
序表是有结构的序列
集算器继承了关系数据库中的数据表概念,称为序表。与关系数据库的概念一致,每个序表也有其自身的数据结构,由若干字段构成。序表的成员被称为记录。
有结构的二维数据对象
序列的成员可以是任意数据类型,比如普通类型、其他序列或者记录。而序表的成员一定是记录,且每条记录的结构相同。比如,下面的数据对象就是序表:
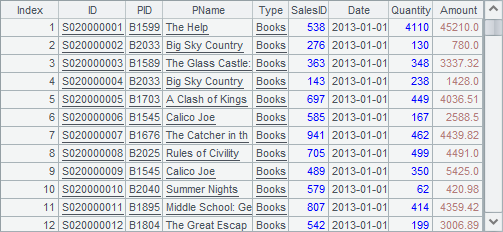
因为是有结构的二维数据对象,所以序表通常生成自SQL、文本文件、集文件、Excel文件,也可以由空白序表创建而来。下面的A1,A2,A3就是序表:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=demo.query("select * from CITIES") |
|
3 |
=create(OrderID,Client,SellerId,Amount,OrderDate) |
A1从文本文件生成序表,获得的结果就是上面的序表。A2通过SQL生成序表,A3指定字段名创建空序表。A2和A3中的数据如下:
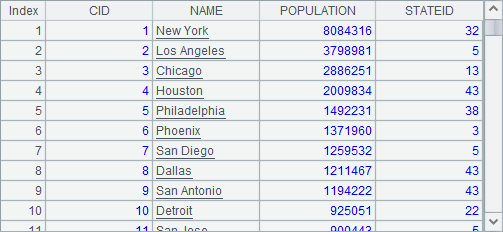
序表支持大量的结构化数据算法,包括查询、排序、求和,平均值,合并重复记录等。比如:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.select(Amount>=20000 && month(Date)==5) |
|
3 |
=A1.sort(SalesID,-Date) |
|
4 |
=A1.groups(SalesID, month(Date); round(sum(Amount),2), count(~)) |
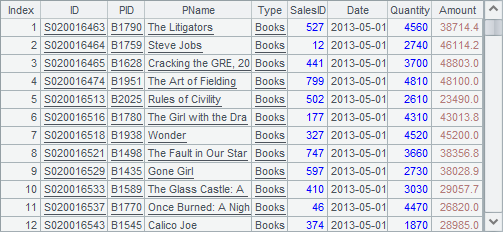
A2中查询出Amount字段大于等于20000,Date是5月的记录:
A3将记录按照SalesID字段升序排列,SalesID一样时将按Date降序排列:
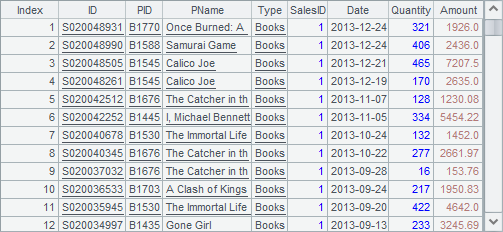
A4按SalesID和月份,对每一组数据的Amount求和,并计算该组订单计数:
序表仍然属于序列,序列的集合性、有序性及其相关的函数都适用于序表。对于泛型性,由于序表的成员必然是同结构的记录,序列意义上的泛型不再支持,不过记录的字段取值可以是泛型数据,可以说是另一种意义的泛型性。因为这些特性,序表比传统程序语言更擅长处理复杂的计算问题。
比如利用有序性解答:每个月的销售额比上个月增长了百分之几。序表的算法如下:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
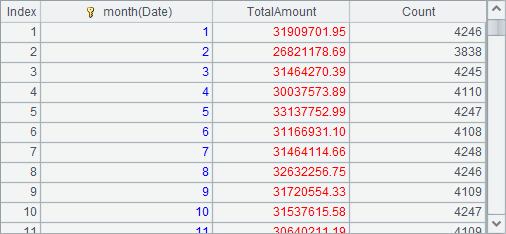
=A1.groups(month(Date); sum(decimal(string(Amount))):TotalAmount, count(~):Count) |
|
3 |
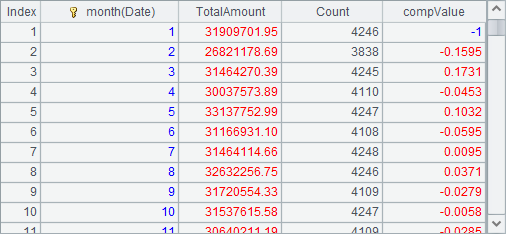
=A2.derive(round(TotalAmount/TotalAmount[-1]-1,4): compValue) |
A2中先统计出每月的总销售额:
A3中计算出最终结果如下:
利用集合性:假设业务上将订购数量大于1000的订单称为大订单,单价大于10000的订单称为重要合同,请找出:①既是大订单又是重要订单的订单;②以及除此之外的其他订单:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
Big |
=A1.select(Quantity>1000) |
|
3 |
Importance |
=A1.select(Amount>10000) |
|
4 |
=B2^B3 |
=A1\A4 |
先在B2中选出大合同,再在B3中选出重要合同。A4中计算出2种合同的交集,就是问题①的答案:
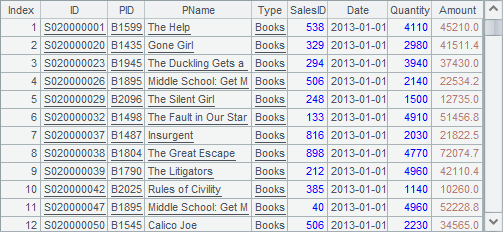
B4中,用全部的订单与问题①的结果做差集,即可得到问题②的答案:
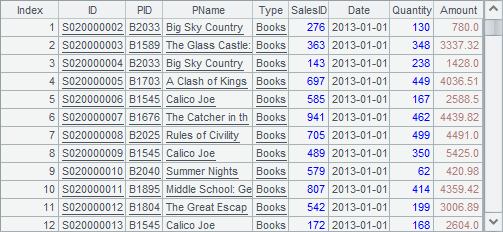
注意,上述代码中的A1中是序表,而B2,B3,A4和B4中,都是由序表派生出的排列,两者的区别和联系将在下面讲。