
简单 SQL
本章介绍简单SQL的基础使用和在集算器ODBC中使用简单SQL。
简单 SQL 的基础使用
集算器可以直接使用txt文件、csv文件、btx等直接用于查询,查询时使用的语法类似于从数据库中查询的SQL语句,称为简单SQL。这些数据文件称为外部数据,能够类似普通序表一样用来查询,称为外部表。如:
|
|
A |
|
1 |
$()select * from cities.txt |
|
2 |
$select * from D:/files/txt/cities.txt where STATEID=5 |
|
3 |
$select STATEID, count(*) AS Cities from cities.txt group by STATEID |
和已连接数据库时,使用SQL在数据库中查询数据类似,也可以在$符号后面直接使用类似SQL的语句从外部表中查询数据。如果当前存在数据源连接,$后接语句会默认在数据库中执行,如果需要使用简单SQL从外部文件中查询,可以在$后添加(),如A1中从文件cities.txt中查询结果如下:
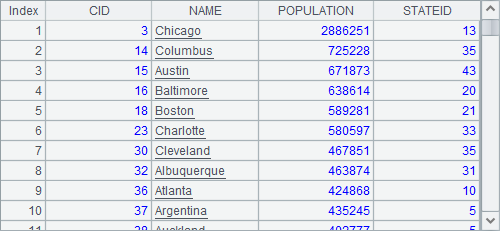
A1中使用的简单SQL和SQL语句的不同之处主要就是表名是文件名。如果不写明文件路径,文件需要置于集算器的主路径中。查询时,使用文件的类型由扩展名决定,在简单SQL中可以使用txt或csv为后缀名的文本文件,xls或xlsx为后缀名的的Excel文件以及btx后缀名的集文件。
使用简单SQL,也可以添加筛选语句where或者计算聚集计算的结果,如A2中查询STATEID为5的城市信息,A3中查询每个州中记录的城市数。A2和A3中的结果分别如下:
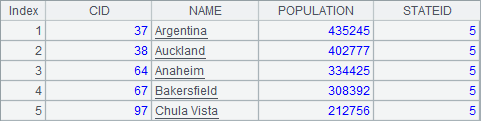
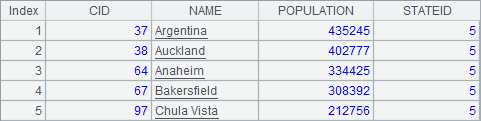
与通常的SQL语法类似,在使用聚合函数执行聚集计算时,往往需要配合group by执行的分组运算。除了例子中使用的count之外,还可以在简单SQL中使用sum/max/min/distinct等聚合函数。
使用简单SQL在外部表中查询时,外部表的文件名也可以用全路经表示,如A2中使用的情况。
从外部表中查询数据时,可以返回部分数据,如:
|
|
A |
|
1 |
$select top 5 CID, NAME, POPULATION from cities.txt |
|
2 |
$select CID, NAME, POPULATION from cities.txt limit 2 offset 3 |
|
3 |
$select * from cities.txt where STATEID < 20 and POPULATION<300000 |
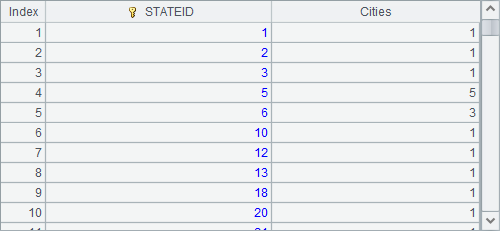
A1中用top n取出前n条数据如下:
A2中,用limit n offset m执行分页查询,略过前m条数据后,取出n条数据,结果如下:
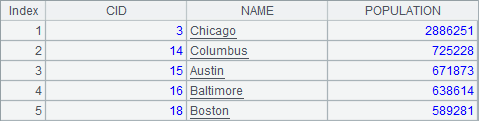
实际上,用where筛选数据时,也可以返回部分数据,如果有多个筛选条件,可以类似SQL中的规则,用and连接。根据需要,还可以使用or/not等逻辑运算。A3中结果如下:
在简单SQL中,可以为查询的表或者字段设置别名,如:
|
|
A |
|
1 |
$select CID as ID, NAME as CITY, POPULATION as POP from cities.txt |
|
2 |
$select CID ID, NAME CITY, POPULATION POP from cities.txt |
|
3 |
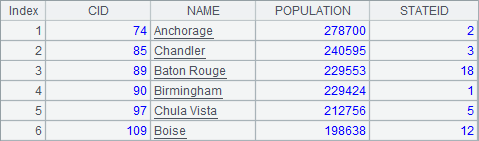
$select distinct _file, _ext, _size, _date from cities.txt |
|
4 |
=A3.derive(datetime(_date):date) |
与通常的SQL语法类似,设置别名时可以用as,也可以省略,A1和A2中结果是相同的,如下:

除了数据表中的字段之外,还可以查询文件信息,用_file, _ext, _size, _date分别返回文件的名称,扩展名,文件大小和最后修改时间。在查询文件信息时,用distinct去除重复信息,A3中得到结果如下:
![]()
其中最后修改时间可以通过计算转换为日期时间,A4中结果如下:
![]()
简单SQL中,可以用join/left join/right join/full join等子句连接多表组合查询,如:
|
|
A |
|
1 |
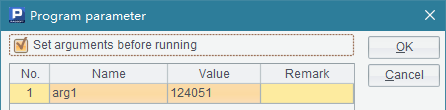
$()select * from states.txt |
|
2 |
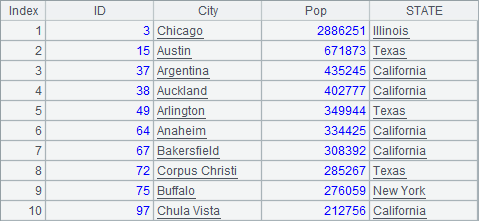
$select C.CID as ID, C.NAME as City, C.POPULATION as Pop, S.NAME as STATE from cities.txt C join states.txt S on C.STATEID = S.STATEID |
|
3 |
$select C.CID as ID, C.NAME as City, C.POPULATION as Pop, S.NAME as STATE from cities.txt C full join states.txt S on C.STATEID = S.STATEID |
|
4 |
$()select C.CID as ID, C.NAME as City, C.POPULATION as Pop, S.NAME as STATE from cities.txt C left join states.txt S on C.STATEID = S.STATEID |
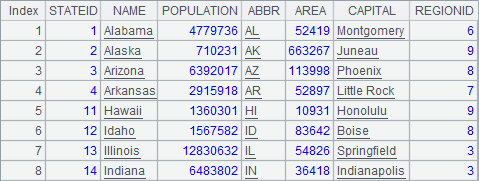
A1中可以看到states.txt文件中存储了部分州信息数据:
A2,A3和A4中将城市信息表和州信息表数据连接查询,分别执行了内连接,全连接和左连接,得到的结果分别如下:

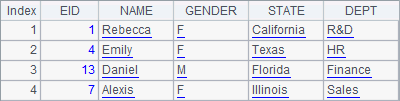
在执行分组计算时,可以用group by n指定使用select中使用的第n个字段或表达式去分组,如:
|
|
A |
|
1 |
$select STATEID, count(*) Cities from cities.txt group by STATEID |
|
2 |
$select STATEID, count(*) Cities from cities.txt group by 1 |
|
3 |
$select STATEID, count(*) Cities from cities.txt group by STATEID having Cities > 1 |
|
4 |
$select STATEID, count(*) Cities from cities.txt group by STATEID having Cities > 1 order by Cities |
A2中的结果与A1中一致,如下:
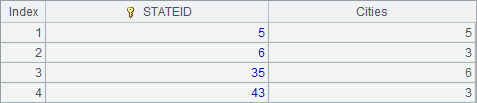
A3中用having在分组时执行过滤,结果如下:
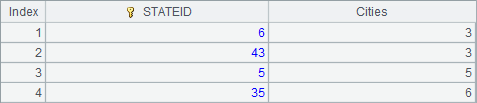
A4中在分组过滤后,又用order by对结果执行排序,结果如下:
与group by n类似,使用order by排序时,也可以用order by n使用select中的字段序号来排序。
使用简单SQL时,可以使用通配符,从多个名字相似,结构相同的外部文件中查询数据,如:
|
|
A |
|
1 |
$(demo) select * from STATES where STATEID<5 |
|
2 |
$select * from STATES where STATEID>10 and STATEID<15 |
|
3 |
$()select * into statePart1.txt from {A1} |
|
4 |
$select * into statePart2.txt from {A2} |
|
5 |
$select * from statePart*.txt |
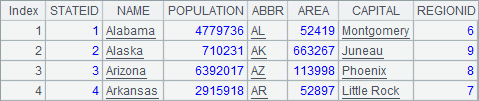
A1和A2从数据库demo中查询部分州信息,结果分别如下:
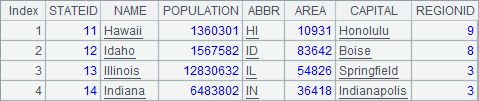
在A3和A4中,用select… into子句将A1和A2中的数据分别存入外部文件statePart1.txt和statePart2.txt,存储时会根据文件扩展名决定文件类型。由于前面执行的是数据库中的查询,因此A3中在外部数据中执行简单SQL时需要用$()开头,而在简单SQL中,如果需要调用集算器中的表达式,需要用{}括起来,如用{A1}调用A1中的结果序表。
A5中,用通配符查询,从所有名称满足statePart*.txt的数据文件中获取数据,并拼接起来,此时需要保证这些文件中数据的结构是相同的。A5中结果如下:
在集算器 ODBC 中使用简单 SQL
本节内容,非应用程序员可以跳过,不影响正常阅读。
集算器中使用的外部数据,可以是txt、csv、xls、xlsx这些常见数据文件,也可以是集算器的集文件,有关集文件的说明,可以阅读集文件 中的内容。另外,外部数据还可以使用组表的基表,有关组表基表的说明,请阅读组表的生成。
除了在集算器中直接调用简单SQL以外,也可以在集算器ODBC中使用简单SQL来使用外部表查询,如:
|
|
A |
|
1 |
=esProcOdbc.query("select PName, SalesID, Date from Order_Electronics.txt where Amount>200000 and month(Date)=5") |
|
2 |
$(esProcOdbc) select Date, count(ID) as Count, sum(Quantity) as Sum from Order_Electronics.txt group by Date |
|
3 |
$(esProcOdbc) select Date, count(ID) as Count, sum(Quantity) as Sum from Order_Electronics.txt group by 1 |
|
4 |
$(esProcOdbc) select Date, count(ID) Count, sum(Quantity) Sum from Order_Electronics.txt group by Date having sum(Quantity)>110000 order by Sum |
txt文件作为外部表时,需要使用制表符tab作为列分隔符。
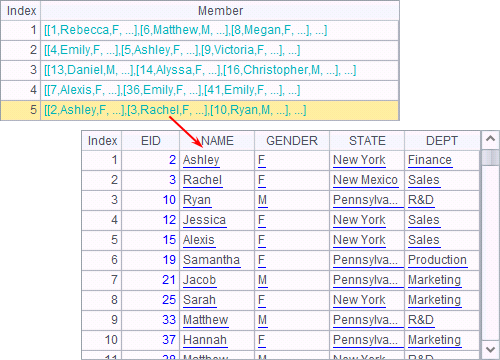
在A1中,在简单SQL中使用where限制了查询条件,查出5月份销售额大于200,000的订单数据,结果如下:
在简单SQL的查询条件里面,可以使用like, in, is null等关键字,以及case when else end语句,功能与SQL中相同。
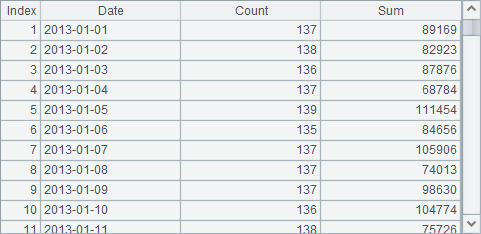
在A2的简单SQL中,用group by从句按Date分组,并用聚合函数count和sum计算出每日订单总数和总销售件数,同时用as定义了一些结果字段的名称。在简单SQL中,除了count和sum外,还可以使用max/min/distinct等聚合函数。另外,在简单SQL中,还可以用top n取出前n条记录,或者用limit n offset m在结果中跳过m条记录后取出n条记录。A2中查询结果如下:
在A3的简单SQL中,group by后并未使用字段名,而是用序号1表示用select中的第1个表达式来分组,结果和A2中是相同的。
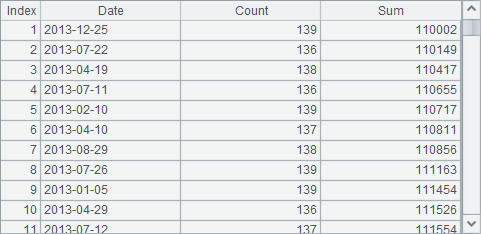
A4中的查询,在分组后,用having从句,从结果中选出sum(Quantity)大于110,000的数据,另外语句中将as省略写为空格,并在最后用order by语句,将结果按照Sum升序排列。查询结果如下:
在简单SQL中,还可以将两个外部表执行连接,如:
|
|
A |
|
1 |
$(esProcOdbc) select StateId, Name, Abbr from states.txt |
|
2 |
$(esProcOdbc) select NAME,POPULATION,STATEID from cities.txt |
|
3 |
$(esProcOdbc) select C.NAME,C.POPULATION, S.StateId, S.Abbr from states.txt S join cities.txt C on S.StateId=C.STATEID |
|
4 |
$(esProcOdbc) select C.NAME,C.POPULATION, S.StateId, S.Abbr from states.txt S left join cities.txt C on S.StateId=C.STATEID |
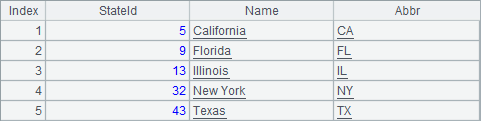
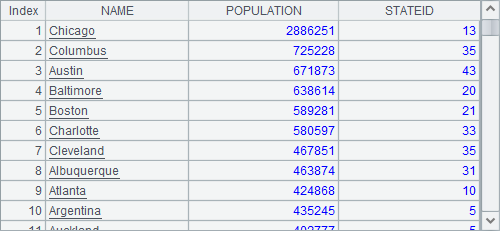
A1、A2中,从states.txt和cities.txt中查询出数据,A1、A2中结果分别如下:
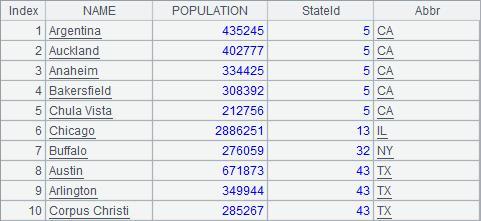
A3中,用join语句将两个外部表关联,列出能找到对应州简称的城市信息,如下:
A4中执行关联时,使用了左连接left join,结果如下:
外部表的定义,也可以用with写在前面,如:
|
|
A |
|
1 |
$(esProcOdbc) with C as (select * from cities.txt), S as (select * from states.txt) select C.NAME,C.POPULATION, S.StateID, S.Abbr from S join C on S.StateID=C.STATEID |
|
2 |
$(esProcOdbc) with C as (select * from cities.txt), S as (select * from states.txt) select C.NAME Name,C.POPULATION Population, S.StateID StateID, S.Abbr Abbr into citiesInfo.btx from S join C on S.StateID=C.STATEID |
|
3 |
$(esProcOdbc) select * from citiesInfo.btx |
A1中的查询结果和上一个例子中A3中的结果是相同的。
在A2中,用select…into T…语句,将查询结果存储入一个外部表T中。存储成功后,在A3中即可从对应的外部文件中读取出存储的结果: