(100) |
>B2.close() |
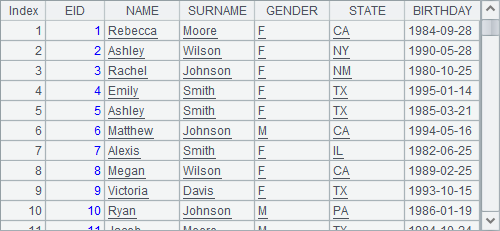
在B2中,将返回数据中的州换为对应的简称。返回的仍然是被添加了计算的游标:
![]()
A3中读取前100条数据如下:
与序表类似,在游标中还可以使用switch转换,将读取出的数据中字段转换为其它序表中对应的记录,如:
|
|
A |
B |
|
1 |
=file("employee.txt") |
=A1.cursor@t(EID, NAME,SURNAME, GENDER, STATE,BIRTHDAY) |
|
2 |
=demo.query("select STATEID, NAME, ABBR from STATES").keys(STATEID) |
=B1.switch(STATE,A2:NAME) |
|
3 |
=B2.fetch(100) |
>B2.close() |
在B2中,用cs.switch() 对游标中的数据执行转换,B2中的结果仍然是添加了计算的游标:
![]()
从A3中读取出数据如下:
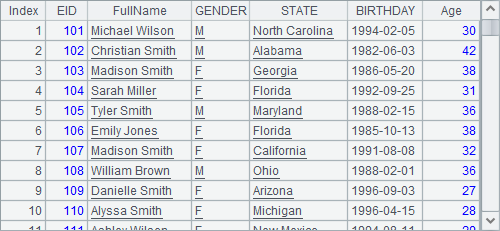
可以看到,返回的结果中,STATE字段转换为了对应的州记录。
在使用cs.switch() 时,也可以一次处理游标中的多个字段,如:
|
|
A |
B |
|
1 |
=file("employee.txt") |
=A1.cursor@t(EID, NAME,SURNAME, GENDER, STATE,BIRTHDAY) |
|
2 |
[F,Female,M,Male] |
=create(ID,Gender).record(A2).keys(ID) |
|
3 |
=demo.query("select STATEID, NAME, ABBR from STATES").keys(STATEID) |
=B1.switch(GENDER,B2;STATE,A3:NAME) |
|
4 |
=B3.fetch(100) |
>B3.close() |
在B3中,同时转换游标中的多个字段为其它序表中的对应记录,A4中读取前100条记录如下:

在主键与索引功能中,讲述了普通序表中,switch的使用。在外存计算中使用cs.switch() 时,和序表中的使用是类似的。在switch执行前,同样会为对应的维表字段建立索引表以提高效率。由于使用游标时,往往是需要处理大批数据的,因此这样的处理方式更为必要。