
特殊标识符
在集算器中使用字符串时,有时会遇到一些特殊标识符,有可能使表达式引发歧义。序表中的字段名同样也会有可能含有特殊标识符,在这里,我们了解一下如何处理这样的问题。
字符串中的特殊标识符
字符串中,有时会包含各种符号,其中某些符号有可能使得字符串在使用时遇到麻烦。首先来看使用常数字符串时可能遇到的问题,如:
|
|
A |
B |
C |
|
1 |
=,>,<,+,- |
===== dividing line ===== |
>100 |
|
2 |
/ is division sign |
34.55 |
end |
A1和B1中的是以"="开头的字符串,如果直接写在单元格中,只会认为它们是错误的表达式而不是常数格,在运算时会出现错误。C1中是">"开头的字符串,在运算时同样不会被按字符串处理,而是作为执行格。A2中是以"/"开头的字符串,直接写在单元格中会被处理为注释语句。B2中的常数会自动解析为实数而不是字符串。C2中的字符串由于是保留字,因此同样不会作为字符串常数来处理。这些单元格中只有B2中有格值,但却并不是字符串类型:
![]()
上面的问题中,字符串常数不能正常使用,主要是因为字符串本身存在歧义,也有可能是第一个字符使用了"=>/"等特殊标识符。在集算器中,这样的字符串常数,只需在前面添加一个单引号’就可以表明格中数据是字符串常数:
|
|
A |
B |
C |
|
1 |
'=,>,<,+,- |
'===== dividing line ===== |
'>100 |
|
2 |
'/ is division sign |
'34.55 |
'end |
A1,B1,C1中的值如下,最开始的'符号只作为字符串常数格的标记,而不会出现在值里:
![]()
![]()
![]()
A2,B2,C2中的值如下,注意其中B2中的数据靠左对齐显示,是字符串:
![]()
![]()
![]()
在表达式中使用字符串时,需要用双引号"…"标明,上面例子中会出现问题的字符串在表达式中并没有歧义。但是,如果字符串中本来就包含",应该如何处理呢?此时需要在字符串中的双引号前添加转义符\,字符串中包含的\字符前同样要添加一个转义符\。如:
|
|
A |
B |
C |
|
1 |
="===== dividing line =====" |
="/ is division sign" |
="34.55" |
|
2 |
="\"How is Frank?\" he asked." |
=$[$\{B1}"C:\\test"] |
=$[${B1}"C:\\test"] |
其中,A1,B1和C1中就是使用上面问题中的比较特殊的字符串,在表达式中用双引号就是表示字符串类型,使用并无歧义,格值如下:
![]()
![]()
![]()
A2的字符串中需要用到双引号,每个双引号之前都应该添加转义符。如果字符串中使用\字符,则同样需要添加转义符。A2中格值如下:
![]()
B2中使用字符串常数$[…]来表示字符串,而不是用双引号,此时字符串中的双引号不会有歧义,不必添加转义符,而\符号前面仍然需要添加。另需注意的是,字符串常数中存在新的问题:由于字符串常数中允许使用${…}格式表示的宏,因此如果不需要使用宏时,需要在其中添加一个转义符,表示不是宏而是字符串本身的内容,作为比较,我们可以查看B2和C2中的格值:
![]()
![]()
可以看到,计算C2中的表达式时,${B1}被作为宏使用,将B1的值引入了字符串。
字段名中的特殊标识符
在使用序表时,如果序表的字段名中包含非字母数字的特殊标识符,如%, (,),"等符号或者空格等,都有可能致使表达式解析时产生歧义,如:
|
|
A |
|
1 |
$(demo) select * from STATES order by STATEID |
|
2 |
=A1.new(NAME:STATE,POPULATION,AREA:'AREA(sq. mi.)') |
|
3 |
=A2.(round(POPULATION/AREA(sq. mi.),3)) |
A2中生成的序表如下,其中在州面积字段中添加了单位以作说明:

当A3中试图使用A2中的数据来计算每个州的人口密度时,字段名在表达式中的解析出现了问题。为了避免这种情况,可以用单引号'…'将序表的字段括起来,从而把其中的标识符和特定符号区分开,如:
|
|
A |
|
1 |
$(demo) select * from STATES order by STATEID |
|
2 |
=A1.new(NAME:STATE,POPULATION,AREA:'AREA(sq. mi.)') |
|
3 |
=A2.(round(POPULATION/'AREA(sq. mi.)',3)) |
此时,集算器计算时就可以知道'AREA(sq. mi.)'单引号中的字符需要整体处理。A3中就可以计算出所需结果:
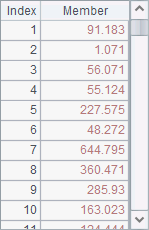
用'…'表示的特殊标识符,除了序表中的字段名,也有可能在调用特殊名称的参数时使用。
当然,序表中的字段也可以按照位置引用,而避免字段名造成的麻烦,如:
|
|
A |
|
1 |
$(demo) select * from STATES order by STATEID |
|
2 |
=A1.new(NAME:STATE,POPULATION,AREA:'AREA(sq. mi.)') |
|
3 |
=A2.derive(round(POPULATION/#3,3):Density) |
在A3中,在A2中序表的基础上,添加了人口密度列,计算时,用#3表示引用A2的第三个字段,避免了特殊字段名带来的问题。A3中结果如下:
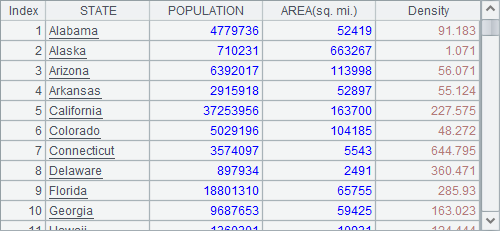
在用'…'表示的特殊标识符调用序表字段时,序表的字段名中是不能存在单引号的,否则就只能使用上例的方法按位置访问字段了。