
更新数据
本节讲解在数据库中更新数据的内容,非应用程序员如不需了解可以跳过,不影响正常阅读。
SQL除了可以用于在数据库中查询数据,还可以用于更新数据库中的数据。在集算器中,除了可以直接用SQL命令返回查询结果,也可以使用update函数,使用序表或序列中的数据来更新数据库。
执行 SQL 更新数据
在集算器中,可以用db.execute(sql)函数,在数据库中执行SQL,在数据库中执行各种更新操作,如:
|
|
A |
B |
|
1 |
|
/=demo.query("select * from TEST") |
|
2 |
>demo.execute("create table TEST(ID int,FULLNAME varchar(50), STATE varchar(20))") |
=demo.query("select * from TEST") |
|
3 |
>demo.execute("insert into TEST values (1,'Tom Smith','Florida')") |
|
|
4 |
>demo.execute("insert into TEST values (2,'Michael Jones','Montana')") |
=demo.query("select * from TEST") |
|
5 |
>demo.execute("update TEST set STATE='New York' where ID=1") |
=demo.query("select * from TEST") |
|
6 |
>demo.execute("delete from TEST where STATE='Montana'") |
=demo.query("select * from TEST") |
|
7 |
>demo.execute("drop table TEST") |
/=demo.query("select * from TEST") |
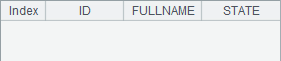
在这个网格中,用SQL命令,在数据库中新建了一个表TEST,并在其中执行插入记录、更新记录、删除记录等操作,最后删除表。在B列中,可以查看每一步操作后,TEST表中的数据。B2中可以看到表的结构如下,其中没有记录:
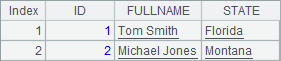
A3和A4用SQL各插入一条记录后,B4中可以看到结果:
A5修改了一条记录,B5中可以看到结果如下:
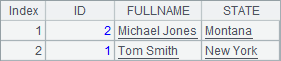
A5中修改了Tom Smith所在的州,可以看到,数据库中记录的顺序也有了变化。实际上,在各类数据库中存储时,记录往往是没有顺序的,数据的更新经常会打乱表中记录的顺序,这有时候会造成一定的麻烦。
A6中删除了Montana州的数据,结果如下:
![]()
最后,在A7中删除了TEST表。由于在最初的时候,以及删除TEST表之后,是无法用query函数读取到表中的数据的,因此B1与B7中如果执行查询会报错。
在用execute执行SQL命令时,也可以使用参数,如:
|
|
A |
B |
|
1 |
|
/=demo.query("select * from TEST") |
|
2 |
>demo.execute("create table TEST(ID int,FULLNAME varchar(50), STATE varchar(20))") |
=demo.query("select * from TEST") |
|
3 |
>demo.execute("insert into TEST values (?,?,?)",1,"Tom Smith","Florida") |
|
|
4 |
>demo.execute("insert into TEST values (?,'Michael Jones','Montana')",2) |
=demo.query("select * from TEST") |
|
5 |
>demo.execute("update TEST set STATE='New York' where ID=?",1) |
=demo.query("select * from TEST") |
|
6 |
>demo.execute("delete from TEST where STATE=?","Montana") |
=demo.query("select * from TEST") |
|
7 |
>demo.execute("drop table TEST") |
/=demo.query("select * from TEST") |
在execute中添加参数时,SQL语句中对应的位置用?代替,参数按照顺序依次写在语句后面。既可以全部使用参数,如A3中的代码,也可以部分使用参数,如A4中的代码。需要注意的是,集算器的函数中,字符串要用双引号"…"括起来,这和SQL中的语法不同。
在默认情况下,execute语句执行后将会自动提交到数据库,同时一旦出现错误,将中止执行代码。如:
|
|
A |
B |
C |
|
1 |
1 |
Tom Smith |
Florida |
|
2 |
2 |
Michael Jones |
Montana |
|
3 |
three |
William Bush |
New York |
|
4 |
4 |
Violet Taylor |
Montana |
|
5 |
>demo.execute("create table TEST(ID int, FULLNAME varchar(50), STATE varchar(20))") |
|
|
|
6 |
=create(Fd1,Fd2,Fd3).record([A1:C4]) |
|
|
|
7 |
for A6 |
=demo.execute("insert into TEST values (?,?,?)",A7.Fd1,A7.Fd2,A7.Fd3) |
|
|
8 |
|
=demo.query("select * from TEST") |
|
|
9 |
=demo.execute("drop table TEST") |
|
|
A6中的序表如下:
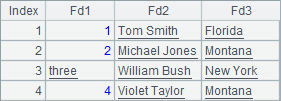
在A7的代码块中,循环上面的序表,把记录填入数据库中的TEST表,并在B8中查询插入后的结果。在执行到第3条记录时,由于three不是整数,无法填入数据库,出现错误,代码会中止执行。而从B8中可以看到,TEST表中数据如下:
也就是说,只有部分数据填写到了数据库中,同时A9中删除TEST表的代码也未执行,这往往并非我们期待的结果。
为此,需要自行控制错误代码,并用命令完成提交。为此,不能使用默认的数据库连接,而需要用connect@e()创建数据库连接,并在用execute@k函数执行SQL,不自动提交结果:
|
|
A |
B |
C |
|
1 |
1 |
Tom Smith |
Florida |
|
2 |
2 |
Michael Jones |
Montana |
|
3 |
three |
William Bush |
New York |
|
4 |
4 |
Violet Taylor |
Montana |
|
5 |
=connect@e("demo") |
>A5.execute("create table TEST(ID int, FULLNAME varchar(50), STATE varchar(20))") |
|
|
6 |
=create(Fd1,Fd2,Fd3).record([A1:C4]) |
|
|
|
7 |
for A6 |
>A5.execute@k("insert into TEST values (?,?,?)",A7.Fd1,A7.Fd2,A7.Fd3) |
|
|
8 |
if A5.error()==0 |
>A5.commit() |
|
|
9 |
else |
>A5.rollback() |
|
|
10 |
=A5.query("select * from TEST") |
>A5.execute("drop table TEST") |
>A5.close() |
在这个网格中,由于连接时connect函数使用了@e选项,因此在循环执行B7中的代码更新数据时,出现错误并不会中止执行,而是记录错误信息。最后,在A8中查询错误代码是否为0:
![]()
错误代码不为0,说明执行中存在错误,在B7执行execute时使用了@k选项,执行结果不会自动提交。因此,在执行B9中的rollback回滚后,A10中可以看到,出现错误之后,所有记录都未提交:
关于控制连接的问题,可以阅读控制连接来进一步了解。
用序表或序列更新数据
在上面的例子中,用for循环函数将序表中的数据更新到序表。在集算器中,可以直接将序列或序表中数据,用update函数更新到序表。如:
|
|
A |
B |
C |
|
1 |
1 |
Tom Smith |
Florida |
|
2 |
2 |
Michael Jones |
Montana |
|
3 |
3 |
William Bush |
New York |
|
4 |
4 |
Violet Taylor |
Montana |
|
5 |
=connect@e("demo") |
>A5.execute("create table TEST(ID int,FULLNAME varchar(50), STATE varchar(20))") |
|
|
6 |
=create(Fd1,Fd2,Fd3).record([A1:C4]) |
|
|
|
7 |
>A5.update(A6,TEST,ID:Fd1,FULLNAME:Fd2, STATE:Fd3;ID) |
|
|
|
8 |
=A5.query("select * from TEST") |
>A5.execute("drop table TEST") |
>A5.close() |
A6中序表如下:
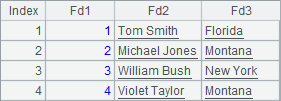
在A7中,用update函数,将序表A6中的数据更新到数据库中的TEST表,在update函数中,首先指定源数据为A6,更新到TEST,并指定各字段的对应关系,在最后指定了更新时使用的主键是ID,当主键未指定时,会自动到数据库中寻找主键。在A8中查询出的结果如下:
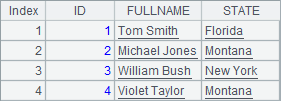
可以看到,update函数更新数据库,与前面例子中用for循环的结果是类似的。
在设定了更新时使用的主键后,如果数据库中已经存在了主键相同的数据,结果会如何呢?我们看看下面的例子:
|
|
A |
B |
C |
|
1 |
1 |
Tom Smith |
Florida |
|
2 |
2 |
Michael Jones |
Montana |
|
3 |
3 |
William Bush |
New York |
|
4 |
4 |
Violet Taylor |
Montana |
|
5 |
=connect@e("demo") |
>A5.execute("create table TEST(ID int,FULLNAME varchar(50), STATE varchar(20))") |
|
|
6 |
>demo.execute("insert into TEST values (1,'TOM SMITH','FL')") |
>demo.execute("insert into TEST values (20,'MICHAEL','MT')") |
=demo.query(" select * from TEST") |
|
7 |
=create(Fd1,Fd2,Fd3).record([A1:C4]) |
|
|
|
8 |
>A5.update(A7,TEST,ID:Fd1, FULLNAME:Fd2,STATE:Fd3;ID) |
|
|
|
9 |
=A5.query("select * from TEST") |
>A5.execute("drop table TEST") |
>A5.close() |
在A6和B6中在TEST中预先插入2条记录,从C6中读出在用update函数更新前,TEST中数据如下:
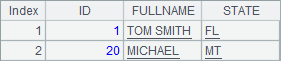
在A8中执行update函数后,在A9中查到TEST中数据如下:
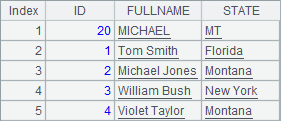
可以发现,主键相同的数据被更新了,而主键不同的MICHAEL的数据仍然存在。
使用update函数时,还可以用一些选项来进行不同的操作:@u表示只更新数据,而不插入新记录;@i表示只插入数据,而不更新已有的数值;@a表示在更新前清空目标表中的所有记录;@1表示第一个字段为自增字段,更新时不对它赋值。
如将上例中A8中的语句修改为=A5.update@u(A7,TEST,ID:Fd1,FULLNAME:Fd2,STATE:Fd3;ID),A9中查到的结果如下:
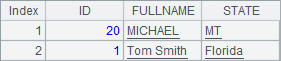
A8执行update@u时,只修改已存在的记录。
若将上例中A8中的语句修改为=A5.update@a(A7,TEST,ID:Fd1,FULLNAME:Fd2,STATE:Fd3;ID),A9中查到的结果如下:
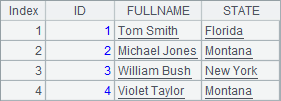
A8执行update@a前,将删除表中原有的记录。使用update@a(),可以保证表中的数据与更新时使用过的源数据保持一致。
与直接执行SQL类似,用update函数时,也可以使用@k选项,此时需要考虑对数据库连接的控制,相关内容可以阅读控制连接。