
企业版 JDBC
本节内容,涉及功能只有企业版集算器才可使用,其它版本的产品用户可以跳过。
在这一章中介绍了集算器JDBC的部署和使用,除了普通版集算器JDBC(简称为PJDBC)之外,在企业版集算器中,能够使用企业版JDBC。企业版JDBC和前面介绍的集算器JDBC并没有本质区别,区别只是底层使用的集算器包及相关包有所区别,PJDBC使用集算器相关包,而企业版JDBC需要使用企业版集算器的相关jar包,而配置也是相同的,需要部署raqsoftConfig.xml文件,如果需要集成到项目中,则需要配置项目中的web.xml文件。
企业版 JDBC 的下载安装和配置
在下载页面http://www.raqsoft.com.cn/download/download-jsq中,查找企业版安装包,可以下载安装企业版集算器。安装完成后,在[安装目录]\esProc\lib目录中则包含着企业版集算器JDBC所需的各个基础jar包,与普通集算器相比,其中需要包含企业版集算器附加的esproc-ent-xxxx.jar,如果需要使用扩展功能,则需要添加相应的功能性jar包esproc-ext-xxxx.jar。
部署企业版JDBC所需使用的文件,除了可以使用集算器ide配置的[安装目录]\esProc\config\raqsoftConfig.xml,也可以在q-server\webapps\qvs\WEB-INF\home目录中找到,这两个文件的内容是类似的,只不过后者是服务器加载时使用的配置文件,并不会随着集算器软件的调整而改变,如果使用需要自行按需要编辑。
如果需要了解更多有关企业版集算器服务器的信息,请阅读云服务部署说明 等相关文章。
企业版 JDBC 的使用
企业版JDBC的使用方法和PJDBC也是相同的,如用java调用去用call语句执行spl语句,或者调用网格文件等,但是在其中可以使用企业版专有的函数。如用下面的网格文件testQJDBC.splx为例:
|
|
A |
|
1 |
=dql("pseudo/test.glmd") |
|
2 |
=A1.query("select EID, Name, ifMarried from emps") |
|
3 |
=A2.i() |
|
4 |
>output(ifpure(A3)) |
|
5 |
return A3 |
这个网格中包含一些企业版集算器的专有函数,如A1中的dql()函数用来打开一个DQL的定义文件,之后在A2中在dql中执行查询语句。在A3中用P.i()函数将结果转换为各个字段的数据类型全部相同的纯序表,为了了解转换是否成功,在A4中用ifpure()函数判断结果是否纯序表,并输出结果。
使用下面的java代码,调用企业版JDBC执行网格文件,特别的,这里指定了配置文件raqsoftConfig.xml,如果不指定则会使用默认的文件:
public void testDataServer(){
Connection con = null;
java.sql.CallableStatement st;
try{
//建立连接
Class.forName("com.esproc.jdbc.QDriver");
con= DriverManager.getConnection("jdbc:esproc:q:local://?config=D:/soft/raqsoft/esProc/q-server/webapps/qvs/WEB-INF/home/raqsoftConfig.xml");
//调用存储过程,其中createTable1是脚本文件的文件名
st =con.prepareCall("call testQJDBC()");
//执行存储过程
st.execute();
//获取结果集
ResultSet rs = st.getResultSet();
//简单处理结果集,将结果集中的字段名与数据输出
ResultSetMetaData rsmd = rs.getMetaData();
int colCount = rsmd.getColumnCount();
for ( int c = 1; c <= colCount;c++) {
String title = rsmd.getColumnName(c);
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
System.out.print(title);
}
while (rs.next()) {
for (int c = 1; c<= colCount; c++) {
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
Object o = rs.getObject(c);
System.out.print(o.toString());
}
}
}
catch(Exception e){
System.out.println(e);
}
finally{
//关闭连接
if (con!=null) {
try {
con.close();
}
catch(Exception e) {
System.out.println(e);
}
}
}
}
在调用集算器文件时,和普通版集算器的JDBC语法是相同的,这里用"call testQJDBC()"执行,执行后结果如下:

需要注意的是,这个网格文件中的dql(),P.i(),ifpure()等函数,在普通版本的集算器JDBC中是无法使用的。
如果需要了解更多有关企业版集算器的DQL的信息,请阅读考DQL工具 中的相关介绍。
企业版集算器函数简介
在上一小节中,例子中接触了一些只有企业版集算器中才可使用的函数,本节中简单介绍一下这些函数。
|
|
A |
B |
|
1 |
[Moore,Wilson,Johnson,Smith] |
=ifpure(A1) |
|
2 |
=A1.i() |
=ifpure(A2) |
|
3 |
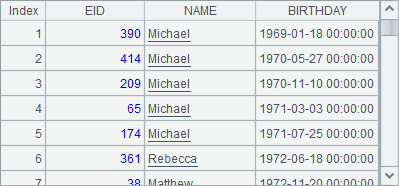
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=ifpure(A3) |
|
4 |
=A3.i() |
=ifpure(A4) |
|
5 |
=A4.o() |
=ifpure(A5) |
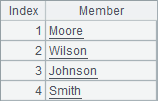
在企业版集算器中,可以使用纯序列,与普通序列不同,纯序列中所有成员的类型都是强制相同的。可以使用A.i() 函数将普通序列A转化为纯序列,用ifpure(A)判断一个序列A是否纯序列。如A1、B1、A2和B2中的执行结果如下:
![]()
![]()
可以看到,普通序列和纯序列,在显示时没有什么区别,只能通过ifpure函数才能判断。
与纯序列类似,如果一个序表中,某个字段的所有数据类型全相同,这样的字段称为纯字段。如果序表中强制所有字段都是纯字段,这样的序表称为纯序表,纯序表是使用列式存储的,使用时需要注意。可以使用T.i() 函数将普通序表T转化为纯序表,用ifpure(T)判断一个序表T是否纯序表。与纯序列类型,纯序表和普通序表显示外观相同,只能通过ifpure函数判断,如上面例子中A3、B3、A4和B4中结果如下:
![]()
![]()
另外,可以用A.o()或者T.o()函数,将一个纯序列A或者纯序表T,转化为普通序列或者普通序表,如A5和B5中结果如下:
![]()
下面,看一下纯序列与普通序列有什么区别:
|
|
A |
B |
|
1 |
[Moore,Wilson,Johnson,Smith] |
=A1.i() |
|
2 |
>A1.insert(0,12) |
>B1.insert(0,12) |
A2执行后,A1中数据会正常改变:

在纯序列中,所有成员是强制同类型的,如果试图在纯序列中插入其它类型的数据,或者改变某个成员为其它类型,都是不允许的。因此B2中命令无法执行,会提示错误:
在纯序表中的情况也类似:
|
|
A |
B |
|
1 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=A1.i() |
|
2 |
>A1(1).BIRTHDAY=20001231 |
>B1(1).BIRTHDAY=20001231 |
A2改变第一条记录的字段值后,A1中序表数据如下:
和纯序列不太一样,由于各个字段均为纯序列,因此在纯序表中不能用insert/delete等添加或者删除整条记录的命令。但是,如果纯序表中的字段值被改变时,会要求类型不能变化,如试图执行B2时,会提示错误:
在纯序表或者纯序列中,由于数据的类型统一,因此在执行定位操作时,效率会有明显提升,如:
|
|
A |
B |
C |
|
1 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=A1.i() |
=A1.(NAME) |
|
2 |
=100000.(C1(rand(500)+1)) |
=now() |
|
|
3 |
=A2.(A1.pselect@1(NAME:A2.~)) |
=now() |
=interval@ms(B2, B3) |
|
4 |
=A2.(B1.pselect@1(NAME:A2.~)) |
=now() |
=interval@ms(B3, B4) |
A1中为普通序表,B1中为纯序表,在A2中生成100,000个随机NAME,在A3和A4中,分别在普通序表和纯序表的EID字段中,查找每个序号的位置。两个序表中得到的结果是相同的:

在C3和C4中,比较两种定位方式的用时,能够看到A4中在纯序表中查找数据时,用时明显更少:
![]()
![]()
需要注意的是,由于纯序表中数据是按列存储的,因此虽然定位效率较高,但是纯序表中的记录在获取数据时需要从每列中按位置获取,就会影响性能了:
|
|
A |
B |
C |
|
1 |
=demo.query("select EID, NAME, BIRTHDAY from employee") |
=A1.i() |
=A1.(NAME) |
|
2 |
=100000.(C1(rand(500)+1)) |
=now() |
|
|
3 |
=A2.(A1.select@1(NAME:A2.~)) |
=now() |
=interval@ms(B2, B3) |
|
4 |
=A2.(B1.select@1(NAME:A2.~)) |
=now() |
=interval@ms(B3, B4) |
和前面例子相比,只是把A3和A4中的定位函数T.pselect()换为了选出函数T.select(),此时A3和A4返回的是记录构成的排列,结果仍然是相同的,只是A4结果中的记录均为纯序表中的记录,纯序表中记录构成的排列称为纯排列,展示时需要从各列中取数:

在C3和C4中,比较两种选出方式的用时,结果如下:
![]()
![]()
此时使用纯序表就没有优势了,因此何时使用纯序列和纯序表,需要根据实际的需求来决定。
数据库中查询得到的表,各个字段通常都能够满足类型相同的条件,在db.query(sql) 函数中,添加@v选项,可以直接返回纯序表作为结果:
|
|
A |
B |
|
1 |
=demo.query@v("select EID, NAME, BIRTHDAY from employee") |
=ifpure(A1) |
|
2 |
=A1.select(left(NAME,1)=="J") |
=ifpure(A2) |
|
3 |
=A1.select@v(left(NAME,1)=="J") |
=ifpure(A3) |
|
4 |
[Rebacca, Matthew, Smith] |
|
|
5 |
=A4.(A1.select@v(NAME==A4.~)).conj() |
=ifpure(A5) |
|
6 |
=A4.(A1.select@v(NAME==A4.~)).conj@v() |
=ifpure(A6) |
|
7 |
=A6.sort@v(BIRTHDAY) |
=ifpure(A7) |
A1和B1中结果如下:
![]()
用函数T.select(sql) 时,如果是纯序表时,返回的结果为纯排列,它其实是由纯序表中记录构成的普通序列。如果添加@v选项,返回的结果将转换为纯序表。与之类似,在纯序列A中也可以用A.select@v(…) 时获得纯序列的结果。A2,B2,A3和B3中结果如下:
![]()
![]()
当计算多个纯序列的和列时,默认情况下只会得到普通序列,也可以在函数A.conj(…)中添加选项@v,得到纯序表。如上例中A5,B5,A6和B6中结果如下:
![]()
![]()
类似的还可以用函数T.sort@v(…),P.sort@v(…),将纯序表T或纯排列P中记录排序后生成纯序表作为结果。如A7和B7中结果如下:
![]()
在使用纯序表,用T.new(…)函数或T.derive(…)函数来产生新序表时,仍然会获得纯序表,此时如果添加@o选项可以利用表中已存在的列来提高效率,例如:
|
|
A |
B |
C |
|
1 |
=demo.query@v("select NAME, SURNAME, STATE, DEPT from employee") |
|
|
|
2 |
=1000.(A1).conj@v() |
=now() |
=ifpure(A2) |
|
3 |
=A2.new(#:ID, NAME/" "/SURNAME:FullName, STATE, DEPT) |
=now() |
=ifpure(A3) |
|
4 |
=A2.new@o(#:ID, NAME/" "/SURNAME:FullName, STATE, DEPT) |
=now() |
=ifpure(A4) |
|
5 |
=interval@ms(B2,B3) |
=interval@ms(B3,B4) |
|
|
6 |
>A2(1).NAME = "New Name" |
>A2(1).STATE = "New State" |
|
A1中数据比较少,因此在A2中将其复制1000遍,再生成纯序表,数据如下:
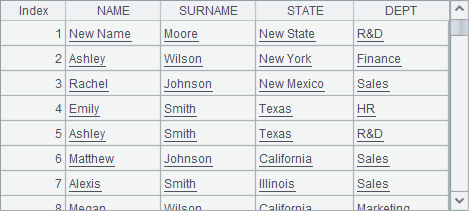
在A3和A4中用T.new(…)函数产生新序表,不同的是A4中添加了@o选项,此时产生新的纯序表时会利用A2中已有的列,为此第6行的代码修改了A2中首条记录的NAME和STATE字段。执行完成后,A3和A4中生成的新序表如下:
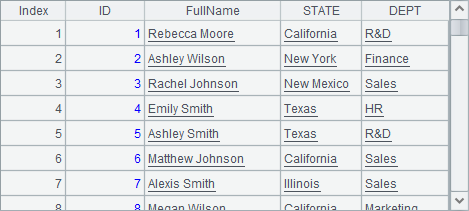

从二者的数据可以看到,虽然是在生成新序表后,修改的原始序表A2中的数据,但A4结果中,第一条记录的STATE字段也被修改了,这是因为此列和A2中是共用的。但是,由于FullName字段是新生成的数据,因此A2中NAME的变化不会影响A4。同时,由于A3中未使用@o选项,它的数据完全不受影响。
从C2、C3和C4的结果可知,A2、A3和A4中均为纯序表:
![]()
![]()
![]()
比较A5和B5中的用时,可以得知使用@o选项时,会有更好的效率。
![]()
![]()
JDBC 调用远程服务器
使用企业版集算器JDBC时,还可以调用远程服务器执行计算。有关远程服务器的配置及启动方法,请查看集群计算章节中 服务器 部分。在使用JDBC调用远程服务器时,需配置文件raqsoftConfig.xml的<JDBC>节点中的<Units>来配置各个远程服务器的ip及端口号:
<JDBC>
<load>Runtime</load>
<gateway>executeSQL.splx</gateway>
<Units>
<Unit>192.168.0.197:8281</Unit>
</Units>
</JDBC>
在JDBC中配置了远程服务器之后,再用Java代码调用JDBC时,执行计算时会优先在本地处理,如果本地无法执行,如找不到数据文件等,才会在远程服务器端执行计算。如果希望将计算交给服务器执行,可以在连接串中添加参数?onlyServer=true,如:
Class.forName("com.esproc.jdbc.QDriver");
con= DriverManager.getConnection("jdbc:esproc:q:local://onlyServer=true");
st = con.createStatement();
ResultSet rs1 = st.executeQuery("=5.(~*~)");
ResultSet rs2 = st.executeQuery("select * from cities.txt where CID<30");
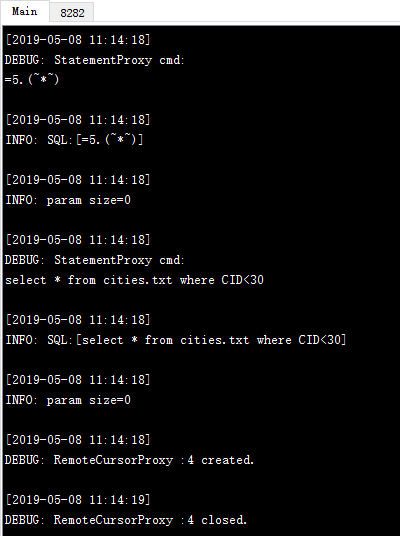
这里用直接执行语句的方式,将ResultSet输出后,结果如下:
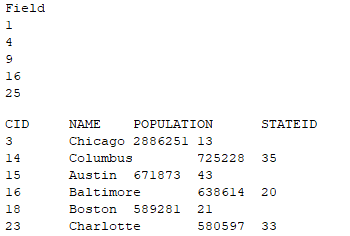
而在远程服务器窗口中,可以看到服务器执行计算的相关信息:
Qvs 与 Qjdbc 简介
如果安装了企业版集算器,那么在产品的安装路径中是包含完整的QVS项目,即企业版集算器多功能服务器。它位于[安装目录]\esProc\q-server目录中,[安装目录]\esProc\q-server\lib目录中则包含着企业版集算器服务器,以及QJDBC所需的各个基础jar包,除去企业版集算器所需jar包之外,如果需要部署企业版集算器中的云存储功能则需要ecloud-xxxx.jar。
QVS的启动文件位于[安装目录]\esProc\bin中的 StartQVS.bat(linux 下为 StartQVS.sh),默认情况下会启动本地的qvs服务器,如果需要了解或者改变相关设置,请阅读云服务部署说明 。成功启动后界面如下:
QJDBC是集成了QVS功能的企业版JDBC,它的驱动类是com.esproc.jdbc.QDriver,使用的URL为jdbc:esproc:q:local://,QJDBC使用时可以直接用下面函数。
|
|
A |
|
1 |
=Qconnect("http://localhost:8090/qvs":"demoqvs",30,300) |
|
2 |
=Qdirectory("test/") |
|
3 |
=Qfile("test/cities.txt") |
|
4 |
=A3.import@t() |
|
5 |
=Qenv("arg1", "Sale") |
|
6 |
=Qenv("arg1") |
|
7 |
=A1.exec@x("test/FindEmployees1.splx";A6) |
|
8 |
>A1.close() |
A1中执行Qconnect(url:v, wt, it),连接指定url的QVS服务器,验证串为demoqvs,最长等待时间30秒,最长闲置时间300秒,连接后即可执行各种远程服务。
A2中用函数Qdirectory(path)查询指定路径下的所有文件名称列表。
A3中用函数Qfile(fn)读取指定文件,返回文件对象,可以继续执行操作,如在A4中将文件中数据导入为序表。
A5中用函数Qenv(name, value)设定全局变量,A6中则读取全局变量。
A7用A1中连接生成的对象执行splx网格文件,这里使用A6中的值作为查询参数,并在A8中关闭连接。网格文件test/FindEmployees1.splx如下:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
>output("before return") |
|
3 |
return A1 |
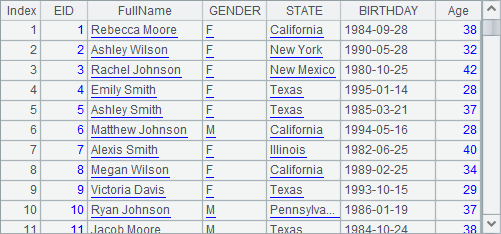
A7中查询结果如下:
上面例子中使用到的Qconnect(),Qdirectory(),Qfile()和Qenv()等函数,是执行QJDBC所使用的函数,它们称为Q函数。QJDBC中支持的Q函数,除了上面介绍的,还有Qmove(),Qload()和Qlock(),如果需要更详细地了解,可阅读《函数参考》。
除了用Q函数访问QVS,还可以在企业版集算器中使用远服务器,相关内容请阅读企业版 RSRV 部署使用说明 。