
新建与引出
在集算器中,序表的使用非常频繁,除了直接从数据库中读取序表之外,还可以根据序列或序表中的数据,用new函数生成新序表,也可以用derive函数在已有的排列或序表中添加列引出新序表。
由已有的数据新建序表
根据已有的序列或序表中的数据,可以用A.new() 函数来新建序表,如:
|
|
A |
|
1 |
[1,2,3,4,5] |
|
2 |
$(demo) select * from EMPLOYEE |
|
3 |
=A2.select(STATE=="Texas") |
|
4 |
=A1.new(~,~*~,~*~*~) |
|
5 |
=A2.new(EID,NAME+" "+SURNAME,GENDER,age(BIRTHDAY)) |
|
6 |
=A3.new(EID,NAME+" "+SURNAME,GENDER,STATE) |
A1中是个简单的序列,A2中是从数据库中获取的员工信息序表,A3是从A2中选出的Texas州员工记录构成的序列。A4~A6分别根据序列、序表和排列,用new函数新建序表。
A4中序表如下:
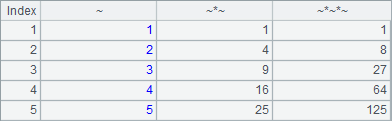
A5中序表如下:
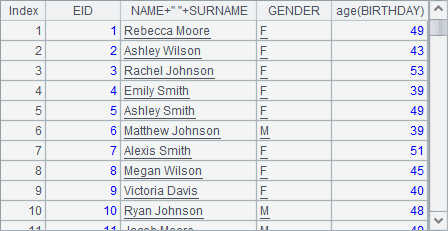
A6中序表如下:
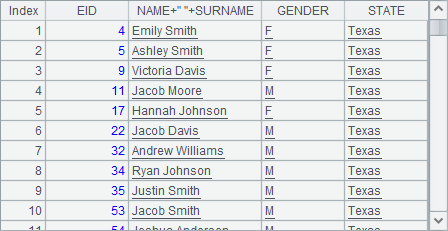
从以上结果中可以发现,A.new() 函数在计算时,循环A中的每一个成员,计算表达式,得到记录填入到新序表中。在new函数中,可以引用A中的成员,当A是序列或排列时,还可以使用记录的字段值来计算。在默认情况下,新序表的字段名即为生成时使用的表达式,如age(BIRTHDAY)。如果新序表中的字段完全来自旧的序表,在没有为新字段命名的情况下,会使用旧的字段名,如EID和GENDER,其实它们也是生成字段时使用的表达式。在新建序表时,可以只取出需要的数据来生成新序表中的记录。
当新序表的字段名使用表达式时,往往不便于使用,因此,通常需要在新建序表时为字段命名。如:
|
|
A |
|
1 |
[1,2,3,4,5] |
|
2 |
$(demo) select * from EMPLOYEE |
|
3 |
=A2.select(STATE=="Texas") |
|
4 |
=A1.new(~:Value,~*~:Square,~*~*~:Cube) |
|
5 |
=A2.new(EID,NAME+" "+SURNAME:FullName,GENDER, age(BIRTHDAY):Age) |
|
6 |
=A3.new(EID,NAME+" "+SURNAME:NAME,GENDER,STATE) |
A4,A5和A6中的结果分别如下:
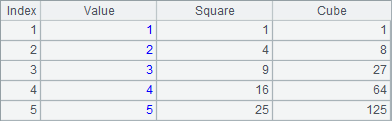
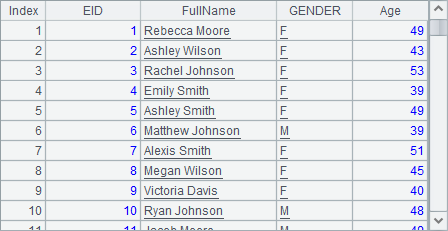
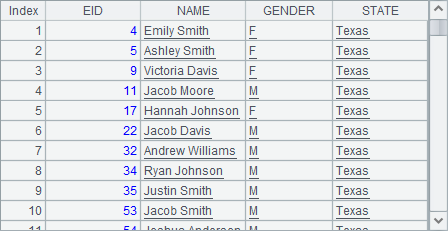
可以发现,使用new函数时,如果要为新字段命名,只要在对应字段的生成表达式后面,添加字段名就可以了,与表达式用冒号隔开,如NAME+" "+SURNAME:FullName,表示由原序表中记录的NAME和SURNAME字段,计算出员工的全名,在新序表的该字段命名为FullName。
另外,如果是根据连续的数字构成的序列生成新序表,如A1中的序列,可以简写为n.new() 的格式,如:
|
|
A |
|
1 |
=5.new(~:Value,~*~:Square,~*~*~:Cube) |
|
2 |
$(demo) select * from EMPLOYEE |
|
3 |
=100.new(A2(~).(NAME+" "+SURNAME):Name,rand(5)+1:Group) |
A1中即为上例A4中表达式的简写,结果和前面是相同的:
A3中同样用数字来循环执行new函数,生成100条记录,将员工表中前100位员工随机分到1~5中的某个分组中,结果序表如下:
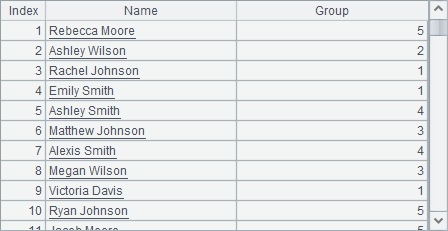
在用new函数新建序表时,表达式中可以使用新序表中的字段,如:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE |
|
2 |
=A1.new(EID,NAME+" "+SURNAME:FullName, FullName[-1]:PREV) |
|
3 |
=A1.new(EID,NAME+" "+SURNAME:NAME) |
|
4 |
= A1.new(EID,NAME+" "+SURNAME:NAME,NAME[-1]:PREV) |
|
5 |
=A1.new(EID,NAME+" "+SURNAME:NAME, NAME[-1]+" "+ SURNAME[-1]:PREV) |
A2中用new函数生成新序表时,先计算出了员工的全名,同时在另一个字段中引用了前一位员工的全名,结果如下:

有时候,新的字段名也可以与原序表中的相同,如A3中计算员工的全名仍然用NAME作为字段名:
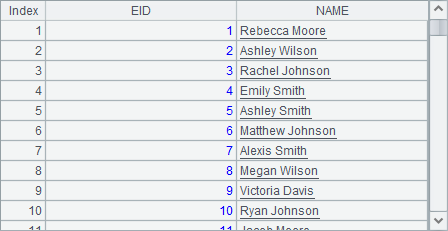
但是,在这种情况下,A4中的代码出现了问题,其中使用NAME[-1]:PREV引用前一位员工的名字,命名为新字段PREV,由于A1中同样存在NAME字段,在解析时,同名字段会优先处理为原序表中的字段,所以A4中得到的结果如下:
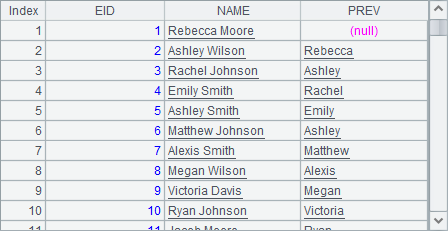
可以发现,A4中只是获得了原序表中员工的名字而不是新计算出的全名。
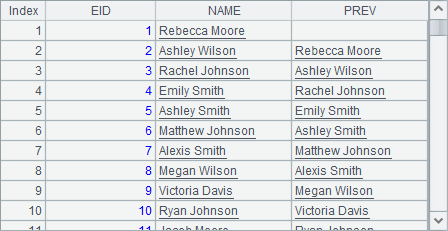
此时,PREV字段只能仍然用A1中的字段来计算,如A5中的方法,结果如下:
使用new函数时,可以添加@i选项,此时,如果执行时某条记录在字段表达式的计算结果中,出现了空值,则这条记录不会添加到新序表中,如:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE |
|
2 |
=A1.new@i (EID,NAME+" "+SURNAME:NAME, if(GENDER=="M","Male"):Gender) |
A2中计算Gender字段时,只将男员工的原值M转换为Male,而女员工的对应值则为空,因此结果中不会出现女员工的数据,A2中结果如下:
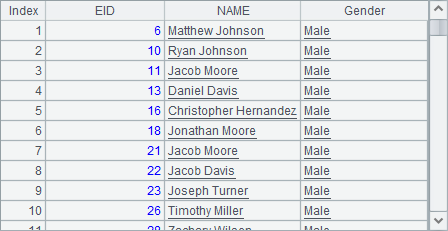
在判断相等关系时,if函数也可以写为case函数,如if(GENDER=="M","Male")相当于case(GENDER, "M":"Male")。
如果在生成数据时,需要针对已有序表的每条记录,或者已有序列的每个成员,在新序表中用同样的规则生成多条记录,可以使用A.news(X; xi:Fi, …) 函数,如:
|
|
A |
|
1 |
[1,2,3,4,5] |
|
2 |
=A1.news(to(10, 15); A1.~:x, ~:y, x*y:x_times_y) |
|
3 |
=A1.news(["Sqare","Cube"]; A1.~:Value, ~:Method, if(#==1, A1.~*A1.~,A1.~*A1.~*A1.~):Result) |
|
4 |
$(demo) select * from EMPLOYEE |
|
5 |
=A4.select(DEPT=="Finance") |
|
6 |
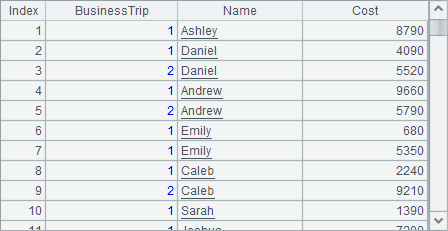
=A5.news(rand(3); ~:BusinessTrip, A5.NAME:Name, rand(1000)*10:Cost) |
A2中用A1序列中的每个数,与另一个数列中的数依次相乘,计算乘法的结果,如下:
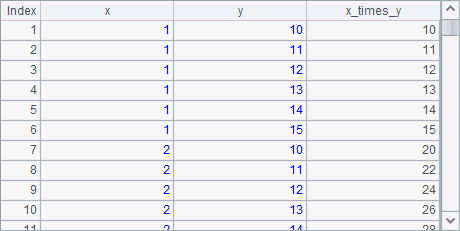
A3中分别计算A1中每个数的平方和立方,生成两条记录,结果如下:
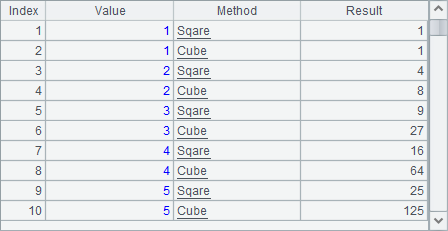
A6中根据A5中财务部的员工数据,生成模拟的出差花销数据,每位员工随机生成0~2条记录,结果如下:
由已有的数据新建序列
在使用已有的序列或排列、序表生成数据时,也可以用循环函数A.(x) 来执行计算。在这里我们了解一下,并比较一下它与A.new() 的不同。如下:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE |
|
2 |
=A1.(NAME+" "+SURNAME) |
|
3 |
=A1.( age(BIRTHDAY)) |
|
4 |
=5.([~,~*~,~*~*~]) |
A2与A3中的计算结果如下:
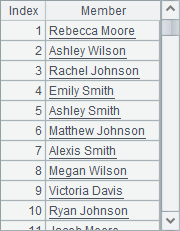
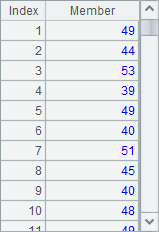
可以看到,用循环函数A.(x) 时,结果是序列而不是序表,因此一般情况下每次只能计算单一的结果。
如果需要计算多个数据,可以类似A4中的代码,用多个结果构成序列,A4中结果如下:
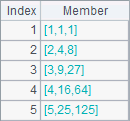
由序列或排列引出新序表
有时并不需要重新生成序表,而只需在已有数据中添加所需内容,此时可以使用derive函数在序表或排列上添加计算字段,生成新序表。如:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(age(BIRTHDAY)) |
|
3 |
=A2.derive(NAME+" "+SURNAME:FullName) |
|
4 |
=A1.derive(:FullName) |
A1中的原序表数据如下:
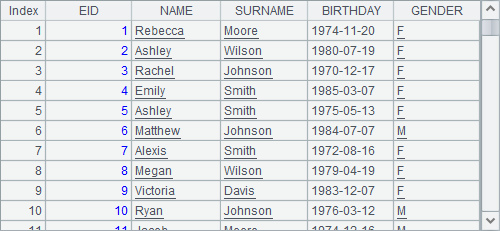
A2用derive函数由A1引出新序表,添加了员工年龄字段,结果如下:
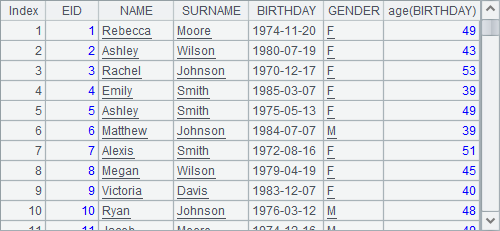
可以看到,在A1原有的字段基础上,又添加了根据BIRTHDAY字段计算出的年龄字段,而新字段未命名,使用生成表达式age(BIRTHDAY)作为字段名。另外,derive函数实际上可以看为new函数的简化写法,在执行时会生成新序表。因此A2中生成新序表,而A1中的序表并不会受影响。
A3根据A2中的结果,又添加了员工的全名字段,结果如下:
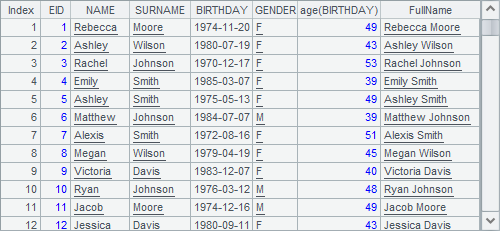
可以看到,A2的序表中所有字段都被复制,只是在最后添加了新字段。在A3的表达式中,将新字段命名为FullName。同样,A3中的计算不会影响A2中的结果。
在A4中,重新使用A1作为原序表,添加字段时,只将其命名为FullName,而没有生成表达式,结果如下:
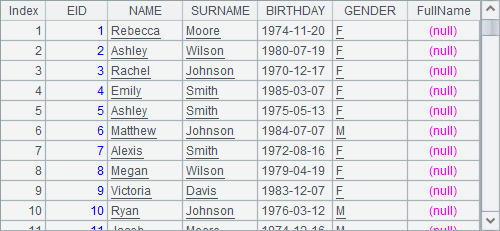
可以发现,如果没有生成的表达式,会生成空字段返回。
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(age(BIRTHDAY),NAME+" "+SURNAME:FullName) |
|
3 |
=A1.derive(age(BIRTHDAY):Age,string(Age)+GENDER:Group) |
在使用derive函数时,也可以一次添加多个字段,在这个例子中,A2的结果如下:
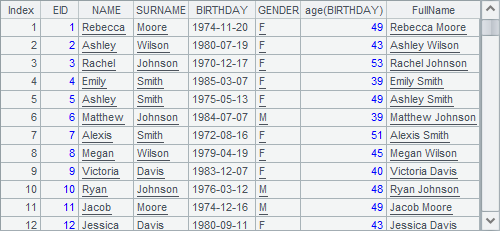
它和上面例子中分步添加字段的结果是相同的。
在A3中,添加了年龄字段,以及用年龄和GENDER字段计算出的分组代码,结果如下:

A3的表达式中,不但一次添加了2个字段,而且第2个字段Group中还引用到了新加的字段Age中的数据,在derive函数中,后生成的字段是可以使用已生成的字段的。还有一点需要注意的是,在集算器中,如果需要将实数与字符串连接,需要先将实数转化成字符串。
需要注意的是,derive函数并不是单纯添加一列,它和new函数同样需要新建序表,因此在执行时,会在新的序表中重建每一条记录。因此,derive函数和new函数的执行效率并不太高,在需要添加多个字段的情况下,仅执行一次derive,效率会明显更高。所以,A2中的执行方案,要比上例中分步添加的方案更好。即使有些数据在最初无法确定,也可以在执行derive函数时先生成空字段,在后面的程序中用A.run() 函数再次赋值。如:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(age(BIRTHDAY),:FullName) |
|
3 |
>A2.run(FullName=NAME+" "+SURNAME) |
这样的处理方案,由于不必重新生成序表中的记录,仅需要赋值,要比分两步derive的效率更高些。
与new函数类似,使用derive函数时,也可以添加@i选项,当用表达式计算所添加的列时,如果其中出现空值则不添加对应的记录。
新建与引出的连续使用
在生成新序表时,有时我们需要添加一些计算列,同时并不需要原序表中的其它所有字段,或者需要调整生成序表中字段的顺序。此时可以将new函数和derive函数连续使用。如:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName).new(EID,FullName,GENDER, BIRTHDAY) |
|
3 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
4 |
=A3.new(EID,FullName,GENDER,BIRTHDAY) |
我们根据A1中,员工的NAME和SURNAME计算出FullName,此时NAME和SURNAME就不再需要了。同时字段的顺序也需要整理,如derive生成的字段总在最后,但是想将FullName前移。因此在A2中,将derive函数与new函数配合使用。A2中结果如下:
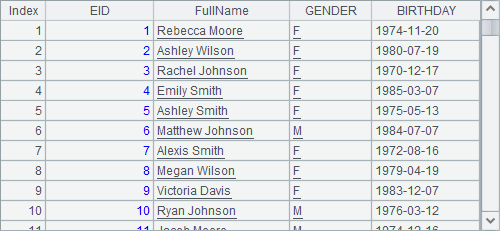
A2相当于A3和A4中分步执行的情况。因此,在连续使用时,new函数实际上是在derive的结果中执行的,如A3中的情况:
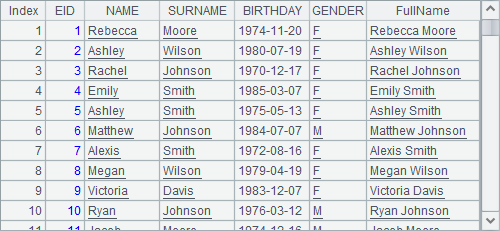
因此在new函数中,可以引用最初序表中的字段如EID,也可以引用derive生成的新字段FullName。
在连续使用时,先用derive函数添加字段,再用new函数整理结果,这样的使用更为常见。但是,先用new函数整理出需要的字段,再用derive函数生成计算字段也是可以的,如:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.new(EID,NAME+" "+SURNAME:FullName,GENDER, age(BIRTHDAY):Age).derive(string(Age)+GENDER:Group) |
在这个例子中,Group字段需要使用新增的Age字段来计算,因此在A2中先用new函数初步整理序表,再用derive函数计算Group字段,A2中结果如下:
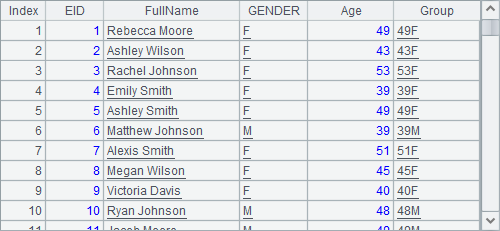
需要明确的是,此时derive函数是在new的结果中计算的,此时不能再引用初始的A1序表中的数据,如NAME,SURNAME等。