
使用序表与排列
集算器序表是有结构的二维表,具有字段、记录、主键、索引的概念,这些概念继承自关系数据库中的数据表。序表还是泛型和有序的显式集合,可以更加灵活地进行结构化数据的计算。排列是序表的引用,两者紧密相关且用法基本相同。下面从访问、循环函数、聚合函数、集合运算等几个方面讲解序表和排列的基本运算。
访问
创建
下面的网格中,从文件读取二维结构化数据,创建序表对象并存入A1单元格。通过查询A1创建排列对象并存入B1:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
计算后,A1中序表如下,窗口中只显示了部分数据,可以拖拽右侧的滚动条显示全部记录:
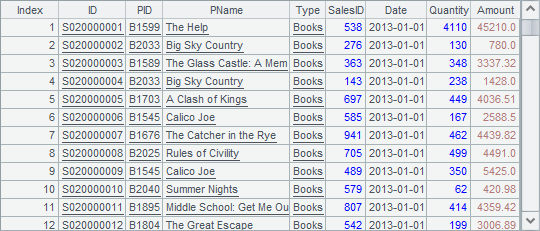
B1中排列如下:
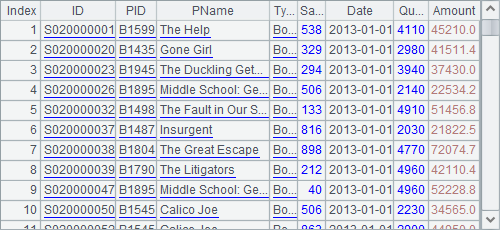
说明: 序表对象可以创建自数据库、文件,也可以通过向空白对象插入记录来创建。排列创建自序表,本身并不存储实体记录,只存储序表中部分记录的引用。
访问字段值
下面的网格中,读取序表对象A1的第20条记录的PName字段,存入A2单元格。读取排列对象B1的第2条记录的PName字段,存入B2单元格:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1(20).PName |
=B1(2).PName |
A2和B2中的结果如下:
![]()
![]()
可以看到,由于B1的第2条记录指向A1的第20条记录,因此两者的计算结果相同。从A2和B2的表达式中还可以发现,序表和排列访问字段的语法完全相同。
字段名可以用字段序号来代替,结果一样,比如写成:=A1(20).#3。这种代替在集算器中是通用的,之后的例子不再赘述。
用field函数和array函数也可以获取序表或者记录中字段的值,如:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.field(2) |
|
2 |
=A1(20).field(2) |
=A1(20).array(PName) |
|
3 |
=A1(20).array(PID,PName) |
=A1(20).array() |
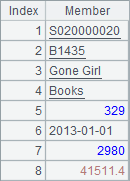
使用field函数时,可以指定获得某个序号的字段值,B1和A2中的结果如下:
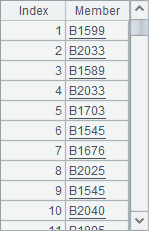
![]()
使用array函数时,可以获得记录中,指定字段名的一个或一些列的值,如果不指定,则会返回记录中所有字段值构成的序列。B2,A3和B3中结果如下:
![]()
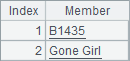
访问列数据
下面的网格中,从序表A1中按列名取PName列,存入A2。仍然从序表A1中按列名取PName和Amount这两列,存入B2。排列和序表访问列数据时的写法完全一样,这里只用序表来举例:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1.(PName) |
=A1.new(PName,Amount) |
A2和B2中的计算结果分别如下:
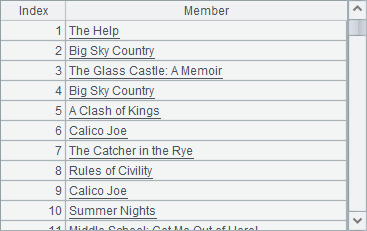
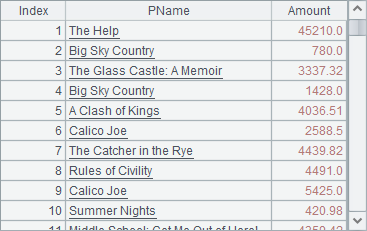
T.(x),这种语法只能取一列数据,此时的计算结果为序列,没有结构化的列名。T.new() 函数可以取一列或多列数据,此时的计算结果为序表,有结构化的列名。
不论被计算的对象是序表还是序列,T.new() 或者A.new() 函数都会创建新的序表,即B1.new(PName, Amount) 的计算结果也是序表。
访问行数据
下面,从序表A1中按行号取前2条记录存入A2,从序列B1中按行号取出前2条记录存入B2,排列和序表访问行数据的写法也是完全一样的:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1([1,2]) |
=B1([1,2]) |
A2中结果如下:

B2中结果如下:

循环函数
循环函数可以针对序表/排列的每一条记录进行计算,可以将结构复杂的循环语句用简单的函数来表达。比如select用于查询,sort用于排序,id用于合并重复记录,pselect取符合条件的记录序号。这里介绍最基本的select和sort函数。如果需要了解更多有关循环函数的内容,请参考:循环计算。
查询
下面的网格中:查询出Amount字段大于等于20000,Date是3月的记录,排列和序表在查询数据时的写法完全一样,这里仅以序表为例:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>=20000 && month(Date)==3) |
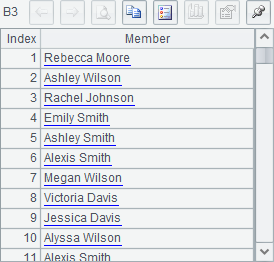
B1中计算结果如下:
不论被计算的对象是序表还是排列,select函数的计算结果都是排列,即记录的引用而不是实体记录。
排序
下面的网格中,将记录按SalesID字段升序排列,SalesID一样时将按Date降序排列。排列和序表在排序时的写法完全一样,这里仅以B1中的排列为例:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=B1.sort(SalesID,-Date) |
|
计算结果:
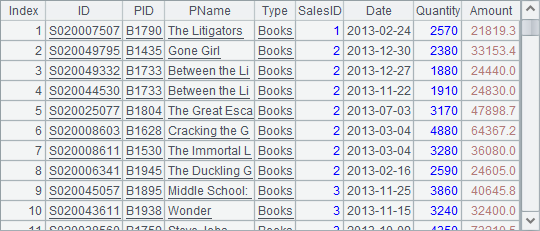
不论被计算的对象是序表还是排列,sort函数的计算结果都是排列。事实上,只要不涉及到记录的改变,序表和排列的绝大部分函数都是通用的。
聚合函数
求最大值
求Amount字段的最大值,排列和序表在这里的写法完全一样,仅以序表A1为例:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1.max(Amount) |
|
A2中计算结果如下:
![]()
类似的函数还有最小值min,求和sum,平均值avg,计数count等。
分组求和
下面的网格中,按SalesID和月份,对每一组数据的Amount求和,并对该组订单计数,排列和序表在这里的写法完全一样,仅以序表A1为例:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1.groups(SalesID, month(Date); round(sum(Amount),2), count(~)) |
|
A2中计算结果如下:
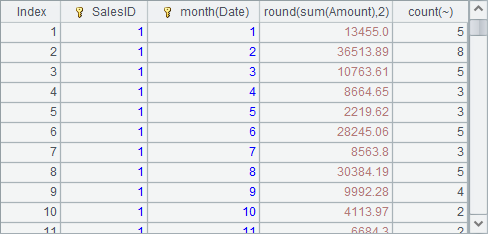
需要注意,groups函数会产生新的序表。表达式count(~)中的"~"表示当前组,写成count(ID)也可以。另外,代码中我们没有指定计算结果的字段名,所以会出现month(Date)这样的默认字段名,指定字段名可以用冒号,如:=A1.groups(SalesID, month(Date):Month; sum(Amount), count(ID))。
集合间运算
集合间运算包括交集"^",并集"&",差集"\",合集"|"等。
交集与差集运算
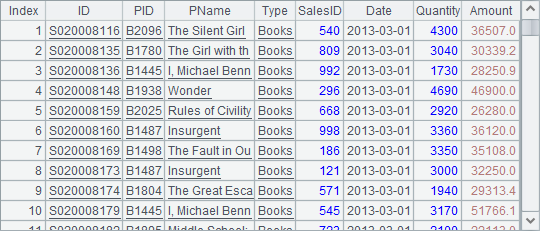
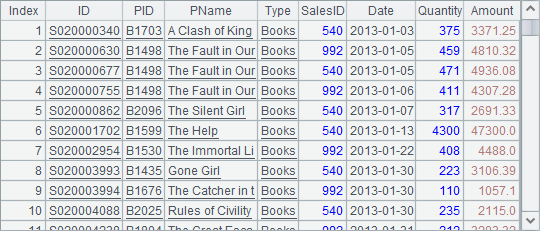
下面的网格中,将Amount大于等于20000且月份是3月的订单存入A2,将SalesID等于540或992的订单存入B2。求A2和B2的交集和差集,结果存入A3和B3:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
=A1.select(Amount>=20000 && month(Date)==3) |
=A1.select(SalesID==540 || SalesID==992) |
|
3 |
=A2^B2 |
=A2\B2 |
A2中排列如下:
B2中排列如下:
A3中计算交集,结果是排列:

B3中计算差集,从A2中去掉B2的成员,结果仍然是排列:
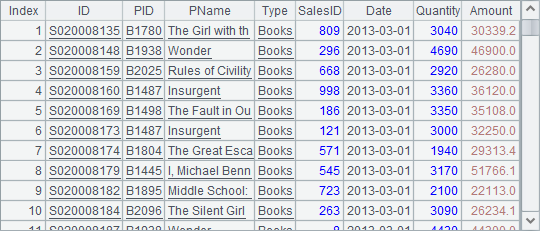
再来看看不同序表中的集合运算,先使用derive() 函数将序列或排列复制生成新序表,再计算交集和差集:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
=A1.select(Amount>=20000 && month(Date)==3) |
=A1.select(SalesID==540 || SalesID==992) |
|
3 |
=A2.derive() |
=B2.derive() |
|
4 |
=A3^B3 |
=A3\B3 |
A3和B3中的序表中的数据,和前面例子中A2和B2是相同的。
A4中计算A3和B3的交集,结果为空集:

这说明序表作为实体成员的集合,不同序表的成员总是不同的,两个序表之间交运算一定是空,没有实际的业务意义。
B4中计算A3和B3的差集,因为两个序表的成员总是不同的,因此差集的计算结果仍为A3:
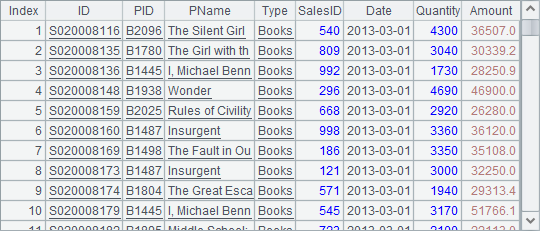
由于来自于同一个序表的排列进行集合运算时才会有实际的业务意义。不同的序表或来自不同序表的排列做交、差时通常没有实际的业务意义。
并集与合集运算
下面的网格中,从B1的排列中选择记录构成排列,将SalesID等于540和992的订单存入A2,将SalesID等于540和668的订单存入B2。求A2和A3的并集和合集,结果存入A3和B3:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>=20000 && month(Date)==3) |
|
2 |
=B1.select(SalesID==540 || SalesID==992) |
=B1.select(SalesID==540 || SalesID==668) |
|
3 |
=A2&B2 |
=A2|B2 |
A2中排列如下:

B2中排列如下:

A3中计算A2和B2的并集。A2和B2的成员会按顺序合并,重复的记录会去除。

A5中计算A2和A3的合集。A2和A3的成员会按顺序合并,重复的记录不会去除。
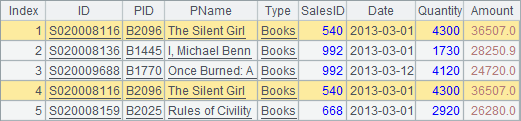
再来看看不同序表中的集合运算:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>=20000 && month(Date)==3) |
|
2 |
=B1.select(SalesID==540 || SalesID==992) |
=B1.select(SalesID==540 || SalesID==668) |
|
3 |
=A2.derive() |
=B2.derive() |
|
4 |
=A3&B3 |
=A3|B3 |
A3和B3中的序表中的数据,和前面例子中A2和B2是相同的。
A4中计算A3和B3的并集。两个序表的成员完全不同,做并运算即相当于两个表的简单合并(union all),这和做合集运算的结果相同:
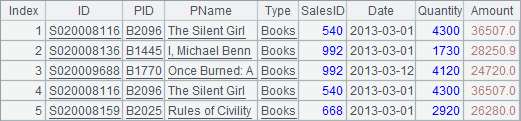
B4中计算A3和B3的合集,结果与A4中计算并集时完全相同: