外键与表间关联
在关系数据库中,常常用外键来处理表间关联,在集算器中,也可以用外键字段表现这种对应关系。
外键字段
集算器中可以用A.derive()函数为排列添加列,如:
|
|
A |
|
1 |
=demo.query("select EID, NAME, SURNAME, BIRTHDAY from EMPLOYEE") |
|
2 |
=A1.derive(NAME+" "+SURNAME: FULLNAME, age(BIRTHDAY):AGE) |
A1中获取员工信息;A2在A1的序表中添加计算列FULLNAME和AGE后返回,分别算出员工的全名和年龄。
A1中的序表如下:
添加计算列后,A2中的序表如下:

了解了如何添加序表的计算列,就可以来看计算列与表间关联的关系了。
在数据库中,在表与表之间经常会存在关联关系,而在集算器中,可以直接用记录引用作为序表中的数据,这样就能体现表间的关联,使得数据的检索和展现简单而结构明晰。
如果我们通过A.derive()来添加列,使这一列的数据类型为另一个表的记录引用或是排列引用,就能构成外键字段,从而实现表间关联,如:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=demo.query("select STATEID, NAME, ABBR, CAPITAL from STATES") |
|
3 |
=A1.derive(A2.select@1(STATEID==A1.STATEID):State) |
|
4 |
=A3.derive(State.ABBR:SA) |
|
5 |
=A2.derive(A1.select(STATEID==A2.STATEID):Cities) |
A1和A2分别取出数据库表STATES和CITIES的数据:
CITIES通过STATEID字段和STATES关联。数据库中的这种存储模式可以使得数据保持一致,易于维护,同时也节省了存储空间。
A3在CITIES中添加State字段作为外键,存储城市所在州的记录。A4中再为城市数据添加SA字段,列出所在州缩写,以方便后面的查看。A5则在州数据中添加Cities字段作为外键,存储每个州中的各个城市记录。
执行后,A4中的数据如下:
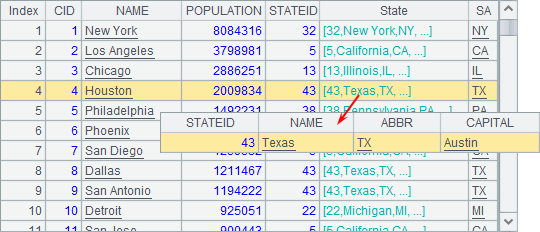
其中的State字段为州信息的记录,可以双击查看。
A5中的数据如下:
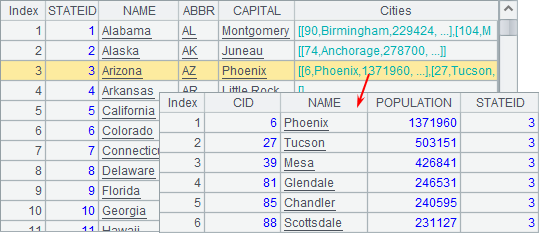
其中的Cities字段为该州的城市记录,也可以双击查看。
可以发现,通过添加外键字段的方式,无论是A4还是A5中的数据,实际上都已经包含了源数据库中STATES和CITIES这两个表的信息,实现了表间关联。需要注意的是,同样是外键字段,它们的类型是不同的:在A4中,外键State的数据是记录;而A5中,外键Cities的数据是排列,即记录的序列。
实际上,STATES表中的STATEID这样的字段,经常是表的主键,在将另一个表如CITIES,通过主键与STATES关联时,也可以使用switch函数。相关的使用方法,请看主键与索引功能。
外键字段的使用
在查询或者展现序表时,外键字段的使用和普通字段是相同的,但是在使用中需要注意外键字段的数据类型。
如下面的例子,在城市信息中,选出州名中包含“la”的,这时可以在过滤表达式中,直接调用外键State的NAME字段过滤数据:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=demo.query("select STATEID, NAME, ABBR, CAPITAL from STATES") |
|
3 |
=A1.derive(A2.select@1(STATEID==A1.STATEID):State) |
|
4 |
=A3.derive(State.ABBR:SA) |
|
5 |
=A2.derive(A1.select(STATEID==A2.STATEID):Cities) |
|
6 |
=A4.select(like(State.NAME,"*la*")) |
注意此时用到的外键字段类型是记录,A6中的计算结果如下:
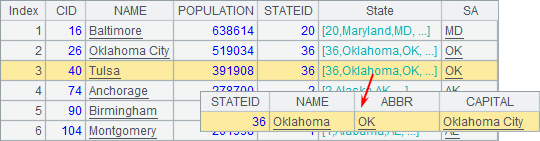
也可以将外键字段作为排序依据,如根据本州中城市记录的数量,对州数据降序排序:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=demo.query("select STATEID, NAME, ABBR, CAPITAL from STATES") |
|
3 |
=A1.derive(A2.select@1(STATEID==A1.STATEID):State) |
|
4 |
=A3.derive(State.ABBR:SA) |
|
5 |
=A2.derive(A1.select(STATEID==A2.STATEID):Cities) |
|
6 |
=A5.sort(-Cities.len()) |
注意,这里使用到的外键字段类型是排列,A6中的排序结果如下:
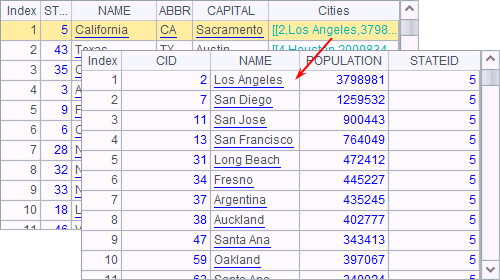
如果序表的某个外键字段所引用的记录中,仍然包含外键字段,是可以继续引用的。如,列出所在州恰好有3个城市记录的城市信息:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=demo.query("select STATEID, NAME, ABBR, CAPITAL from STATES") |
|
3 |
=A2.derive(A1.select(STATEID==A2.STATEID):Cities) |
|
4 |
=A1.derive(A3.select@1(STATEID==A1.STATEID):State) |
|
5 |
=A4.select(State.Cities.len()==3) |
在这里,A4在城市信息中添加州信息时,用的并非是原始的州信息,而是A3中包含着外键字段的州信息。这样,在A5中就可以查询到所需要的结果:
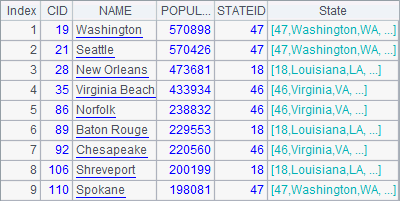
连接
另一种表间关联是SQL的连接运算,集算器中的join函数可以实现类似的功能。但在有了记录和排列引用机制和align等函数后,这种运算变得不大常用了。
等值连接
外键字段可以通过相等的关系将一个表中的字段与另一个表中的记录引用相匹配,而用join函数实现的连接,是通过相等的关系将两个或多个表的记录引用相匹配。如:
|
|
A |
|
1 |
=demo.query("select STATEID,NAME,POPULATION,ABBR from STATES") |
|
2 |
=demo.query("select * from CITIES") |
|
3 |
=A1.select(NAME>"C") |
|
4 |
=A2.groups(STATEID:ID;count(~):Count) |
|
5 |
=join(A3:StateInfo,STATEID;A4:CityCount,ID) |
|
6 |
=join@1(A3:StateInfo,STATEID;A4:CityCount,ID) |
|
7 |
=join@f(A3:StateInfo,STATEID;A4:CityCount,ID) |
A3中选出了字母C及以后的州:
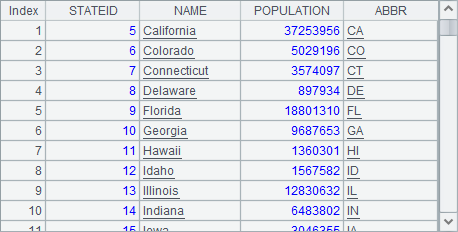
A4中则根据大城市表CITIES中的数据,统计出了各州的大城市总数:

需要注意的是,A3中并没有名称首字母为"A"和"B"的州,STATEID从6开始才有数据。而并非所有州都有大城市记录,如A4中并没有ID为4,7,8,…等各州的统计值。
A5中,根据各自的州序号将A3和A4中的记录连接,结果如下:
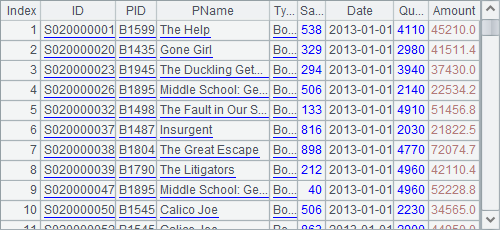
从结果中可以看到,默认情况下,join函数连接的结果中仅包括两个表中州序号能够匹配的记录。结果可以看为一个由外键构成的序表,每个字段都是记录引用。
join函数大体相当于在SQL中写:select Ai.* as Fi,… from Ai,… where Ai.xj =… and …
这也是SQL中最常见的连接写法。
连接时,还可以使用其它模式,如A6中,join@1表示左连接,需要注意的是选项是数字@1,而不是小写字母@l,为了避免混淆,集算器中不使用小写字母L作为选项。A6中结果如下:
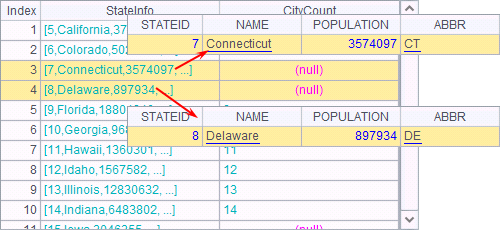
此时,A3中各州数据都返回到了结果中,其中有一些州无法在A4中找到对应的统计值,如州序号为7,8,…的各州。
在A7中的join@f表示全连接,A7中结果如下:

此时,A3和A4中各州数据都返回到了结果中,其中有一些州无法在A3中找到对应的统计值,如州序号为1,2,3,…的各州;也有一些无法在A4中找到对应的统计值,如州序号为7,8,…的各州。
同位连接
使用join函数连接不同序表中的记录引用时,是通过相等的关系。除此以外,还可以将不同的序表按照位置连接,这时需要添加选项@p,如:
|
|
A |
|
1 |
=demo.query("select STATEID,NAME,POPULATION,ABBR from STATES order by STATEID") |
|
2 |
=demo.query("select * from CITIES") |
|
3 |
=A2.groups(STATEID:ID;count(~):Count) |
|
4 |
=join@p(A1:StateInfo;A3:CityCount) |
A3中根据大城市表CITIES中的数据,统计出了各州的大城市总数,注意其中缺少一些州的统计结果:
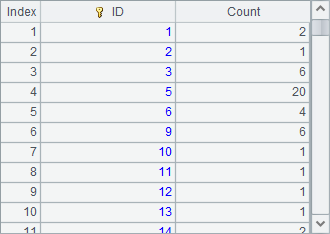
A4中将A1中所有州的信息,与A3中统计的结果同位连接,结果如下:

连接后,结果的记录条数将以连接时使用的最短序表为准。在同位连接时,仅仅将两个序表中的记录按照位置依次连接。如果用来连接的序表记录并不能对齐,这样获得的结果就无法保证数据相关。如上面的结果中,序号为4的Arkansas州的数据,和序号为5的城市统计数据连接在了一起。
实际上,join@p是用于将几个数据长度和顺序都相同的表横向拼接在一起时使用的,如:
|
|
A |
|
1 |
=demo.query("select * from STATENAME") |
|
2 |
=demo.query("select * from STATECAPITAL") |
|
3 |
=demo.query("select * from STATEINFO") |
|
4 |
=join@p(A1:Name;A2:Capital;A3:Info) |
A1,A2和A3中的数据,都是全部州信息的一部分,且排列顺序相同:
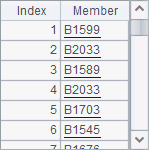


此时,A4中用join@p就可以将这些信息连接在一起:

此时连接的结果就是正确的了。对于上例中的情况,应该用align函数将两表中的记录对位连接。
如果使用企业版集算器,可以将A4中的表达式写为=j(A1:Name;A2:Capital;A3:Info),得到纯序表的结果用于进一步计算,有关企业版集算器中的纯序表,可以参考企业版集算器函数简介。
交叉连接
交叉连接是将多个序列中的成员一一配对。交叉连接是最基本的连接,生成结果时没有任何过滤条件,只是列出所有可能的组合,计算时使用xjoin函数。如:
|
|
A |
|
1 |
[1,2,3,4] |
|
2 |
[a,b,c] |
|
3 |
=xjoin(A1:Number;A2:Letter) |
A3中的结果如下:
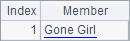
可以看到,结果序表中的记录是数字和字母配对的所有组合。
在使用xjoin函数时,同样也可以交叉连接序表或排列中的记录,此时,还可以设定记录的过滤条件,如:
|
|
A |
|
1 |
=demo.query("select * from STATES") |
|
2 |
[M,F] |
|
3 |
=demo.query("select * from EMPLOYEE") |
|
4 |
=xjoin(A1:State;A2:Gender;A3:Employee,STATE==State.NAME&& GENDER==Gender) |
A1中取出各州的信息,A2中设定性别序列,A3中取到员工资料。在A4中交叉连接时,连接A3中的员工资料时,设定了过滤条件,只取出指定州和性别的记录来连接。A4中的结果如下:

递归查询
在序表中,通过外键式关联,可以引用其它序表的记录,从而实现多个序表间的指针化关联。除此以外,在一个表内,也可以通过外键式关联来引用自身记录,实现自连接。通过自连接实现的数据结构,往往是多层次的树状体系,在这样的结构中查询数据,就需要使用递归查询。
自连接
序表中自连接的使用和多序表连接时没有什么区别。如:
|
|
A |
|
1 |
=file("Geography.txt").import@t() |
|
2 |
>A1.switch(Parent,A1:ID) |
其中,Geography.txt的数据如下,在其中记录了各个层次的地区数据,包括地区,州等,同时通过Parent字段指明当前地区所处的上层地区的编号:
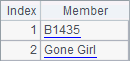
执行自连接后,数据如下:

可以看到通过自连接后产生的多层引用关系。
递归查询记录的各层外键
在自连接后产生的多层外键引用结构中,通过使用r.prior(F,r',n)函数,可以在记录r的外键F中查询外键引用的各层数据。如果指明了r',则会查询到r'出现在外键字段F中为止。在递归查询时,可以根据需要指定递归的最大层次n。如:
|
|
A |
|
1 |
=file("Geography.txt").import@t() |
|
2 |
>A1.switch(Parent,A1:ID) |
|
3 |
=A1.select@1(Entry=="Alabama") |
|
4 |
=A1.select@1(Entry=="South") |
|
5 |
=A1.select@1(Entry=="West") |
|
6 |
=A3.prior(Parent) |
|
7 |
=A3.prior(Parent,A4) |
|
8 |
=A3.prior(Parent,A5) |
在A6中,查询出Alabama州所引用的各层外键,结果如下:
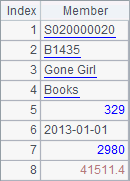
A7中的结果则查询到South出现在Parent中为止,结果如下:
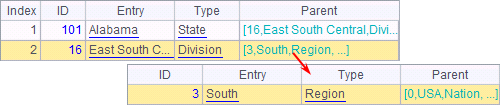
由于Alabama并不在West区域中,因此A8中返回null。
递归查询下层数据
使用prior()函数可以查询记录各层外键所引用的数据,相对应的,也可以使用P.nodes(F,r,n)函数,在排列P中,递归查找所有在外键F中引用到记录的数据。这种查询其实就是在多层外键引用结构中,查找r的下层记录。如:
|
|
A |
|
1 |
=file("Geography.txt").import@t() |
|
2 |
>A1.switch(Parent,A1:ID) |
|
3 |
=A1.select@1(Entry=="South") |
|
4 |
=A1.nodes(Parent,A3) |
|
5 |
=A1.nodes@d(Parent,A3) |
|
6 |
=A1.nodes@p(Parent,A3) |
在A4中,查询出所有在South的记录,包括Division和State各层,结果如下:
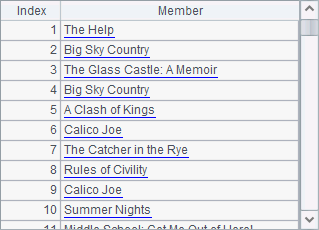
在A5中,nodes()函数中添加了@d选项,此时返回的数据均不再有下层记录,在这里只会返回州数据,结果如下:
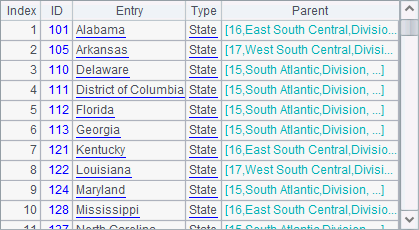
在A6中, nodes()函数中添加了@p选项,此时在返回记录时,将同时返回记录到r的引用层次,结果如下: