
游标归并与连接
在使用序表计算时,可以将多个序表中的数据整合起来分析计算。如用A.merge()将各个序表中的记录有序归并,或者用A.conj()函数将它们中的记录依次纵向连接成一个总表。还可以用join、join@p或者xjoin这几个连接函数,将多个序表中的数据连接起来,利用它们之间的关联性来查询或计算。
相应的,在用游标处理大数据运算时,同样可以使用游标的归并与连接。在这里,我们将了解一下如何使用CS.conj(), CS.merge(x), joinx()等函数,来将多个游标中的数据归并或连接。
有序归并
在很多时候,数据可能会存储在多个数据表中,如多种产品的销售记录,各部门员工的资料等。在这种情况下,我们需要将多个数据表中的数据合并在一起使用。对于普通的多个同构序表,在集算器中,可以用A.conj() 或者A.merge(x) 将各个序表中的记录合并成排列使用。如果数据表中使用大数据,也可以用CS.conj() 以及CS.merge(x) 将游标序列CS中各个游标的数据合并,并在读取时归并读出。
由于游标中的数据仅会遍历一次,且通常不会一次全部读出,这样,从游标中读取数据时,是无法在全部归并读取后再重新排序的,因此在归并多个游标的数据时,要求各个游标中的数据必须是有序的。
下面,我们用实际例子了解一下CS.conj() 及CS.merge(x) 的使用方法和不同之处。先来看简单纵向连接的情况:
|
|
A |
B |
C |
|
1 |
=file("Order_Wines.txt") |
|
|
|
2 |
=file("Order_Electronics.txt") |
|
|
|
3 |
=file("Order_Foods.txt") |
|
|
|
4 |
=file("Order_Books.txt") |
|
|
|
5 |
=[A1:A4].(~.cursor@t()) |
|
|
|
6 |
=A5.conj() |
300 |
|
|
7 |
for |
=A6.fetch(B6) |
|
|
8 |
|
if B7==null |
break |
|
9 |
|
=B7(1).Type |
=B7(B6).Type |
|
10 |
|
if B9!=C9 |
break |
|
11 |
>A6.close() |
|
|
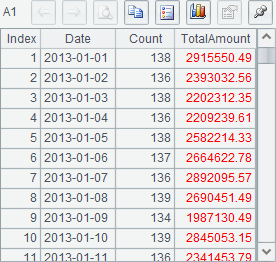
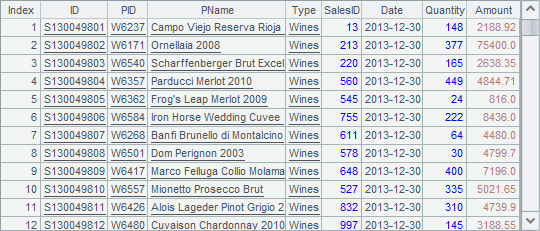
由四个文本数据分别记录酒类、电器、食品和图书四类商品的订单情况,在A6中将四个文本数据游标中的数据纵向连接。为了了解取出数据的顺序,在后面的代码中,每次读出300条记录,一旦其中出现不同种类的订单数据时,即中止读取。此时可以在B7中看到读出的序表如下:
从结果中可以看到,连接后的游标,在第1个文本数据表中所有酒类的订单数据全部读取完毕后,开始读取第2个文本数据表中的电器数据。即使用CS.conj() 函数简单连接后,结果游标中的记录将按照游标序列CS中的各个游标的顺序依次读出。
在更多的情况下,我们并不是仅需将各个数据表中的记录依次连接,而是希望将各个数据表中的数据按照一定的顺序归并在一起,此时可以使用CS.merge(x) 函数,需要注意的是,使用这个函数时,游标序列CS中的每个游标中的记录必须均对表达式x有序。如,将各类商品的订单数据按照销售日期排序归并:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt") |
|
|
2 |
=file("Order_Electronics.txt") |
|
|
3 |
=file("Order_Foods.txt") |
|
|
4 |
=file("Order_Books.txt") |
|
|
5 |
=[A1:A4].(~.cursor@t()) |
|
|
6 |
=A5.merge(Date) |
300 |
|
7 |
for |
=A6.fetch(B6) |
|
8 |
|
break |
|
9 |
>A6.close() |
|
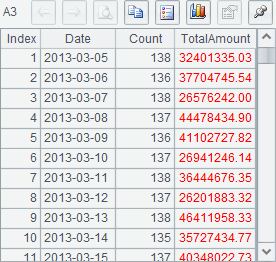
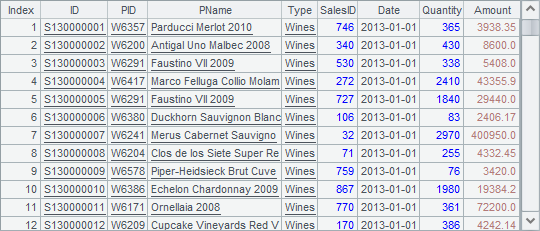
在这里,我们的目的是了解有序归并后,游标中记录的读取顺序,因此只读取前300条,B7中的序表如下:
可以看到,读取数据时,将按照指定的顺序Date依次读出,在读出1月1日所有酒类的订单数据后,将开始读取1月1日所有的电器订单数据,由于使用游标读取数据时只能从前往后单向进行,因此每个游标中的订单数据必须按日期完成排序。使用CS.merge() 函数有序归并后,结果游标在读取记录时,将通过比较各个数据表中当前计算表达式的值,选择用序列CS中的哪个游标取数。这样,最终就可以获得指定顺序的结果,在取数时,每个游标仍然遍历1次各个数据表中的记录。
在将多个游标中的数据有序归并时,只是将多个游标合并为一个,并调整了用各个游标读取记录的顺序,而不会增加或减少记录数据。
如果游标中的数据并非有序,那么必须在归并前将游标中的数据排序,如:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt") |
|
|
2 |
=file("Order_Electronics.txt") |
|
|
3 |
=file("Order_Foods.txt") |
|
|
4 |
=file("Order_Books.txt") |
|
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
|
6 |
=A5.merge(PID) |
2000 |
|
7 |
for |
=A6.fetch(B6) |
|
8 |
|
break |
|
9 |
>A6.close() |
|
在游标按产品编号有序归并之前,必须保证各个游标中的数据对产品编号有序。为此,在A5中,将各类产品的游标,用cs.sortx() 函数完成了排序。
需要了解的是,游标的排序和序表并不相同,由于游标中的数据量往往很大,无法一次读入内存完成排序。因此,在排序时,会一边读取数据,一边排序,每达到一定的数据量,就存储一个临时数据文件。全部数据读取排序完成后,最后再将所有的临时数据文件有序归并,返回结果游标。关于游标排序的更多内容,可以阅读外存排序原理。
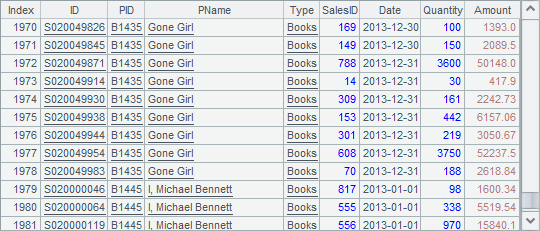
在B7中,读取出的记录如下:
可以看到,在每个游标中的数据排序后,就可以完成有序归并了。
对齐式连接
在统计数据时,有时需要将多个游标中的数据整合在一起,这类似于连接多个表中的数据。如果是游标中的数据需要连接一个普通序表,可以使用cs.switch()。
如果需要连接的数据都来自游标,情况又如何呢?我们知道,游标中的数据通常是无法一次读出的,那么如何将数据连接呢?在集算器中,可以使用joinx()函数来将多个游标中的数据连接起来。如:
|
|
A |
|
1 |
=file("Order_Wines.txt").cursor@t() |
|
2 |
=file("Order_Electronics.txt").cursor@t() |
|
3 |
=file("Order_Foods.txt").cursor@t() |
|
4 |
=file("Order_Books.txt").cursor@t() |
|
5 |
=A1.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
6 |
=A2.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
7 |
=A3.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
8 |
=A4.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
9 |
=joinx@1(A5:Wines,Date;A6:Electronics,Date;A7:Foods,Date;A8:Books,Date) |
|
10 |
=A9.fetch(25) |
|
11 |
>A9.close() |
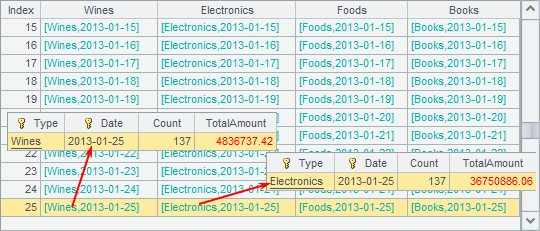
A5~A8中,分别对每一类产品分类聚合运算,各自返回缓存文件游标。关于groupx的使用,在外存分组原理中有更详细的说明。在A9中将各类产品每日的销售数据按照日期对齐连接。在A10中取出前25天的统计结果如下:
游标对齐式连接后,将返回游标,从中读出的结果和序表连接是类似的,每行数据的每个字段都是由记录构成的。因此,在读取时需要注意,连接后一行记录所占的内存会比普通情况更大。同时,由于数据均是记录而并非是值,如果使用结果游标进行计算时,要注意表达式的书写,特别是用结果游标再次连接时。
游标对齐式连接的结果,也可以再用来继承,如筛选,生成等,如:
|
9 |
=joinx@1(A5:Wines,Date;A6:Electronics,Date;A7:Foods,Date;A8:Books,Date) |
|
10 |
=A9.select(Foods.TotalAmount>Wines.TotalAmount) |
|
11 |
=A10.new(Foods.Date:Date,Foods.TotalAmount:Foods,Wines.TotalAmount:Wines) |
|
12 |
=A11.fetch(100) |
|
13 |
>A11.close() |
A10在连接的游标中,添加计算筛选出食品订单总额大于酒类订单总额的记录,并在A11中继续添加计算生成结果。在A12中返回了前100条结果,如下:
在使用游标的对齐式连接时,必须要知道,在取数时,游标中的数据是不能读取到内存中保留的,只能从前往后遍历记录一次。因此,连接计算中,各个游标中的数据必须是有序的,这和数据库中多表连接时的处理不同,也和普通序表的join() 不同。如上面的例子,A5~A8中的数据均是对日期有序的,这样才能保证在连接时的计算正确。
为了更好地说明这个问题,下面用数据较少的两个内存序表构成游标,来了解一下:
|
|
A |
|
1 |
$select * from CITIES |
|
2 |
$select * from STATES |
|
3 |
=A1.cursor() |
|
4 |
=A2.cursor() |
|
5 |
=joinx(A3:City,STATEID;A4:State,STATEID) |
|
6 |
=A5.fetch() |
其中,A1与A2中的序表分别如下:
此时,A6中,对齐连接后结果如下:
游标中的数据是与普通序表不同的,在连接时,当寻找纽约市所对应的纽约州时,州数据中的游标就已经移到了第32条,在后面的计算中无法再找到之前的记录。这样,就使得大多数的城市无法找到对应的州。由于joinx() 函数中未使用@1和@f选项指定左连接或全连接,仅返回找到对州的城市,数据非常少。
如果先将数据排序,就可以获得比较正常的连接结果了:
|
|
A |
|
1 |
$select * from CITIES order by STATEID |
|
2 |
$select * from STATES order by STATEID |
|
3 |
=A1.cursor() |
|
4 |
=A2.cursor() |
|
5 |
=joinx(A3:City,STATEID;A4:State,STATEID) |
|
6 |
=A5.fetch() |
此时A1中获得的是按州序号排序后的城市数据:
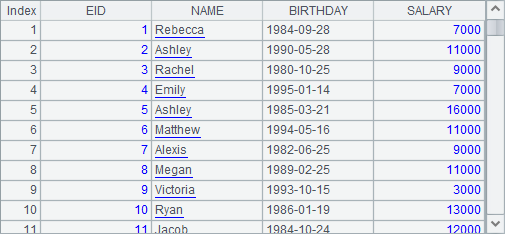
在这种情况下,A6中结果如下:

在将游标中的数据做连接时,并不需要游标的种类相同,如:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t().sortx(State) |
|
3 |
$(demo) select STATEID, NAME, ABBR from STATES order by ABBR |
|
4 |
=A3.cursor() |
|
5 |
=joinx(A2:PersonnelInfo,State;A4:State,ABBR) |
|
6 |
=A5.fetch(100) |
|
7 |
>A5.close() |
在A5中将员工信息与对应的州记录连接。需要注意的是,连接之前要保证游标中的数据完成了排序。A6中获取前100条数据如下:

实际上,在将不同游标中的数据做连接时,往往是为了获取其它游标中的相关信息。如上例中,如果只是为了获取员工所在州的全名,而州数据其实是来自于序表的,那么还可以不将游标中的记录互相做关联,而是选择使用cs.switch(),将游标cs中的某个字段做对应的记录转换。关于在游标中使用switch的方法,可以阅读游标使用。使用joinx()与cs.switch()的不同之处在于,joinx()是将游标中的数据相互连接,而cs.switch()是将序表或序列作为维表,与游标中的字段做外键式关联。由于joinx()是游标之间的运算,因此要求游标中的数据对于连接字段是有序的。而cs.switch()使用的维表都存储在内存中,因此不要求有序。
除了将游标中的数据做连接,在集算器中还可以用游标与可分段集文件来做连接:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t(ID,Name,City,State) |
|
3 |
$(demo) select * from STATES order by ABBR |
|
4 |
=file("StateFile.btx") |
|
5 |
>A4.export@b(A3;ABBR) |
|
6 |
=A2.joinx(State,A4:ABBR,NAME:SName,CAPITAL:SCapital;10000) |
|
7 |
=A6.fetch(100) |
|
8 |
>A6.close() |
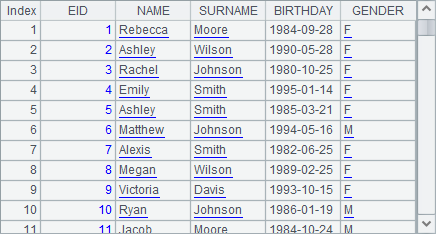
在A5中用数据库中的州信息生成可分段集文件StateFile.btx,注意集文件需要按照连接时所需使用的键来排序,在这个例子中集文件对ABBR字段是有序的。在A6中,用函数cs.joinx(C:…, f:K:…, x:F,…;…;n)来将游标与集文件连接。连接时,用游标cs的字段C:…与集文件f的键K:…匹配,从而从集文件中找到对应的记录,并用记录计算出表达式x的结果作为字段F添加到游标中。最后的参数是缓冲区行数,用来设定计算中使用缓存文件的最大行数。使用cs.joinx()时只需要求集文件有序,对游标中的数据没有顺序要求。具体到上面的例子中,A6中的函数用来根据员工所在州的简称,从州数据集文件中找到对应的州记录,并从中取出州的全称和首都,在游标中生成两个新的字段SName和SCapital。A7中获取前100条数据如下:
有的时候,在处理外键式关联时,需要用多个外键字段联合起来,对应一个序表或者游标中的数据,此时可以用cs.join()来用连接的方式添加字段。如:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t() |
|
3 |
$(demo) select STATEID, NAME,ABBR from STATES |
|
4 |
=create(Month,State,GroupID) |
|
5 |
>A3.(12.((m=~,A4.insert(0,m,A3.ABBR,A3.ABBR+string(m))))) |
|
6 |
=A2.join(month(Birthday):State,A4:Month:State,GroupID:Group) |
|
7 |
=A6.fetch(100) |
|
8 |
>A6.close() |
A4中根据月份及州的简称创建序表,A5填入数据后,A4中序表如下:

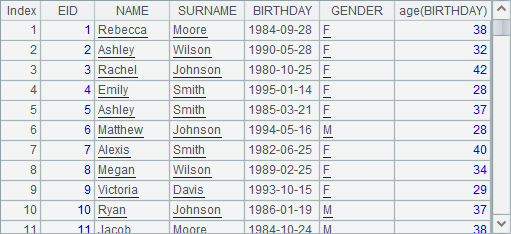
在A6中,通过连接的方式,在游标A2中添加字段,添加时,用A2游标中的员工生日月份及State,和序表A4中的Month及State做等值连接,连接后,取出A4序表中的GroupID字段添加到结果中的State字段中。从A7中读取前100条结果如下:
在使用cs.join()时,可以用序表与cs的字段连接,与joinx()不同,使用cs.join()时并不要求cs中的数据有序。本例中,需要将cs中的两个字段与维表做连接,这种情况是无法用cs.switch()解决的。