
活用字符串
在集算器中,字符串不仅仅是一种数据类型。字符串还可以作为宏或者字符串常数组成表达式,也可以用在eval() 函数中,用来根据需要动态生成表达式。
宏
集算器中的宏,就是用来组成表达式的字符串,只不过这部分字符串通常是动态生成的。宏往往是一个参数的值或是表达式的计算结果。使用时,宏用符号${}括起来,集算器将先计算${…}里的…表达式,将计算结果作为宏字符串值替换${}。如:
|
|
A |
B |
|
1 |
[+,-,*,/] |
=A1(rand(4)+1) |
|
2 |
=rand(1000) |
=rand(1000) |
|
3 |
=A2${B1}B2 |
|
B1从A1的操作符列表中,随机获取一种四则运算符号,A2和B2随机生成两个1000以内的整数,在A3中计算四则运算的结果。
如B1、A2、B2中的结果如下:
![]()
![]()
![]()
那么,此时A3中即为计算236-393的结果:
![]()
其中,${B1}即为宏,使用时根据不同的符号动态拼成表达式。
需要注意的是,如果宏用在双引号括起的字符串中,则不会执行宏替换。如:
|
|
A |
B |
|
1 |
A"+"A |
" |
|
2 |
="aabb${A1}ccdd" |
|
|
3 |
=${B1}aabb${A1}ccdd" |
|
A2中的${A1}没有作用,最终A2中的结果就是引号中的字符串:
![]()
而在A3中,将左边的双引号改为另一个宏,此时这两个宏就都不在引号内了,宏是有效的,会被用来拼成表达式="aabbA"+"Accdd",计算后,A3中的结果如下:
![]()
从上面的使用中可以看到,宏与字符串参数不同,宏是表达式的一部分,常用在需要动态生成表达式时。
宏经常用来根据名称来动态调用不同的单元格值,调用不同的函数,或者动态使用不同参数等,这种需求有时候很难用固定的表达式来实现,使用宏是一种很方便的选择。如:
|
|
A |
B |
|
1 |
4779736 |
AL |
|
2 |
710231 |
AK |
|
3 |
6392017 |
AZ |
|
4 |
2915918 |
AR |
|
5 |
37253956 |
CA |
|
6 |
=[A1:A5].pselect(~>5000000) |
|
|
7 |
=B${string(A6)} |
|
在A6中,找到第一个人口大于5,000,000的数据所在的行;在A7的表达式中,根据这个行号取出B列中对应的单元格名称,从而获得该州的缩写。需要注意,宏中的表达式必须返回一个字符串,因此在A7中用宏生成单元格名称时,需要用string() 函数将A6中获得的行号转换为字符串。A6和A7中的结果如下:
![]()
![]()
需要注意的是,如果单元格中使用了宏,只会在第一次解析,因此,宏不适合循环使用,如:
|
|
A |
B |
|
1 |
4779736 |
AL |
|
2 |
710231 |
AK |
|
3 |
6392017 |
AZ |
|
4 |
2915918 |
AR |
|
5 |
37253956 |
CA |
|
6 |
=[A1:A5].pselect@a(~>5000000) |
|
|
7 |
=A6.(B${string(A6.~)}) |
|
此时,在A6中返回所有人口大于5,000,000的数据所在的行:
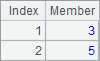
在A7中,根据A6中的序列循环,试图每次取出对应州的简称,结果如下:
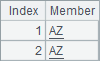
由于宏中的字符只是在第一次解析表达式时置换,因此循环时获得的州简称全都是第一次完成宏替换时计算的结果AZ。
在使用宏时必须明确,宏是用来生成表达式的,不能用来生成命令语句,如for,func等。
eval 函数
集算器中的eval(x, …)函数,可以将x计算出的字符串转为表达式,并计算出它的值。函数eval和宏的使用有类似之处,它们都会生成一个表达式,不同的是,宏只改变部分表达式,而eval是一个函数,在计算它时会生成一个新的表达式并返回其计算结果,而且可以在这个表达式中使用参数。
既然eval函数在计算时需要生成一个表达式,所以在使用时,表达式x的计算结果必须是字符串,如:
|
|
A |
B |
|
1 |
[+,-,*,/] |
=A1(rand(4)+1) |
|
2 |
=rand(1000) |
=rand(1000) |
|
3 |
=eval("A2"+B1+"B2") |
|
仍然是随机生成一个四则运算表达式,在A3中计算结果。
如B1、A2、B2中的结果如下:
![]()
![]()
![]()
在A3中可以看到eval()函数与前面使用宏时的不同,此时A3中即为计算893+466的结果:
![]()
eval函数的功能比宏更为强大,在生成的表达式中使用参数时,可以实现类似自定义函数的功能,如:
|
|
A |
|
1 |
=eval("?.count(~>5)",[2,3,4,5,6,7,8]) |
|
2 |
=eval("if (?1>0 && ?2>0 && ?3>0 && ?1+?2>?3 && ?1+?3>?2 && ?2+?3>?1)",3,2,5) |
在A1中,用eval函数计算一个系列中大于5的成员个数,eval生成的表达式中?代表使用的参数。A2中判断3个参数能否构成一个三角形的三边长,其中?1,?2和?3分别代表第1个,第2个和第3个参数。A1和A2中的计算结果如下:
![]()
![]()
在使用eval函数时,生成的表达式会在每一次运算时解析,因此,它可以循环使用,如:
|
|
A |
B |
|
1 |
4779736 |
AL |
|
2 |
710231 |
AK |
|
3 |
6392017 |
AZ |
|
4 |
2915918 |
AR |
|
5 |
37253956 |
CA |
|
6 |
=[A1:A5].pselect@a(~>5000000) |
|
|
7 |
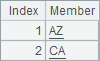
=A6.(eval("B"+string(A6.~))) |
|
此时,A7中的结果正是我们想要的:
字符串常数
这里的字符串常数,并不是指简单的用双引号括起来的字符串,或是一个字符串类型的常数,而是指用$[…]的模式表示的字符串。
从使用上来看,$[…]和"…"是相同的,都是在表达式中表示…所构成的字符串。如:
|
|
A |
|
1 |
="abc"+$[ABC] |
|
2 |
="\"[abc]\""+$["[ABC\]"] |
A1和A2中的计算结果如下:
![]()
![]()
可以看到,$[…]和"…"的使用基本类似,字符串中都可以用 \ 作为转义符来标记其中有歧义的字符,如普通字符串中的"和字符串常数中的 ]。
实际上,字符串常数$[…],经常用在宏或者eval函数中。在集算器的编辑界面中,$[…]的内容中出现的单元格名将会随着编辑操作变迁,也可以在复制粘贴等操作时调整表达式。这样,当需要用字符串常数来返回一个单元格的名称时,它的这种特性就可以保证在网格结构发生变化时不致造成表达式错误。如:
|
|
A |
B |
|
1 |
select * from STATES |
=demo.query(A1) |
|
2 |
POPULATION>10000000 |
=demo.query($[${A1} where ${A2}]) |
|
3 |
left(ABBR,1)='C' |
=demo.query($[${A1} where ${A2} and ${A3}]) |
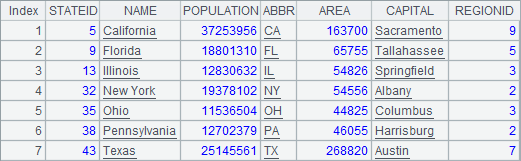
B2和B3中,在字符串常数中,嵌套使用了宏,用单元格值生成query函数的查询字符串。其中,B2中查询人口大于10,000,000的州:
B3中查询人口大于10,000,000且缩写的首字母为C的州:
![]()
此时,如果在第2行之前添加1个空行,则网格如下:
|
|
A |
B |
|
1 |
select * from STATES |
=demo.query(A1) |
|
2 |
|
|
|
3 |
POPULATION>10000000 |
=demo.query($[${A1} where ${A3]) |
|
4 |
left(ABBR,1)='C' |
=demo.query($[${A1} where ${A3} and ${A4}]) |
可以看到,B3和B4表达式中的单元格名做了自动更正。而由于"…"表示的字符串中无法使用宏,同时"…"中的内容也不会随着编辑操作而改变,所以在特定的情况下不适用。