
企业版集算器函数简介
在上一小节中,例子中接触了一些只有企业版集算器中才可使用的函数,本节中简单介绍一下这些函数。
|
|
A |
B |
|
1 |
[Moore,Wilson,Johnson,Smith] |
=ifpure(A1) |
|
2 |
=A1.i() |
=ifpure(A2) |
|
3 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=ifpure(A3) |
|
4 |
=A3.i() |
=ifpure(A4) |
|
5 |
=A4.o() |
=ifpure(A5) |
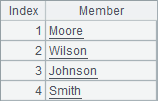
在企业版集算器中,可以使用纯序列,与普通序列不同,纯序列中所有成员的类型都是强制相同的。可以使用A.i() 函数将普通序列A转化为纯序列,用ifpure(A)判断一个序列A是否纯序列。如A1、B1、A2和B2中的执行结果如下:
![]()
![]()
可以看到,普通序列和纯序列,在显示时没有什么区别,只能通过ifpure函数才能判断。
与纯序列类似,如果一个序表中,某个字段的所有数据类型全相同,这样的字段称为纯字段。如果序表中强制所有字段都是纯字段,这样的序表称为纯序表,纯序表是使用列式存储的,使用时需要注意。可以使用T.i() 函数将普通序表T转化为纯序表,用ifpure(T)判断一个序表T是否纯序表。与纯序列类型,纯序表和普通序表显示外观相同,只能通过ifpure函数判断,如上面例子中A3、B3、A4和B4中结果如下:
![]()
![]()
另外,可以用A.o()或者T.o()函数,将一个纯序列A或者纯序表T,转化为普通序列或者普通序表,如A5和B5中结果如下:
![]()
下面,看一下纯序列与普通序列有什么区别:
|
|
A |
B |
|
1 |
[Moore,Wilson,Johnson,Smith] |
=A1.i() |
|
2 |
>A1.insert(0,12) |
>B1.insert(0,12) |
A2执行后,A1中数据会正常改变:

在纯序列中,所有成员是强制同类型的,如果试图在纯序列中插入其它类型的数据,或者改变某个成员为其它类型,都是不允许的。因此B2中命令无法执行,会提示错误:
在纯序表中的情况也类似:
|
|
A |
B |
|
1 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=A1.i() |
|
2 |
>A1(1).BIRTHDAY=20001231 |
>B1(1).BIRTHDAY=20001231 |
A2改变第一条记录的字段值后,A1中序表数据如下:
和纯序列不太一样,由于各个字段均为纯序列,因此在纯序表中不能用insert/delete等添加或者删除整条记录的命令。但是,如果纯序表中的字段值被改变时,会要求类型不能变化,如试图执行B2时,会提示错误:
在纯序表或者纯序列中,由于数据的类型统一,因此在执行定位操作时,效率会有明显提升,如:
|
|
A |
B |
C |
|
1 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=A1.i() |
=A1.(NAME) |
|
2 |
=100000.(C1(rand(500)+1)) |
=now() |
|
|
3 |
=A2.(A1.pselect@1(NAME:A2.~)) |
=now() |
=interval@ms(B2, B3) |
|
4 |
=A2.(B1.pselect@1(NAME:A2.~)) |
=now() |
=interval@ms(B3, B4) |
A1中为普通序表,B1中为纯序表,在A2中生成100,000个随机NAME,在A3和A4中,分别在普通序表和纯序表的EID字段中,查找每个序号的位置。两个序表中得到的结果是相同的:

在C3和C4中,比较两种定位方式的用时,能够看到A4中在纯序表中查找数据时,用时明显更少:
![]()
![]()
需要注意的是,由于纯序表中数据是按列存储的,因此虽然定位效率较高,但是纯序表中的记录在获取数据时需要从每列中按位置获取,就会影响性能了:
|
|
A |
B |
C |
|
1 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=A1.i() |
=A1.(NAME) |
|
2 |
=100000.(C1(rand(500)+1)) |
=now() |
|
|
3 |
=A2.(A1.select@1(NAME:A2.~)) |
=now() |
=interval@ms(B2, B3) |
|
4 |
=A2.(B1.select@1(NAME:A2.~)) |
=now() |
=interval@ms(B3, B4) |
和前面例子相比,只是把A3和A4中的定位函数T.pselect()换为了选出函数T.select(),此时A3和A4返回的是记录构成的排列,结果仍然是相同的,只是A4结果中的记录均为纯序表中的记录,纯序表中记录构成的排列称为纯排列,展示时需要从各列中取数:

在C3和C4中,比较两种选出方式的用时,结果如下:
![]()
![]()
此时使用纯序表就没有优势了,因此何时使用纯序列和纯序表,需要根据实际的需求来决定。
数据库中查询得到的表,各个字段通常都能够满足类型相同的条件,在db.query(sql) 函数中,添加@v选项,可以直接返回纯序表作为结果:
|
|
A |
B |
|
1 |
=demo.query@v("select EID, NAME, BIRTHDAY from employee") |
=ifpure(A1) |
|
2 |
=A1.select(left(NAME,1)=="J") |
=ifpure(A2) |
|
3 |
=A1.select@v(left(NAME,1)=="J") |
=ifpure(A3) |
|
4 |
[Rebacca, Matthew, Smith] |
|
|
5 |
=A4.(A1.select@v(NAME==A4.~)).conj() |
=ifpure(A5) |
|
6 |
=A4.(A1.select@v(NAME==A4.~)).conj@v() |
=ifpure(A6) |
|
7 |
=A6.sort@v(BIRTHDAY) |
=ifpure(A7) |
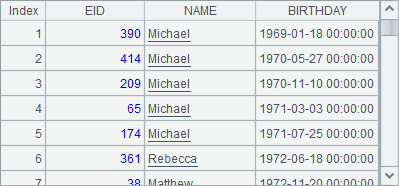
A1和B1中结果如下:
![]()
用函数T.select(sql) 时,如果是纯序表时,返回的结果为纯排列,它其实是由纯序表中记录构成的普通序列。如果添加@v选项,返回的结果将转换为纯序表。与之类似,在纯序列A中也可以用A.select@v(…) 时获得纯序列的结果。A2,B2,A3和B3中结果如下:
![]()
![]()
当计算多个纯序列的和列时,默认情况下只会得到普通序列,也可以在函数A.conj(…)中添加选项@v,得到纯序表。如上例中A5,B5,A6和B6中结果如下:
![]()
![]()
类似的还可以用函数T.sort@v(…),P.sort@v(…),将纯序表T或纯排列P中记录排序后生成纯序表作为结果。如A7和B7中结果如下:
![]()
在使用纯序表,用T.new(…)函数或T.derive(…)函数来产生新序表时,仍然会获得纯序表,此时如果添加@o选项可以利用表中已存在的列来提高效率,例如:
|
|
A |
B |
C |
|
1 |
=demo.query@v("select NAME, SURNAME, STATE, DEPT from employee") |
|
|
|
2 |
=1000.(A1).conj@v() |
=now() |
=ifpure(A2) |
|
3 |
=A2.new(#:ID, NAME/" "/SURNAME:FullName, STATE, DEPT) |
=now() |
=ifpure(A3) |
|
4 |
=A2.new@o(#:ID, NAME/" "/SURNAME:FullName, STATE, DEPT) |
=now() |
=ifpure(A4) |
|
5 |
=interval@ms(B2,B3) |
=interval@ms(B3,B4) |
|
|
6 |
>A2(1).NAME = "New Name" |
>A2(1).STATE = "New State" |
|
A1中数据比较少,因此在A2中将其复制1000遍,再生成纯序表,数据如下:
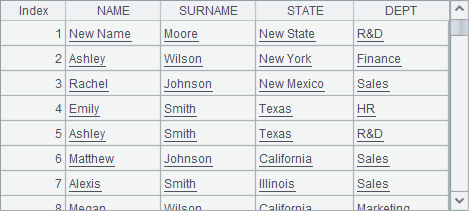
在A3和A4中用T.new(…)函数产生新序表,不同的是A4中添加了@o选项,此时产生新的纯序表时会利用A2中已有的列,为此第6行的代码修改了A2中首条记录的NAME和STATE字段。执行完成后,A3和A4中生成的新序表如下:
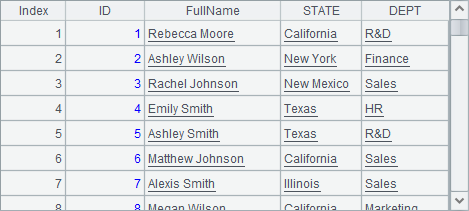

从二者的数据可以看到,虽然是在生成新序表后,修改的原始序表A2中的数据,但A4结果中,第一条记录的STATE字段也被修改了,这是因为此列和A2中是共用的。但是,由于FullName字段是新生成的数据,因此A2中NAME的变化不会影响A4。同时,由于A3中未使用@o选项,它的数据完全不受影响。
从C2、C3和C4的结果可知,A2、A3和A4中均为纯序表:
![]()
![]()
![]()
比较A5和B5中的用时,可以得知使用@o选项时,会有更好的效率。
![]()
![]()