
控制连接
本节与在数据库中更新数据的内容有关,非应用程序员如不需了解可以跳过,不影响正常阅读。
在处理数据库事务时,有的操作有可能会产生错误,而错误的产生有可能会带来不可预知的操作结果,尤其是在批量事务中。为了避免这种情况的产生,就需要对数据连接进行相应的控制,并对数据库事务中的错误信息进行相应的处理。
数据库错误信息
下面我们先来研究数据库的错误信息。在这里,用一个Access文件DbCon.accdb作为目标数据库,在集算器中,新建一个ODBC数据源,直接使用这个文件中的数据,连接串填入:DRIVER=Microsoft Access Driver (*.mdb, *.accdb);DBQ=D:\\files\\DbCon.accdb:
Access文件DbCon.accdb中,建立了空表CityBak:
![]()
其中ID为主键,特别的,POPULATION设定了限制,要求其中的数据>1,000,000。
现在,准备将demo数据库中,CITIES中的数据,填入CityBak表中:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=connect("DbCon") |
|
3 |
=A2.query("select * from CityBak") |
|
4 |
>A2.update(A1,CityBak,ID:CID,CITY:NAME,POPULATION,STATE:STATEID) |
|
5 |
>A2.close() |
A1从demo数据库中,取出CITIES表中的数据:

A2连接DbCon数据库。A3中,取出CityBak表中的数据,由于是新建的表,里面原本没有记录:

当执行到A4时,就出现了错误,这是由于限定了POPULATION>1000000,当试图填入第10条记录Detroit的信息时,不符合要求。在默认情况下,在数据库运算出现错误时,会中断执行。
在这个时候,我们可以在另一个脚本文件中,查询数据的填写情况:
|
|
A |
|
1 |
=connect("DbCon") |
|
2 |
=A1.query("select * from CityBak") |
|
3 |
>A1.close() |
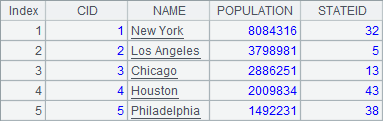
A2中的查询结果如下:

可以看到,虽然由于CityBak表中对数据的限制,致使第1个网格中的程序未能执行成功,但是仍然有部分数据被填入了目标表中,直到出现了无法填入目标表的第1条数据为止。
在批量更新数据库时,一旦出现数据库错误,就会终止程序的运行。为了避免这样的情况,我们可以在产生连接时,使用@e选项,用代码来自行处理数据库错误,而不中断。如:
|
|
A |
B |
|
1 |
=demo.query("select * from CITIES") |
|
|
2 |
=connect@e("DbCon") |
|
|
3 |
>A2.execute("delete from CityBak") |
|
|
4 |
>A2.update(A1,CityBak,ID:CID,CITY:NAME,POPULATION,STATE:STATEID) |
=A2.error() |
|
5 |
=A2.query("select * from CityBak") |
|
|
6 |
>A2.close() |
|
在A2中,生成数据库连接时使用了@e选项,这样在出错时将可以由代码自行处理,而不会中断程序。为了保持与前面的一致,先在A2中将CityBak表中已有的记录清空。运行后,A5中查询到的结果和前面是一致的:
在A4执行更新CityBak表中数据时,由于在更新数据时出现了不符合数据要求的操作,因此可以在B4中看到错误代码:
![]()
说明,在批量更新中,一旦出现数据库错误,就会中断更新数据库,同时记录错误。我们也可以将B4中的表达式修改为=A2.error@m(),此时可以查看到错误信息:
![]()
我们继续探索:
|
|
A |
B |
|
1 |
=demo.query("select * from CITIES") |
|
|
2 |
=connect@e("DbCon") |
|
|
3 |
>A2.update@a(A1.select(CID<6), CityBak,ID:CID,CITY:NAME, POPULATION,STATE:STATEID) |
=A2.error() |
|
4 |
=A2.query("select * from CityBak") |
|
|
5 |
>A2.close() |
|
A3在db.update()中使用@a选项,可以在执行更新前将数据库表中的数据先清除,就不必再添加语句去删除记录。在A3中,仅取出前5条记录,填入CityBak中,此时记录均满足数据要求,A3中的语句执行正常,因此在B3中的错误代码为0:
![]()
而从A4中也可以看到,记录存入正常:
控制提交与回滚
我们无法提前知道批量更新的记录是否全部能成功,也无法知道哪一条记录会产生错误。在默认情况下,每条记录的更新结果都会自动提交,就使结果变得不可预知了,这对于数据库管理可不是一个好现象。
在处理数据库事务时,有时候需要根据情况,来决定是将改动提交到数据库,还是取消操作,这个时候,就需要使用db.commit()和db.rollback()来进行控制。
在默认情况下,在集算器中执行语句都是自动提交的,此时是无法自行控制的。如果想用db.commit()和db.rollback()来进行控制,需要在执行execute或update语句时使用@k选项,用代码控制提交。这样,就可以根据错误信息,来决定数据是否有效了。如下面的例子,在批量执行更新时,如果产生错误,则所有数据全部无效,这样就可以避免数据库中出现不可预知的结果:
|
|
A |
B |
|
1 |
=demo.query("select * from CITIES") |
|
|
2 |
=connect@e("DbCon") |
|
|
3 |
>A2.execute("delete from CityBak") |
|
|
4 |
>A2.update@k(A1,CityBak,ID:CID,CITY:NAME,POPULATION,STATE:STATEID) |
|
|
5 |
if A2.error()==0 |
>A2.commit() |
|
6 |
else |
>A2.rollback() |
|
7 |
=A2.query("select * from CityBak") |
|
|
8 |
>A2.update@k(A1.to(5),CityBak,ID:CID, CITY:NAME,POPULATION,STATE:STATEID) |
|
|
9 |
if A2.error()==0 |
>A2.commit() |
|
10 |
else |
>A2.rollback() |
|
11 |
=A2.query("select * from CityBak") |
|
|
12 |
>A2.close() |
|
A3中,将CityBak中的数据清空,由于在执行db.execute()时未使用@k选项,因此会自动进行提交。
A4中,执行批量更新时,会产生错误,这可以从A5的运算结果中看到:
![]()
因此会执行B6中的回滚操作而不是B5中的提交,数据不会写入数据库。A7中的查询结果如下:
使用@k选项进行批量更新时,如果未产生错误,如A8中执行的语句,也可以根据错误代码判断,A9中值为:
![]()
此时会执行B9中的提交操作,数据写入数据库。A11中的查询结果如下: