
虚表
本节内容,涉及功能只有企业版集算器才可使用,其它版本的产品用户可以跳过。
组表中的数据除了直接访问来使用之外,还可以通过定义虚表来使用,虚表并非事实表,而是通过定义的情况从组表中获取数据的。虚表目前只在集算器企业版中支持。
虚表的基本使用
为了说明虚表的使用,下面先生成三个组表,一个是员工表,包括员工ID,部门ID,性别,是否已婚,以及姓名,其中性别与是否已婚再合并用一个字段Bools存储;另两个是订单表,包括销售员ID,订单编码,签单时间以及订单金额,生成数据时使用的代码如下:
|
|
A |
B |
|
1 |
=demo.query("select NAME, SURNAME, GENDER, STATE from employee") |
|
|
2 |
=A1.select(GENDER=="M") |
=A1\A2 |
|
3 |
=A2.(NAME).id() |
=A3.len() |
|
4 |
=B2.(NAME).id() |
=A4.len() |
|
5 |
=A1.(SURNAME).id() |
=A5.len() |
|
6 |
=A1.(STATE).id() |
=A6.len() |
|
7 |
[Sales,Technology,R&D,Financial,Admin] |
[0,0.5,0.75,0.9,0.97,1] |
|
8 |
=to(1000).new(#:EID, B7.pseg(rand()):DeptID, if(rand()<0.5,0,1):Gender, if(rand()>0.8,1,0):Married, if(Gender==0,A3(rand(B3)+1), A4(rand(B4)+1))/" "/A5(rand(B5)+1):Name, bits(Gender, Married):Bools ) |
>file("pseudo/emps.btx ").export@b(A8) |
|
9 |
=A8.select(DeptID==1) |
=A9.len() |
|
10 |
2024-01-01 |
2025-01-01 |
|
11 |
=periods@x(A10,B10) |
=periods@x(B10,elapse@y(B10,1)) |
|
12 |
=A11.((a=string(~,"yyMMdd"), to(rand(100)+ 10).new(A9(if(rand()>0.9, rand(B9)+1, rand(B9-20)+ 21)).EID:SID, a/string(#, "0000"):OID, datetime(A11.~, time(rand(8)+8, rand(60), 0)):OTime, rand(100)*10+200:Amount))).conj().sort(SID, OID) |
|
|
13 |
=B11.((a=string(~,"yyMMdd"), to(rand(100)+ 10).new(A9(if(rand()>0.9, rand(B9)+1, rand(B9-20)+ 21)).EID:SID, a/string(#, "0000"):OID, datetime(B11.~, time(rand(8)+8, rand(60), 0)):OTime, rand(100)*10+200:Amount))).conj().sort(SID, OID) |
|
|
14 |
=file("pseudo/emps.ctx") |
=A14.create(#EID,DeptID,Gender, Married, Name, Bools) |
|
15 |
|
>B14.append@i(A8.cursor()) |
|
16 |
=file("pseudo/1.orders.ctx") |
=file("pseudo/2.orders.ctx") |
|
17 |
=A16.create(SID, #OID, OTime, Amount) |
>A17.append(A12.cursor()) |
|
18 |
=B16.create(SID, #OID, OTime, Amount) |
>A18.append(A13.cursor()) |
|
19 |
>B14.close() |
|
|
20 |
>A17.close() |
>A18.close() |
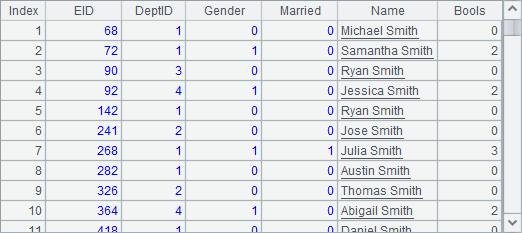
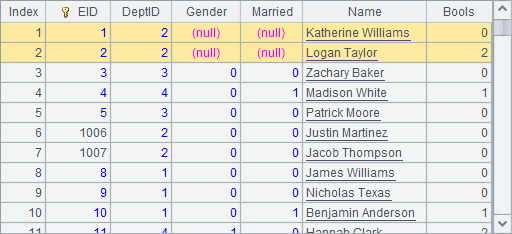
这里准备的数据量并不太大,在Gender字段中,0表示男性,1表示女性;Married字段中,0表示未婚,1表示已婚。A8中得到的员工表数据如下:
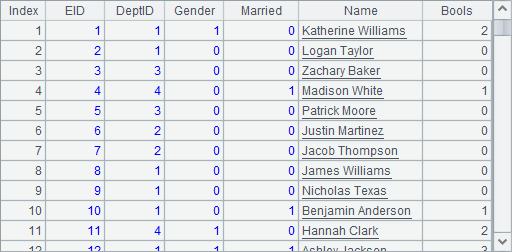
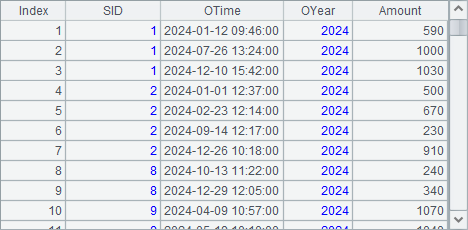
A12和A13中构建的2024和2025年度的订单表数据如下:
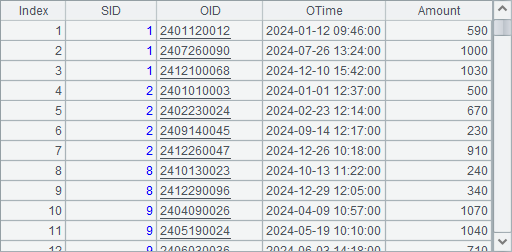
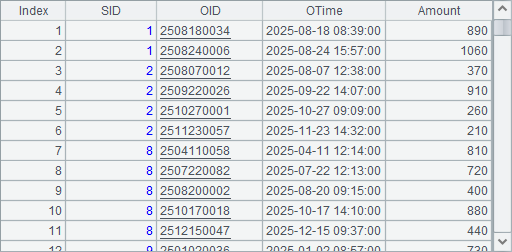
上面的3个表数据分别存储在pseudo路径下的emps.ctx, 1.orders.ctx和2.orders.ctx这3个组表文件,以及集文件emps.btx中,其中后两个组表用来构成复组表。将以它们为例讲解如何定义及使用虚表。在使用前,可以将它们备份,以防止在后续的测试使用中数据被修改。
|
|
A |
B |
C |
|
1 |
=create(file).record(["pseudo/emps.ctx"]) |
=pseudo(A1) |
=B1.cursor().fetch@x(100) |
|
2 |
=create(file, zone).record(["pseudo/orders.ctx", [1,2]]) |
=pseudo(A2) |
=B2.import() |
虚表的定义记录是一个有指定结构的序表记录,最简单的虚表定义记录必须有file字段来定义虚表的数据来源。如上面例子中,A1中的虚表定义记录如下:
![]()
虚表的数据来源推荐使用ctx组表文件。
使用这个记录,可以用pseudo(pd)来产生虚表定义,其中pd即为虚表定义记录。B1中即为产生的虚表定义:
![]()
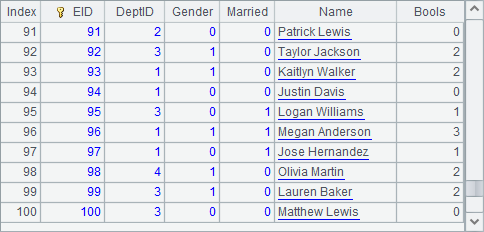
虚表定义的使用和组表类似,可以用T.cursor()产生游标来使用,或者用T.import()直接读取全部数据。C1中用游标读取前100条数据,结果如下:
除了使用单一的数据文件构成虚表,也可以使用复组表文件构成虚表。如A2中的虚表定义记录如下:
![]()
C2从虚表中获取到的数据如下:
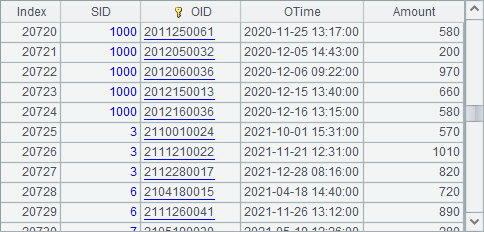
可以看到,使用复组表文件时,数据会按照各个分表的顺序,顺次获取。
使用虚表时,可以用delete/update/append等函数删除/更新/添加表中的记录,数据变动时会直接修改对应的组表文件,如:
|
|
A |
B |
|
1 |
=create(file).record(["pseudo/emps.ctx"]) |
=pseudo(A1) |
|
2 |
=B1.select(DeptID==2 && EID<10) |
=A2.import() |
|
3 |
>B2.run(DeptID=0) |
=B1.update(B2) |
|
4 |
=B1.import() |
=A2.import() |
|
5 |
>B2.run(DeptID=2, EID=EID+1000) |
=B1.update(B2) |
|
6 |
=B1.import() |
|
虚表可以类似组表一样,用T.select()函数筛选其中的数据,A2中选出DeptID为2且EID小于10的员工数据,B2中用T.import()读取如下:

A3中把这些员工记录的DeptID字段改为0,并在B3中用T.update(P)函数将修改后的排列P中的记录更新到虚表中。使用update函数对虚表进行更新操作时,虚表对应的组表必须定义维,对虚表的维护操作都是针对组表的维执行的。更新后,A4和B4中得到的数据如下:
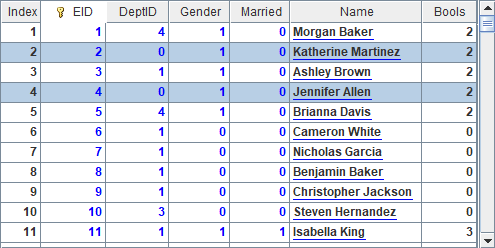

可以看到,对应的记录已经被修改了。修改后的数据不满足B2中的筛选条件,因此B4中获取的排列中没有记录。
A5中将B2中结果中两位员工的DeptID改回原值,同时把EID增加1000,并用T.update()函数更新到虚表中,A6中结果如下:
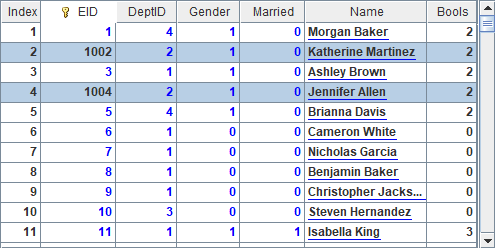
如果更新记录中主键的值,可能会无法保持数据所在组表中的维有序,使得虚表无法正常更新。
除了组表,也可以用集文件生成虚表访问,使用集文件生成虚表时,使用方法和用组表生成虚表时完全一致,如:
|
|
A |
B |
|
1 |
=create(file).record(["pseudo/emps.btx"]) |
=pseudo(A1) |
|
2 |
=B1.cursor().fetch@x(100) |
|
|
3 |
=B1.select(like(Name, "*Smith")) |
=A3.import() |
A2中用游标访问虚表,结果如下:
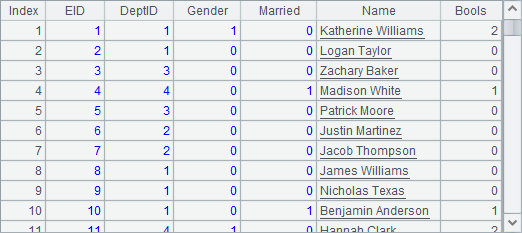
A3中从虚表中选择出姓为Smith的员工,B3结果如下:
用集文件生成虚表时,不能类似复组表来使用。
虚表的归并
数据在复组表文件中,常常是基于不同用户去存储和使用的,如上面的销售记录是分为不同销售员存储的,在这种情况下,在分组处理时会按照首字段处理,如:
|
|
A |
|
1 |
=create(file,zone).record(["pseudo/orders.ctx", [1,2]]) |
|
2 |
=pseudo(A1) |
|
3 |
=A2.import() |
|
4 |
=A2.group(year(OTime)).import() |
|
5 |
=A4.new(year(OTime):Year,~.sum(Amount):Total) |
|
6 |
=A2.groups(SID, year(OTime):Year;~.sum(Amount):Total) |
A1中的虚表定义记录如下:
![]()
数据文件中取数时会按照各个分表依次获取,A3中获取到数据如下,这个其实在上一节中已经展示过了:
A4中按照订单年份执行分组,结果如下:
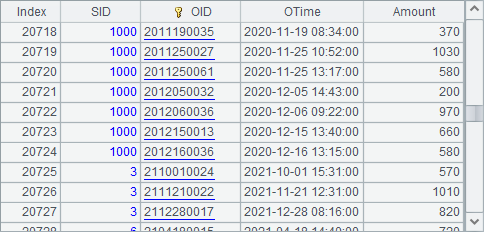
可以看到,分组时会按指定字段或者表达式执行处理。为了更直观地理解,根据分组后情况在A5中统计销售总额,结果如下:

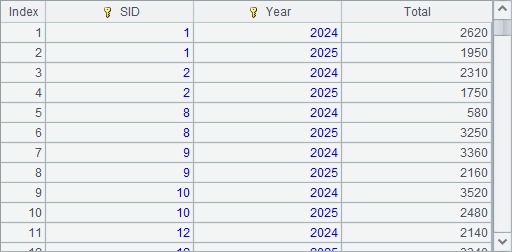
也可以用T.groups()函数执行分组汇总计算,注意使用了SID和订单年份两层分组, A6中结果如下:
从上面的例子可以看到,在复组表中获取数据时,会根据首字段来在各个分表中分段取数,再执行归并后得到结果。但是,按首字段分段时,有些情况下数据的分布可能不平均,或者每个分组的数据量较少。如上面的例子中,前20个销售员的订单就会比较少,其实其他各位销售人员的数据也不是很多,在取数时就可能由于分段数据较少或者分段数太多,在归并时频繁在各个分表中切换获取数据,造成在各个分表中取数的效率降低。为此,可以重新构造数据,将首字段设为更“大”的分组,使取数时效率更高,如:
|
|
A |
B |
|
1 |
=demo.query("select distinct(NAME) from CITIES") |
=A1.(NAME) |
|
2 |
=create(file,zone).record(["pseudo/orders.ctx", [1]]) |
=pseudo(A2).import() |
|
3 |
=create(file,zone).record(["pseudo/orders.ctx", [2]]) |
=pseudo(A3).import() |
|
4 |
=B1.len() |
=1000.(B1(rand(A4)+1)) |
|
5 |
=B2.new(B4(SID):City, SID, OID, OTime, Amount) |
=B3.new(B4(SID):City, SID, OID, OTime, Amount) |
|
6 |
=A5.sort(City) |
=B5.sort(City) |
|
7 |
=file("pseudo/1.orders2.ctx") |
=file("pseudo/2.orders2.ctx") |
|
8 |
=A7.create(City, SID, #OID, OTime, Amount) |
>A8.append(A6.cursor()) |
|
9 |
=B7.create(City, SID, #OID, OTime, Amount) |
>A9.append(B6.cursor()) |
原有的订单数据中是没有城市数据(City)的,上面的测试数据中,为销售人员增加了City数据,并将订单数据按照City, SID和OID的顺序依次做了排序,然后将数据存入了复组表orders2.ctx中。在实际使用中,这样用来初步分组的首字段可能是人员所在城市,所在部门,或者是交易的类型编码,订单的支付银行等等之类信息。整理数据时,记录需要按照首字段排序。
下面看一下使用orders2.ctx作为虚表的查询情况:
|
|
A |
B |
|
1 |
=create(file,zone, date).record(["pseudo/orders2.ctx", [1,2], "OTime"]) |
=pseudo(A1).import() |
A1中的虚表从复组表中取数,数据将按首字段归并,B1中结果如下:
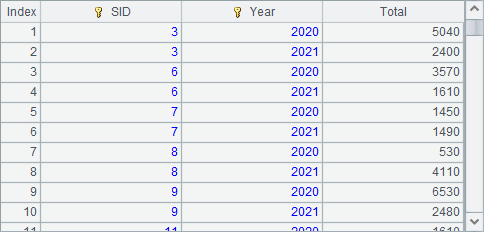
此时取出的数据,会按照复组表orders2.ctx中的首字段City归并,同样会把两年的数据归并在一起,但是并不会按照销售员执行归并处理了。
用户定义字段
除了使用原始数据表中的字段,还可以在虚表定义记录中,添加column字段,定义一些用户定义字段,如:
|
|
A |
|
1 |
[Sales,Technology,R&D,Financial,Admin] |
|
2 |
=create(name,enum,list).record(["DeptID","Dept",A1]) |
|
3 |
=create(name,bits).record(["Bools",["IfMarried","IfLady"]]) |
|
4 |
=create(file,column).record(["pseudo/emps.ctx",A2|A3]) |
|
5 |
=pseudo(A4) |
|
6 |
=A5.select(Dept=="Sales").import() |
|
7 |
=A5.import(EID, Name, DeptID, Dept) |
|
8 |
=A5.select(!IfLady && IfMarried).import() |
|
9 |
=A5.import(EID, Name, Gender, IfLady,Married,IfMarried) |
这个例子中定义了两个用户定义字段,A2中是Dept字段:
![]()
column定义记录中,name字段是字段的名称,如果是原始数据表中的字段,称为真字段,除此之外还可能是其它列生成的伪字段。如果需要把真字段DeptID转换为对应的部门名称,这样的伪字段是枚举伪字段,在column记录中用enum字段定义枚举伪字段的名称,部门转换时需要把对应的数据转换为序列中的值,转换时对应的取值序列需要在list列中设置,转换时将把对应的编号转换为对应的值,位置从1开始。
A3中定义了另一个用户定义字段,原始数据表中,Bools字段存储了2个二值型字段的数据,性别和是否已婚。A3中字段定义记录如下:
![]()
定义时需要从中读出各个位对应的二值字段,这里Bools对应的伪字段称为二值维度伪字段,二值维度伪字段的名称在column记录中用bits字段定义。伪字段的名称不能和原始字段重名,这里使用IfMarried和IfLady,定义时按照Bools中从低位到高位对应的字段来设置,各个字段的值都是布尔值true或者false,一个二值维度伪字段最多可以存储32个二值字段。
在A4中定义虚表,设置了数据文件file和字段定义column,如下:
![]()
A5中使用这个定义记录生成虚表,在这个虚表中,就可以使用定义的column了。如A6中使用枚举伪字段Dept来筛选出销售部员工如下:
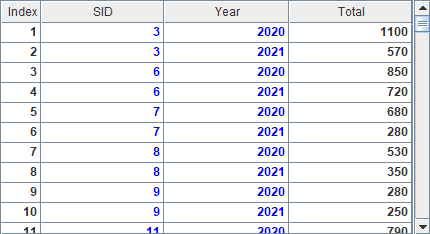
使用T.import()查看虚表中的数据时,并不能看到伪字段中的数据,只能看到初始字段,但是可以很明显看到根据伪字段执行的筛选成功执行了,这些员工对应的DeptID都是1。
如果想查看伪字段的数据,需要在import中直接指明字段,如A7中查询结果如下:
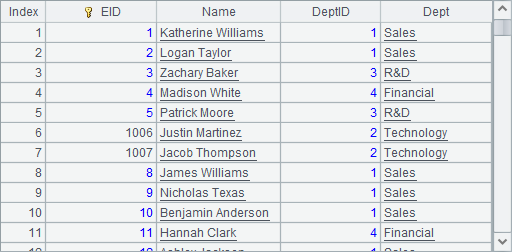
从这个结果中能够更明确的看到枚举伪字段与对应真字段数据间的对应关系。
A8中使用二值维度伪字段执行筛选,选出已婚男员工的数据,结果如下:
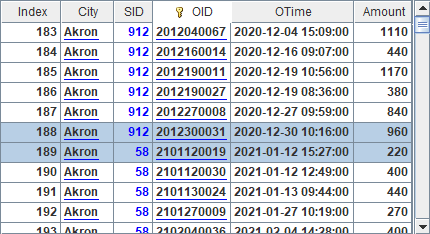
同样,二值维度伪字段查询时也必须指明列名,如A9中结果如下:

虚表使用用户定义字段时,同样可以用update函数对虚表进行更新操作,如:
|
|
A |
|
1 |
[Sales,Technology,R&D,Financial,Admin] |
|
2 |
=create(name,enum,list).record(["DeptID","Dept",A1]) |
|
3 |
=create(name,bits).record(["Bools",["IfMarried","IfLady"]]) |
|
4 |
=create(file,column).record(["pseudo/emps.ctx",A2|A3]) |
|
5 |
=pseudo(A4) |
|
6 |
=A5.select(EID<8) |
|
7 |
=A6.select(Dept=="Sales").import(EID,Name,Dept,IfMarried,IfLady) |
|
8 |
>A7.run(Dept="Technology", IfLady=!IfLady) |
|
9 |
>A5.update(A7) |
|
10 |
=A5.import(EID,Name,Dept,IfMarried,IfLady) |
|
11 |
=A5.import() |
虚表中使用了枚举伪字段和二值维度伪字段,在A7中筛选出EID小于8的销售部员工资料如下:

在A8中修改这些员工的部门和性别,并在A8中执行对虚表的更新。更新执行后,在A10中读取更新后的虚表数据,注意这2条记录中Dept字段和IfLady字段都被修改了:
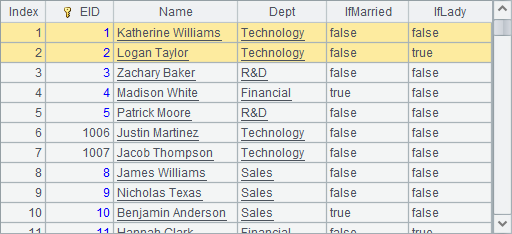
在A11中,可以看到虚表使用的组表文件中,数据实际被修改的情况:
可以看到,在修改虚表中伪字段的值时,会自动根据它们的值,倒算出实际对应的数据,更新到组表中。由于更新时使用的字段是Bools,而并没有作为参考的Gender/Married等字段,因此这两个字段在更新后变为了空值。
除了枚举伪字段,原始数据表中还可以使用普通伪字段,如:
|
|
A |
|
1 |
=create(name,alias,exp).record(["OTime",["OYear"],"year(OTime)"]) |
|
2 |
=create(file,zone,column).record(["pseudo/orders.ctx",[1],A1]) |
|
3 |
=pseudo(A2) |
|
4 |
=A3.import(SID, OTime, OYear, Amount) |
A1中添加用户定义字段:
![]()
这里定义的OYear是一个伪字段,由真字段OTime计算获得。在column记录中用name字段定义真字段,alias字段定义伪字段名称,exp字段定义表达式。
A2中的虚表定义记录如下:
![]()
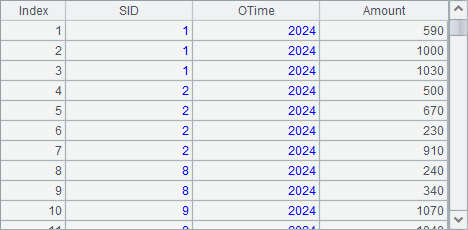
A4中从虚表中获取数据如下,可以看到其中的伪字段OYear:
如果定义虚表的时候不用伪字段名,即将A1中代码改为:=create(name,exp).record(["OTime","year(OTime)"]),则会将exp计算的结果直接用来替换真字段的值,修改后A4中将返回:
除了使用文件构成虚表,还可以用内存中的序表/内表/集群内表等构成虚表,此时定义虚表结构时不使用file指定文件名,而是用var字段来指定内存表存储的变量名,如:
|
|
A |
|
1 |
>tab=demo.query("select * from CITIES") |
|
2 |
=create(var).record(["tab"]) |
|
3 |
=pseudo(A2) |
|
4 |
=A3.select(STATEID==3) |
|
5 |
=A4.import() |
A1中从数据库中获取CITIES表并将序表存储到变量tab,A2使用内存表来定义虚表。A4中从虚表中获取STATEID为3的城市资料,A5中得到的结果如下:
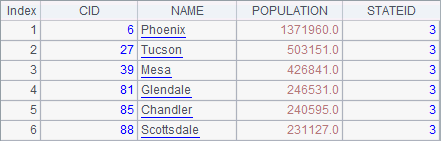
使用内存表定义虚表时,虚表的使用与其它虚表是没有区别的。