
集群计算
在集算器中,可以使用集群计算来完成复杂的分析处理工作。在网络中独立的多台计算机上的多个集群服务器,共同组成了集群系统。在网络中的任何一台计算机,均可向集群网络发送集群计算请求。
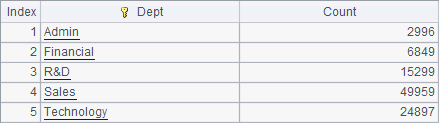
集群系统聚集了多个服务器的计算能力,能够大幅提高性能,又可以随时根据需要扩充规模,同时又不必付出大型计算机的高额成本。
集群计算与 callx 函数
在集群服务器 中,我们了解了在集算器中如何启动集群服务器。当多台集群服务器已经启动,构成了集群系统之后,就可以通过callx函数来执行集群计算了。集算器中的集群计算,将由各台服务器来执行任务,计算指定的脚本文件,并返回结果。
使用集群计算时,先需要准备在子任务计算时使用的网格文件,如下面的CalcStock.splx:
|
|
A |
B |
|
1 |
>output@t("calc begin, SID="+string(arg1) +". ") |
=file("StockRecord.txt").cursor@t() |
|
2 |
=B1.select(SID==arg1) |
=A2.fetch() |
|
3 |
=B2.count() |
=B2.max(Closing) |
|
4 |
=B2.min(Closing) |
=round(B2.avg(Closing),2) |
|
5 |
>output@t("calc finish, SID="+string(arg1) +". ") |
return A3,B3,A4,B4 |
StockRecord.txt文件中存储了一些股票在一段时间内的收盘价格。在每个子任务中,统计指定股票代码的交易信息,包括总交易天数,最高收盘价,最低收盘价,平均收盘价。其中平均收盘价只是简单按日计算均值,不考虑交易笔数。为了了解子程序的执行情况,在开始计算及返回结果前,用output@t函数输出了时间及提示文字。其中,arg1为参数传入股票代码,因为需要在集群计算时设定,所以必须选中Set arguments before run:
在集群计算时,所有运行集群服务器的计算机中,均需要存在子任务使用的网格文件CalcStock.splx,这个文件需要存储在各个服务器配置的mainPath或寻址路径中。
在本例中,运行1个分机A,IP地址是192.168.1.112:8281,分机的最大作业数为3。
此时,即可在网络中任何一台计算机上,在集算器主程序中使用callx函数执行集群计算:
|
|
A |
|
1 |
[192.168.1.112:8281] |
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
3 |
=callx("CalcStock.splx",A2;A1) |
|
4 |
=A3.new(A2(#):SID,~(1):Count,~(2):Maximum,~(3):Minimum,~(4):Average) |
A3的表达式,callx的参数中,分号前为计算网格文件时使用的参数,在集群计算时,将按照参数中的序列类型参数将计算任务拆分为多个子任务,参数序列的长度就是子任务的个数;如果需要使用多个参数,用逗号分隔;其中的单值参数将复制到各个子任务中。callx的参数中,分号后为分机序列,其中每个分机的描述均为一个字符串,格式为分机的"地址:端口号",这个例子中只使用了一个分机:"192.168.1.112:8281"。调用集群服务器完成计算后,需用return返回结果;如果返回多个数据,将会构成序列返回。
例子中共需计算6支股票的数据,代码分别为:124051,128857,131893,136760,139951,145380,将其对应的作业分别设为a,b,c,d,e,f,在集群计算时6个作业会交由分机分配计算。当分机列表中有多台分机时,作业会顺次分配给各个分机,当各个分机中正在执行的作业数已满时,剩余作业暂停分配,直至某个作业执行完毕时继续。如果分机未启动或者没有空闲进程,则继续查看列表中的下一个分机。可以从各个分机的系统信息输出窗口中,看到任务的分配和执行情况,这个例子中只有一个分机,全部执行情况如下:

(接上屏)
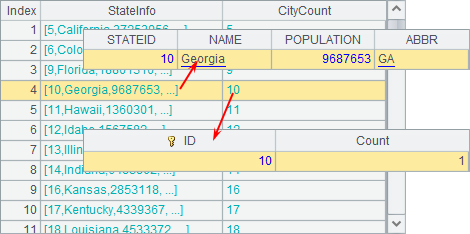
根据系统输出信息可以看到,由于分机上设定的最大作业数为3,因此作业a,b,c首先被分配执行,剩余的作业d, e和f将处于等待状态,等进程空闲后再逐步执行分配。
计算后,可以在A4中查看结果:

这个例子通过集群运算,将主任务需要处理的大量数据拆分,使得每个进程只处理部分数据,能够充分利用计算机的计算能力以提高计算效率,也可以使用多台电脑运行分机来有效地避免大数据量造成的内存溢出。
需要注意的是,作业是由每个线程各自执行的,因此各个作业之间要各不相关。在每个分机上,都必须存储着使用的脚本文件,如果在运算时需要使用数据源或者数据文件,则使用的分机需要有相应的数据源配置,或者存储着相应的数据文件。除了使用callx顺序分配作业之外,还可以使用callx@a,随机分配。
再来看下面的例子,仍然是计算6支股票的统计数据,与前面不同的是每个子任务只统计某1年的数据,使用的网格文件CalcStock2.splx如下:
|
|
A |
B |
|
1 |
>output@t("calc begin, year: "+string(arg1)+". ") |
=file("StockRecord"+string(arg1)+".txt") |
|
2 |
=B1.cursor@t() |
[124051,128857,131893,136760,139951,145380] |
|
3 |
=A2.select(B2.pos(SID)>0).fetch() |
=A3.groups(SID;count(~):Count,max(Closing):Maximum,min(Closing):Minimum,sum(Closing):Sum) |
|
4 |
>output@t("calc finish, year: "+string(arg1)+". ") |
return B3.derive(arg1:Year) |
每年的股票数据存储在不同数据文件中,如2010年的数据存储在StockRecord2010.txt中。计算时会用到2010年至2014年共5个数据文件。在每个作业中,统计各股票在指定年份的交易信息。同样,在开始计算及返回结果前,用output@t函数输出了时间及提示文字。
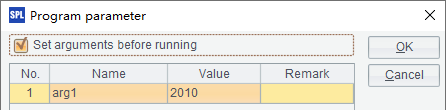
其中,arg1为参数,传入统计年份,并在B4返回的结果中添加,以备查看任务的计算情况:
此时,在主程序中执行集群计算如下:
|
|
A |
|
1 |
[192.168.1.112:8281] |
|
2 |
[2010,2011,2012,2013,2014] |
|
3 |
=callx("CalcStock2.splx",A2;A1; "reduce_addRecord.splx") |
|
4 |
=A3.conj().group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum, round(~.sum(Sum)/~.sum(Count),2):Averge) |
在A3中执行集群计算,在这里使用的是callx(spl,…;h;rspl) 函数,和前面的调用相比,多了reduce脚本文件rspl。这里的reduce脚本中代码如下:
|
|
A |
|
1 |
return arg1|arg2 |
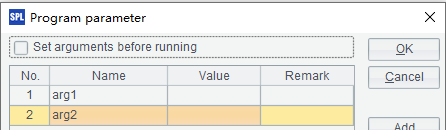
其中arg1和arg2为脚本文件中定义的两个参数:
这里的参数不必赋值,参数的名称也无所谓,在计算时会依次赋值为当前执行reduce的累积结果以及当前作业返回的结果,这个脚本表示将每个作业返回的记录合并起来。每个作业返回结果后都会执行reduce脚本,计算得到新的累积值。执行callx后,从服务器的系统信息输出窗口中,可以看到任务的分配和执行情况如下:
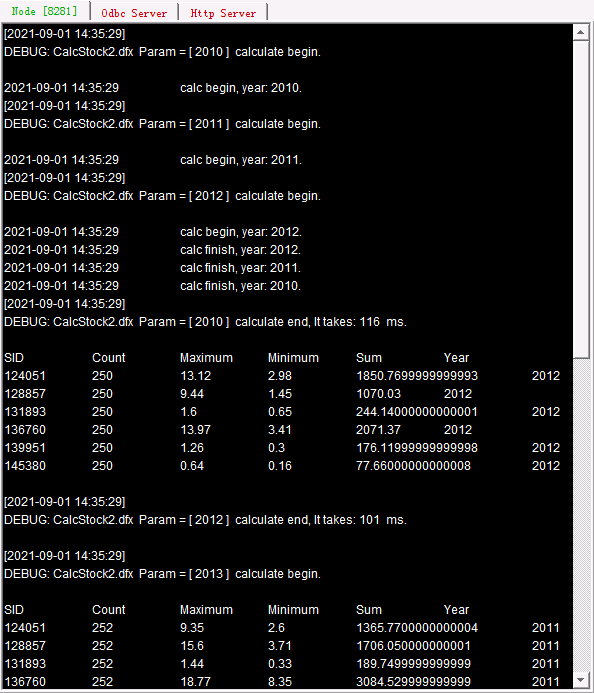
(接上屏)
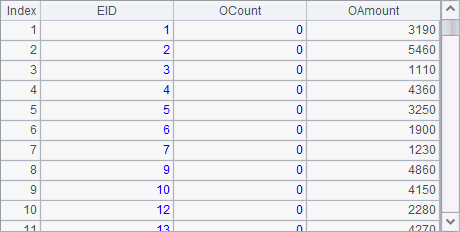
A3中得到一个序列,其中的成员如下:
在添加了reduce动作之后,callx的结果是每个任务返回统计记录构成的排列。
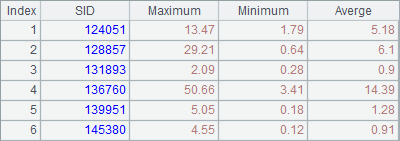
A4中将结果合并后分组汇总,计算每支股票的最高价、最低价和均价,计算后结果如下:
在集群计算时,如果使用多台分机执行计算,如果分机并不能完成全部作业,那么在分配任务时就有可能会产生错误了。如callx函数中无选项,执行时子任务将严格分配到依次对应的服务器,作业数需要等于分机数。
如再添加一个分机B:192.168.1.112:8282,在这个分机的主路径中,只存储了StockRecord2010.txt、StockRecord2011.txt和StockRecord2012.txt这3个数据文件。尝试用下面的代码执行集群计算:
|
|
A |
|
1 |
[192.168.1.112:8281,192.168.1.112:8282] |
|
2 |
[2010,2011,2012,2013,2014] |
|
3 |
=callx("CalcStock2.splx",A2;A1; "reduce_addRecord.splx") |
|
4 |
=A3.conj().group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum, round(~.sum(Sum)/~.sum(Count),2):Averge) |
这个例子中,使用了多个分机构成的集群系统,在计算任务分配作业时,将轮流向各个分机中分配。具体一些,作业2010分配给分机A,2011分配给分机B,接着2012再分配给分机A,然后2013分配给分机B,此时,由于分机B上数据文件缺失,执行时会出现错误:
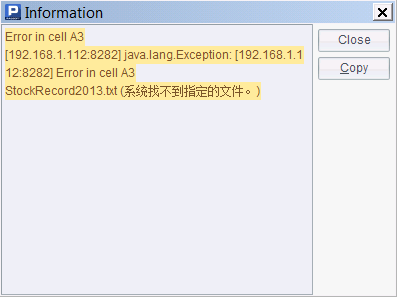
在分机的集群服务器信息窗口中,可以看到产生错误的具体情况:
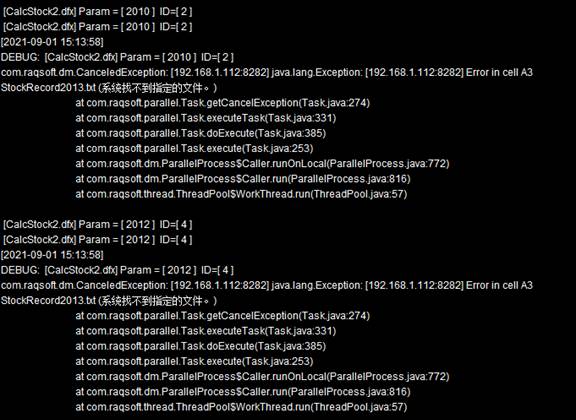
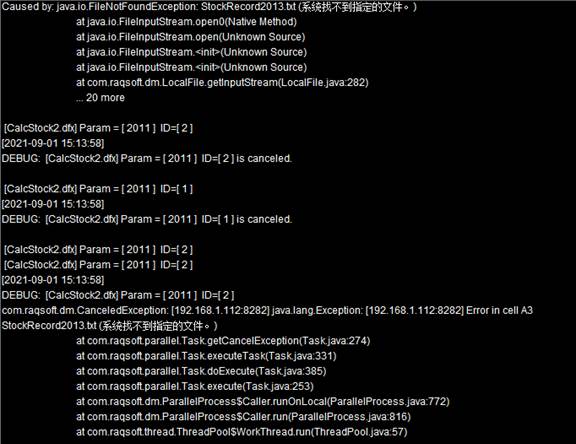
为了避免这样的情况出现,可以修改callx函数中执行的脚本,可能产生计算错误前用end语句表示非正常结束,交给集群系统重新分配,如修改CalcStock2.splx中的代码为CalcStock3.splx如下:
|
|
A |
B |
|
1 |
>output@t("calc begin, year: "+string(arg1)+". ") |
=file("StockRecord"+string(arg1)+".txt") |
|
2 |
if !B1.exists() |
end B1.name()+" not found!" |
|
3 |
=B1.cursor@t() |
[124051,128857,131893,136760,139951,145380] |
|
4 |
=A3.select(B3.pos(SID)>0).fetch() |
=A4.groups(SID;count(~):Count,max(Closing):Maximum, min(Closing):Minimum,sum(Closing):Sum) |
|
5 |
>output@t("calc finish, year: "+string(arg1)+". ") |
return B4.derive(arg1:Year) |
实际上就是添加了第2行,如果B1中的文件不存在,用end语句返回非正常结束信息说明文件不存在。
|
|
A |
|
1 |
[192.168.1.112:8281,192.168.1.112:8282] |
|
2 |
[2010,2011,2012,2013,2014] |
|
3 |
=callx("CalcStock3.splx",A2;A1; "reduce_addRecord.splx") |
|
4 |
=A3.conj().group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum, round(~.sum(Sum)/~.sum(Count),2):Averge) |
此时执行就能正常计算了。执行后,从A3中可以看到任务的分配情况:

任务在分配时,仍然是按照顺序,把2010,2012,2014年的计算交给分机A,2011,2013年的计算分配给分机B,当分机B计算2013年作业发现找不到文件时,会执行end返回重新分配给分机A,使得计算得以正常完成。各个分机中的系统信息如下:
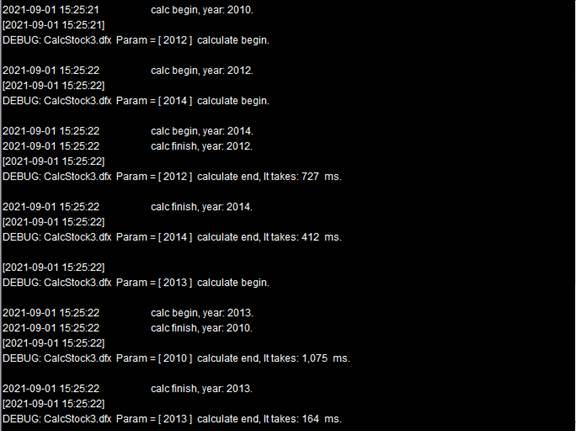
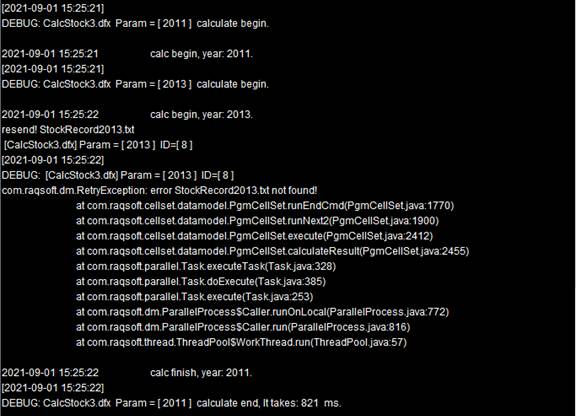
可以看到,作业2013年计算在分机B上执行失败后,返回集群系统重新分配,此时分机A中已经有作业完成能够分配,所以2013年的计算作业也由分机A完成。注意,此时A4中统计所有数据时,需要先将2个分机返回的结果合并起来。A3中结果如下:
这里得到的结果和用单个分机时的情况是相同的。
从上面的例子可以看到,如果一些作业只能由特定的分机计算,会带来一些麻烦,需要在调用脚本中用end语句控制非正常结束。否则,如果某个服务器出现异常,甚至会使得主任务无法完成。如果为了防止像上面例子中,各个分机中文件不统一的情况,也可以用callx执行脚本,在脚本代码中调用syncfile(hs, p) 函数,同步分机列表hs中路径p中的所有文件,同步时如遇同名文件会用较新的文件替代旧的。
在某些情况下,还可以由多台分机同时执行一个作业,如:
|
|
A |
|
1 |
[192.168.1.112:8281,192.168.1.112:8282] |
|
2 |
[2010] |
|
3 |
=callx@1("CalcStock3.splx",A2;A1) |
|
4 |
=A3.conj() |
这里的例子中,只统计2010年单年的股票数据,而且相应的数据文件两个分机上都有。执行call() 函数时添加了@1选项,此时单一的作业会重复分给所有分机计算,当任何一个分机上的作业执行完毕时,其它分机的任务就会中断。执行后两个集群服务器窗口中显示的信息如下:
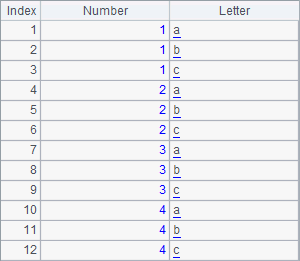
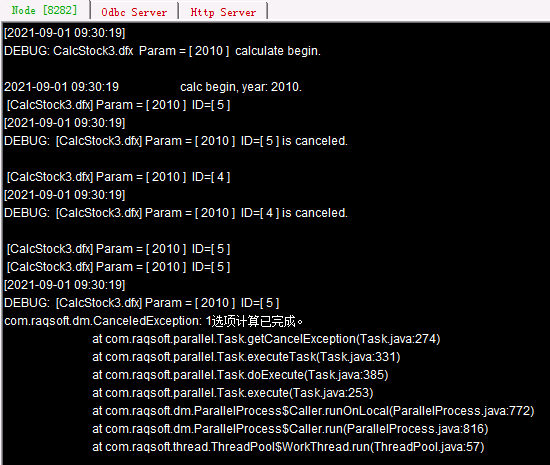
可以看到,分机A上的计算完成后,分机B上的作业自动中断了。A4中得到的结果如下:
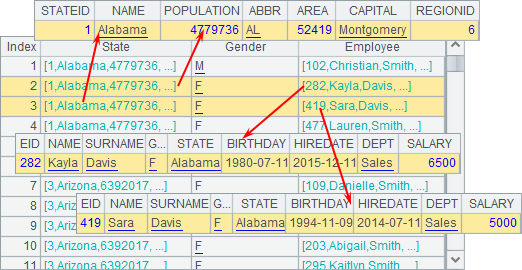
使用@1选项,可以执行类似随机查找之类的任务,由多台分机同时处理,直到某台分机得到了结果。
用 fork 语句执行集群计算
在多线程中,我们介绍了fork语句的使用,可以多线程执行一段代码。实际上,上一小节中使用的callx就是在集群中的各个服务器端,执行某个脚本文件中的代码。
所以,callx的计算,也可以用fork来处理,如:
|
|
A |
B |
C |
|
1 |
[192.168.1.112:8281] |
|
|
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
|
|
3 |
fork A2;A1 |
>output@t("calc begin, SID="+string(A3) +". ") |
|
|
4 |
|
=file("StockRecord.txt").import@t() |
=B4.select(SID==A3) |
|
5 |
|
=C4.count() |
=C4.max(Closing) |
|
6 |
|
=C4.min(Closing) |
=round(C4.avg(Closing),2) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
return B5,C5,B6,C6 |
|
8 |
=A3.new(A2(#):SID,~(1):Count,~(2):Maximum, ~(3):Minimum,~(4):Average) |
|
|
这其实相当于把集群计算中需要重复执行的子网格直接写入了代码块中,可以不必维护多个脚本文件。使用多个分机时,如果需要指定分机,可以在fork函数的最后添加分机执行的作业序号序列s,如fork A2;A1:[[4,5],[1,2,3]]。A3中,收集每个作业返回的结果如下:
在返回结果序列时,A3中的结果和参数的顺序是一致的,A8将集群结果整理后,得到下表:

这里只使用了一个分机,从集群服务器窗口中可以看到执行情况:
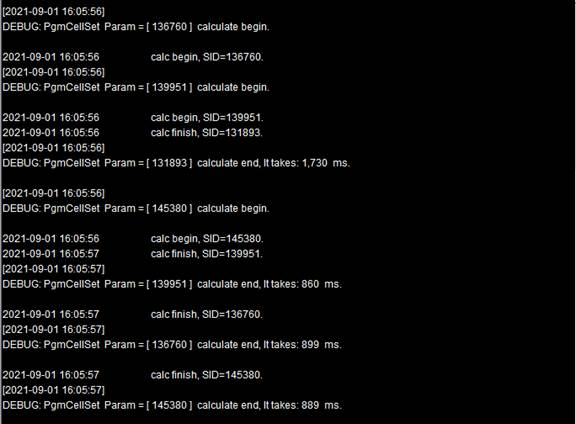
在fork的使用模式里,也可以添加reduce动作,如:
|
|
A |
B |
C |
|
1 |
[192.168.1.112:8281] |
|
|
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
|
|
3 |
fork A2;A1 |
>output@t("calc begin, SID="+string(A3) +". ") |
|
|
4 |
|
=file("StockRecord.txt").import@t() |
=B4.select(SID==A3) |
|
5 |
|
=C4.count() |
=C4.max(Closing) |
|
6 |
|
=C4.min(Closing) |
=round(C4.avg(Closing),2) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
return A3,B5,C5,B6,C6 |
|
8 |
reduce |
=if(ift(A3),A3.record(A8),create(SID, Count, Maximum, Minimum, Average ).record(A3).record(A8)) |
|
|
9 |
=A3.conj() |
|
|
在reduce代码块中,添加了reduce动作的函数,在第一次reduce动作时,新建结果序表,并将当前累积值A3中的首个作业结果以及A8返回的当前的第二个作业结果数据填入,之后的reduce动作则相应在结果序表中添加记录。在reduce和fork的代码块中,A3的值是不同的,fork模块中A3中输入参数,reduce代码块中A3中为累计结果。执行后,在A3中可以看到执行集群计算的结果:
这里只使用了一台分机,其返回的序表即为所需的统计结果。
用fork语句也可以同时使用多个分机执行计算,如:
|
|
A |
B |
C |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8282] |
|
|
|
2 |
[2010,2011,2012,2013,2014] |
[124051,128857,131893,136760,139951,145380] |
|
|
3 |
fork A2;A1 |
>output@t("calc begin, year: "+string(A3)+". ") |
=file("StockRecord"/A3/".txt") |
|
4 |
|
if !C3.exists() |
end C3.name()+" not found!" |
|
5 |
|
=C3.cursor@t() |
|
|
6 |
|
=B5.select(B2.pos(SID)>0).fetch() |
=B6.groups(SID;count(~):Count,max(Closing):Maximum, min(Closing):Minimum,sum(Closing):Sum) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
result C6.derive(A3:Year) |
|
8 |
reduce |
=A3|A8 |
|
|
9 |
=A3.conj(). |
|
|
这里用fork分别计算指定的一些股票的各年数据,在fork的代码块中,先在第4行判断所需数据文件是否存在,如分机无法找到文件用end返回非正常结束信息,使该作业重新分配给其它分机处理。在第8行用reduce语句把每次得到的结果记录合并起来。执行时,和上一节中在reduce脚本中添加end语句的情况类似,在分机无法计算某个作业时会重新分配,使用的两个分机的信息如下:

同样是2013年的计算按默认顺序分配给了分机B,计算非正常结束后重新分配给分机A。值得注意的是,无论是reduce语句还是reduce脚本,在处理reduce动作时只会在单一的分机端累积计算,在单一分机端执行的顺序是和每个作业的执行速度以及分配顺序有关的。因此,在A9返回的结果如下,可以看到得到的结果是和分机和计算顺序有关的:
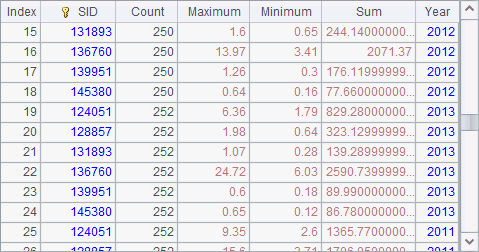
在计算后,这里得到的结果通常需要再次排序整理。如果这里不使用reduce语句,那么得到的结果则和参数顺序一致。
用集群计算处理大运算量任务
前面的例子是用集群计算来处理大数据量的运算,在每个子任务中只处理部分数据,从而更充分地利用有限的内存。还有一种情况,是需要完成大运算量的任务,此时也可以使用集群计算,将运算分配到多个服务器中执行,在主程序中汇总结果。
如下面的子程序CalcPi.splx:
|
|
A |
B |
C |
|
1 |
1000000 |
0 |
>output@t("Task "+ string(arg1)+ " start...") |
|
2 |
for A1 |
=rand() |
=rand() |
|
3 |
|
=B2*B2+C2*C2 |
|
|
4 |
|
if B3<1 |
>B1=B1+1 |
|
5 |
>output@t("Task "+ string(arg1)+ " finish.") |
return B1 |
|
参数arg1用来记录任务序号:
这是一个用概率来估算圆周率π的程序。先来看下面的图:
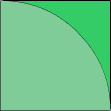
在边长为1的正方形中有1/4个圆,正方形的面积为1,扇形的面积为π/4。那么正方形中的任意1个点落在扇形内的概率就是它们的面积比,也就是π/4。在子程序中,随机生成1,000,000个横纵坐标在[0,1)区间内的点,考察它们距原点的距离,并记录下在扇形内的点的个数,以此来估算π。
主程序如下:
|
|
A |
B |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8281, 192.168.1.112:8283] |
20 |
|
2 |
CalcPi.splx |
=movefile@cy(A2;"/", A1) |
|
3 |
=callx(A2, to(B1);A1) |
=A3.sum()*4/(1000000d*B1) |
先启动第3个分机C,主路径为D:/files/node3。在上面的代码中,调用前用movefile() 函数先将所需脚本文件复制到各个分机中,添加了@c和@y选项,复制文件不删除源文件,如遇同名文件覆盖。通过调用20次子程序,用集群计算将20,000,000个点的计算分配到服务器完成,仍然使用前面的服务器。可以在各个集群服务器的系统信息输出窗口中,看到任务的分配和执行情况:
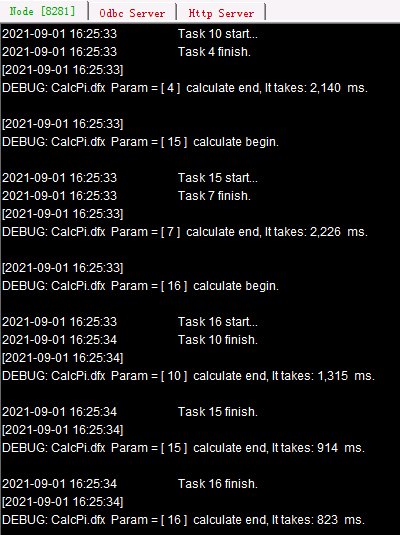
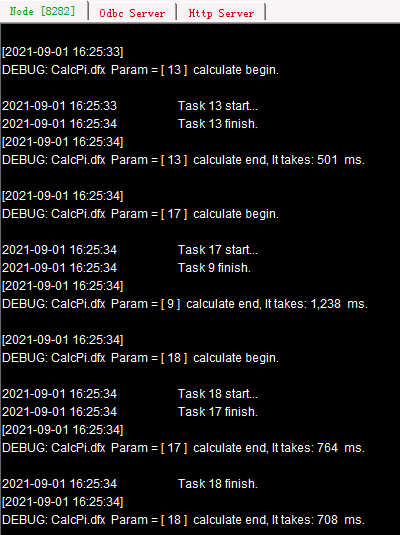
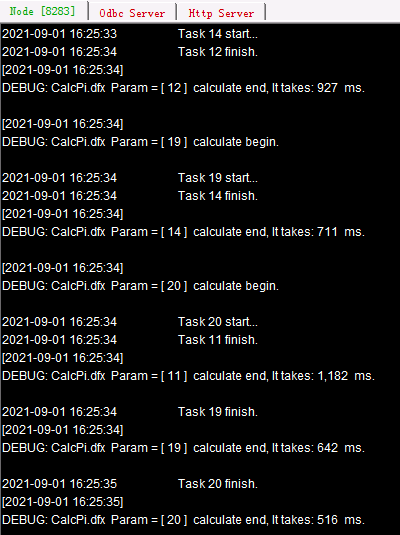
如果作业总数超过了分机容纳任务总数,当前面任务分配至各个分机进程均已占满时,后面的任务需要等待有进程空闲下来再分配。此时进程出现空闲,任务就会被分配到哪个服务器,每次分配的情况是有可能变化的。各个作业的计算过程各自独立,因此后分配的作业也有可能会先完成,但是并不会影响集群计算结果。
在B2中计算出π的近似值如下,由于是用概率随机计算的,每次获得的结果均有差别:
![]()