
修改序表
序表在集算器中很常用,在数据分析与计算中,经常需要在序表中增删记录,或者修改序表中的数据。在这里,我们将从增加记录、删除记录、修改记录、重置序表、增加字段等几个方面了解序表的修改与维护,同时了解在排列中处理相应操作时有什么差别。
增加记录
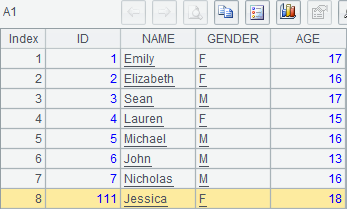
下面的网格中,在序表A1中追加1条记录r1,然后在第2行插入1条记录r2,其中r1依次设定字段值,r2指定字段名称设定字段值;最后再在第2行起插入3条记录r3,r4和r5,这些记录ID和NAME字段有值,其他字段为空:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.insert(0,111,"Jessica","F",18) |
|
3 |
>A1.insert(2,25:ID,"William":NAME,20:AGE,"M":GENDER) |
|
4 |
>A1.insert(2:3,25+#:ID,"William"+string(#):NAME) |
A1中的序表,在A2,A3,A4中陆续添加记录。在工具栏中点击![]() 分步执行,可以看到A1中的序表变化如下:
分步执行,可以看到A1中的序表变化如下:
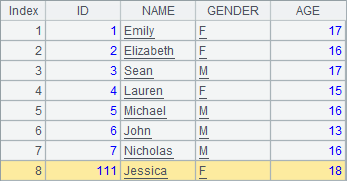
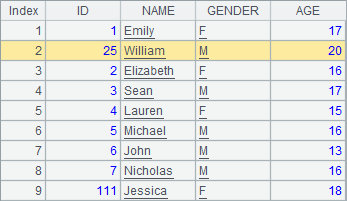
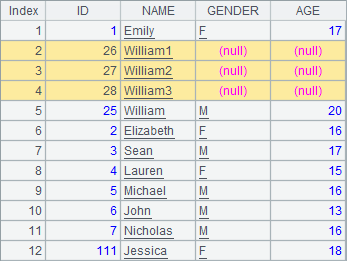
可以看到,在序表中添加记录,都是使用T.insert() 函数,可以指定记录的插入位置,也可以设定新值的字段,未设定的字段值为空。
排列和序表不同,实际上是记录引用构成的序列,因此在排列中只能加入新的记录引用:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=A1.to() |
|
3 |
>A1.insert(0,111,"Jessica","F",18) |
|
4 |
>A2.insert(2, A1(8)) |
A2中的排列是用to函数,由A1中序表的记录构成的,如果需要复制成序表,需要使用A.derive() 函数。A1和A2中的数据,和上面例子中A1中的序表是相同的。仍然分步执行网格程序,在A3中的代码执行后,A1与A2中的数据分别如下:
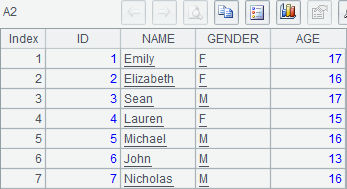
可以看到,序表中增加了记录,但是已有的记录并未有修改,因此A2中的排列不受影响。A4中将新加的记录添加到排列中,而插入的位置与序表并不相同,执行后,A2中排列如下:
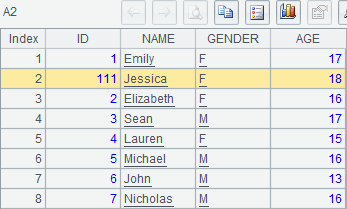
序表和排列新增记录时语法相差较大。序表新增的是实体记录,在序表A1上直接使用insert函数就可以。排列只能新增记录的引用,必须先有实体记录才能引用,例子中的实体记录存在于A1中(也可以是其它序表中的记录,但是同一排列中的记录应该保持结构相同,否则有可能出现计算错误)。
insert函数的第一个参数为0时表示在结尾追加记录,不为零时表示在指定位置插入,这个规则对序表和排列都一样。
在序表中增加记录时,还可以使用已有排列或序表中的数据,如:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=create(ID, NAME, GENDER, AGE) |
|
3 |
>A2.insert(0:A1([1,2]), ID, NAME, GENDER, AGE) |
|
4 |
>A2.insert@r(1:A1) |
A2中新建序表。在A3中在序表的最后位置添加数据,数据来自于A1中记录构成的排列。当使用数据结构相同的排列数据增加记录时,可以不必在表达式中写明字段,而是简化为T.insert@r(k:P),如A4中在A2序表的第2条记录之前再插入A1中的全部记录数据。执行后,A2中数据如下:
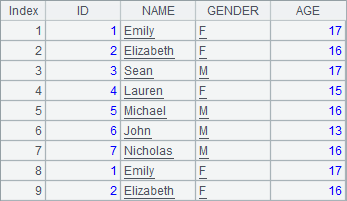
当使用已有排列中数据在序表中增加记录时,如果两者数据结构不同,可以使用T.insert@f(k:P)按字段增加记录,此时只有两者共有字段的值会被加入新记录中,如:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=create(ID, NAME, SEX, AGE) |
|
3 |
>A2.insert(0:A1([1,2]), ID, NAME, GENDER:SEX, AGE) |
|
4 |
>A2.insert@f(2:A1) |
A2中序表的字段名与A1不同。在A3中在序表的最后位置添加数据,数据来自于A1中记录构成的排列,并指明每个字段对应的数据。A4中使用T.insert@f()增加记录。执行后,A2中数据如下:
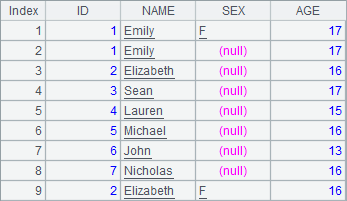
可以看到,用于A4中使用的是T.insert@f()增加记录,执行它添加的记录中,只有字段名相同的值会被复制,而A2中字段名不同的会保留空值。
删除记录
在下面的网格中,先删除第2行的记录,再删除第1,2两行记录,最后再删除其中年龄大于15岁的学生记录:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.delete(2) |
|
3 |
>A1.delete([1,2]) |
|
4 |
>A1.delete(A1.select(AGE>15)) |
A1中的序表,在A2,A3,A4中陆续添加记录。分步执行后A1中的序表变化如下:
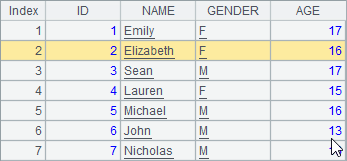
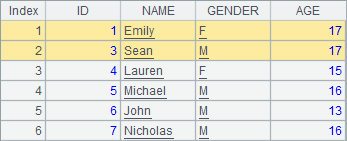
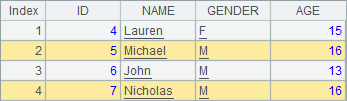

在序表中删除记录时,使用delete函数,可以指定序号,也可以指定序号序列,还可以从序表中删除排列中的所有记录。A4中的代码也可以用>A1.delete(A1.pselect@a(AGE>15)),效果是相同的。
再来看排列中的情况:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=A1.to() |
|
3 |
>A2.delete(2) |
|
4 |
>A2.delete([1,2]) |
A2中的排列与上例中序表中的初始数据相同,A3和A4中依次删除1条和2条记录,分步执行可以发现A2中排列变化如下:
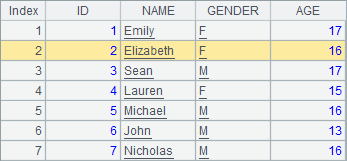
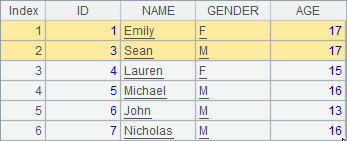
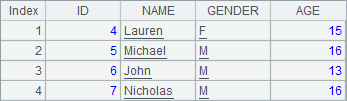
而查看A1中的数据可以发现,序表中仍然是初始数据:
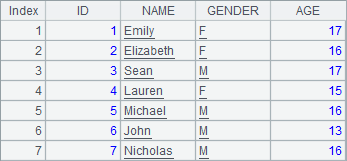
序表中被删除的是实体记录;排列中被删除的是记录引用,并不会影响原序表。
修改记录
下面的网格中,先将第2条记录的GENDER字段修改为Female,NAME字段修改为Violet;再讲第2条起的连续3条记录的ID加10:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.modify(2, "Female":GENDER, "Violet":NAME) |
|
3 |
>A1. modify (2:3,ID+10:ID) |
A1中序表的初始数据和前面的例子相同, A2和A3修改了序表,分步执行可以查看A1中数据的变化:
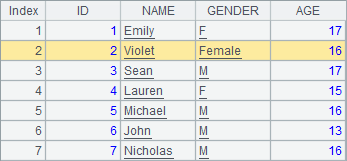
修改序表中的记录需要使用modify函数,modify函数也可以在单条记录中用来修改数据。
在排列中不允许进行记录修改动作,要想修改记录,必须在原序表中进行。
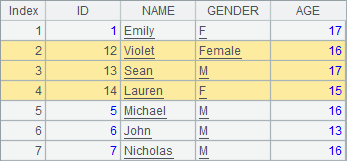
在修改数据时,也可以将1条记录中的字段值按位置修改为另1条记录的字段值:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1(5).modify@r(A1(1)) |
用modify@r函数修改记录,也称为粘贴记录。A2中执行粘贴记录后,序表中第5条记录被修改:
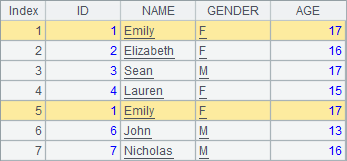
在粘贴记录时,记录可以来自同一序表,也可以来自不同序表。粘贴记录是针对记录的函数,而并非针对序表,因此在排列中也可以同样使用,执行后会修改原始的序表。在集算器中,也可以使用T. modify@r(k:P) 函数,从第k条记录起,同时粘贴排列中的多条记录,k为0时在最后添加记录。如果粘贴记录时,记录来自于数据结构不同的其它序表,可以使用T. modify@f(k:P) 函数,此时只会粘贴P中记录与序表T的共有字段数据。
在序列或记录中,field函数除了可以获得字段值,也可以修改字段值。如:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.field("AGE",20) |
|
3 |
>A1(5).field(2, "Cindy") |
用field函数修改记录,效果和modify类似,只是field指定的可以是字段序号也可以是字段名字符串。执行后,序表中的AGE字段,以及第5条记录的NAME被修改,结果如下:
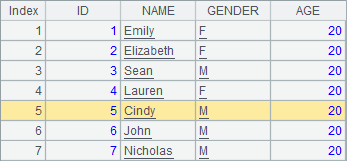
重置序表
用reset函数,可以保留数据结构清空序表:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.reset() |
序表重置后,可以清除不再使用的记录,释放占用的内存:

增加字段
序表中的字段是不允许增加或删除的,如果需要在报表中增加新的字段,如计算列,可以用derive函数生成新序表:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
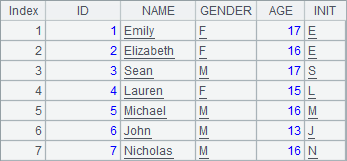
=A1.derive(left(NAME,1):INIT) |
A2中添加字段后,数据如下:
derive函数也可以用于排列,不论被计算的对象是序表还是序列,derive函数都会创建新的序表。如果新的序表中不需要原有的所有字段,也可以用new函数生成序表。如果原序表A1中的数据不再需要,最好将A1的格值清空,或用reset函数重置序表。