
集群组表
本节内容,涉及功能只有企业版集算器才可使用,其它版本的产品用户可以跳过。
在集群服务器 中,介绍了如何使用分机实现集群计算,组表可以通过分机访问,作为集群组表使用。首先,需要把组表文件上传到各个分机的主路径中。此时即可通过访问分机读取组表文件:
|
|
A |
|
1 |
[192.168.1.112:8281] |
|
2 |
=file("employees.ctx",A1) |
|
3 |
=A2.open() |
|
4 |
=A3.cursor().fetch() |
|
5 |
=A3.cursor() |
|
6 |
=A5.groups(Dept;count(~):Count) |
在A2中,使用函数file(fn,h) 从服务器列表h中读取组表文件fn,打开集群文件。这个例子中仅使用了单个分机上的组表文件,A3中得到结果如下:
在A3中用T.open() 打开组表的基表,此时的组表称为集群组表,集群组表的实表称为集群实表。在集群组表中,可以用T.attach(T') 函数取出附表T'。集群表是只读的,在计算时和本地组表是相同的。A4中用T'.cursor()由集群组表的基表T'生成游标,并从游标中取得数据如下:
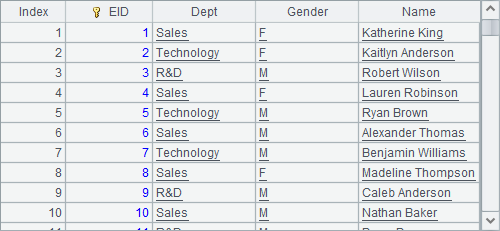
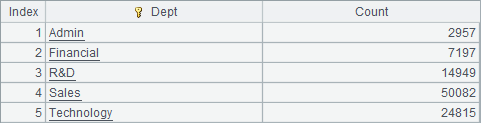
集群组表生成的游标也可以执行cs.join(),cs.groupx(),cs.groups() 等各类计算。如A6中用cs.groups() 得到分组聚合的结果如下:
与组表类似,使用集群组表时,也可以使用集群内表,在内存中使用集群表:
|
|
A |
|
1 |
[192.168.1.112:8281] |
|
2 |
=file@n("D:/file/dw/employees.ctx",A1) |
|
3 |
=A2.open() |
|
4 |
=A3.memory(;right(Name,6)=="Garcia") |
|
5 |
=A4.dup() |
|
6 |
=A5(4) |
|
7 |
>A4.close() |
A2中打开集群文件,与生成本地组表的内表类似,在A4中用memory() 函数生成集群内表,A4中可以查看到集群内表的结果如下:
集群内表并不能直接作为序表使用,可以用T.dup() 函数,将集群内表T转换为本地内表,如A5中结果如下:
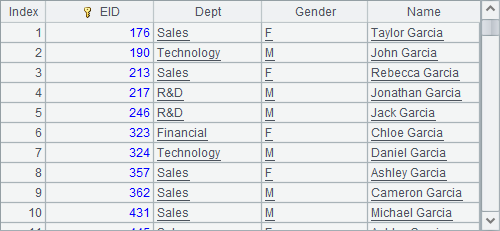
A5中即为普通内表了。普通的内表T也可以用T.dup(h) 函数转换为集群内表。集群内表使用后,应该用T.close() 函数关闭以便清除内存。
另一台分机192.168.1.112:8282上,也同样在主路径中存储了employees.ctx,此时,也可以同时使用两台分机执行查询,如:
|
|
A |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8282] |
|
2 |
=file("employees.ctx", A1) |
|
3 |
=A2.open() |
|
4 |
=A3.cursor() |
|
5 |
=A4.fetch() |
和前面的使用不同的是,A2中打开集群文件时使用了多个分机。而在A4中生成了游标,此时读取相同的组表文件时,将会在分机间拆分处理,但游标的使用和单分机时是相同的。A5中得到结果如下:
在上面的例子中,如果集群文件由各个分机上相同的文件构成,称为复写文件,各个分机上的文件必须完全相同。集群文件还可以由文件组构成,称为集群组文件,这种情况下,各个分机上的文件往往来源于复组表。下面我们来看在集群中如何使用复组表,为此需要使用11.2组表的访问与复组表中使用的学生复组表,如:
|
|
A |
B |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8282] |
|
|
2 |
students.ctx |
D:/file/dw/students.ctx |
|
3 |
for [1,3,5] |
=file(B2:A3) |
|
4 |
|
=movefile@c(B3.name(); "/", A1(1)) |
|
5 |
for [2,4] |
=file(B2:A5) |
|
6 |
|
=movefile@c(B5.name(); "/", A1(2)) |
|
7 |
=file(A2:to(5),A1) |
=A7.open() |
|
8 |
=B7.cursor().fetch() |
>B7.close() |
在第3、4行,将复组表中第1、3、5这三个文件复制到分机A中,第5、6行将复组表中第2、4这两个文件复制到分机B中。A7中用file(fn:zs:, hs)访问集群组文件,其中不用考虑分表到底存储在哪个分机上。在A8中从集群组文件中读取数据如下:
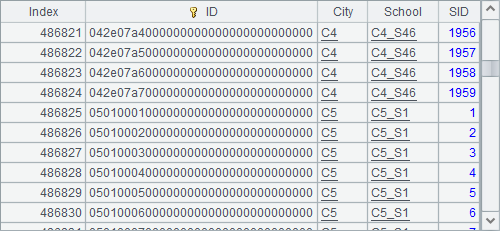
可见,使用时,无需了解复组表中的分表具体存储在哪个分机上,直接访问其中的数据即可自动寻找,各个分表中的数据将会顺次合并在一起返回。由于集群组表需要由各个分机内存区中的数据共同构成,因此对稳定性要求比较高,为了防止个别分机故障造成集群组表无法使用,在使用时可以采用内存容错。如将复组表中的分表文件在各个分机上重复存储,这样在某台分机出现故障或者被其它作业占用时,仍能正常计算。