
被 JAVA 调用
本节内容,非应用程序员可以跳过,不影响正常阅读。
可以将集算器嵌入到Java应用程序中。使用时类似于用JDBC访问数据库的方式调用集算器网格程序。在过程中,网格程序被包装成存储过程,因此调用方法与调用存储过程相同。
基本使用
集算器JDBC类似一个不带物理表的数据库JDBC驱动,可以把它简单的看成是一个只有存储过程的数据库。另外,集算器JDBC是个完全嵌入式计算引擎,已经在JDBC中完成了所有运算,不象数据库那样JDBC只是个接口,实际运算在独立的数据库服务器完成。
可参考JDBC部署 先完成程序的部署。
集算器JDBC使用的网格文件
与用call函数跨网格调用时类似,在集算器JDBC中使用的网格代码中,结果集需要通过return语句返回。如下面的网格文件createTable1.splx:
|
|
A |
B |
|
1 |
=create(ID,Amount) |
|
|
2 |
for 100 |
>A1.insert(0,#A2,rand(100*100)) |
|
3 |
return A1 |
|
这个网格中的计算比较简单:生成一个100条记录的序表,包含顺序设定的ID字段与随机生成的Amount字段。在A3中,用return语句将A1中的序表返回。
下面我们将使用这个网格文件,熟悉在JAVA中调用集算器JDBC的方法。
在调用集算器执行网格文件前,首先需要按下面步骤配置相关的信息:
1. 加载需要用到的jar包。在启动JAVA应用程序时需要的jar包(JDBC部署 中有jar包说明),如果在web应用下,可以把这些jar包放在WEB-INF/lib目录下
2. 部署raqsoftConfig.xml
在raqsoftConfig.xml中包含了集算器的基本配置信息,如寻址路径、主目录、数据源配置等,以及集算器的并发数等信息,日志文件信息以及连接池信息,它可以在集算器的[安装目录]\esProc\config路径下找到,其中存储的信息与集算器的选项页面中设定相同。在部署时可以先调整其中的配置。
注意:配置文件需复制后放置在应用项目的类路径下,但名称必须为raqsoftConfig.xml,不能改变。关于配置文件的具体解释,可以参考JDBC部署。
3. 部署脚本文件
将上面的createTable1.splx放到应用项目的类路径下,也可以放到raqsoftConfig.xml文件的<splPathList/>节点指定的寻址路径,或者<mainPath/>指定的主路径中。
4. 在JAVA中调用脚本文件
public void testDataServer(){
Connection con = null;
java.sql.CallableStatement st;
try{
//建立连接
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
//调用存储过程,其中createTable1是脚本文件的文件名
st =con.prepareCall("call createTable1()");
//执行存储过程
st.execute();
//获取结果集
ResultSet rs = st.getResultSet();
//简单处理结果集,将结果集中的字段名与数据输出
ResultSetMetaData rsmd = rs.getMetaData();
int colCount = rsmd.getColumnCount();
for ( int c = 1; c <= colCount;c++) {
String title = rsmd.getColumnName(c);
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
System.out.print(title);
}
while (rs.next()) {
for (int c = 1; c<= colCount; c++) {
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
Object o = rs.getObject(c);
System.out.print(o.toString());
}
}
}
catch(Exception e){
System.out.println(e);
}
finally{
//关闭连接
if (con!=null) {
try {
con.close();
}
catch(Exception e) {
System.out.println(e);
}
}
}
}
在调用集算器文件时,用"call createTable1()"语句,即可运行网格文件createTable1.splx并将结果返回为ResultSet对象。在后续的程序中,简单将结果集中的数据输出。程序运行后,输出结果如下:
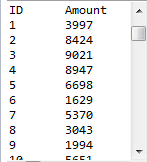
调用不同的网格文件
在用JAVA调用的基本方法中,我们了解了如何在JAVA程序中调用一个网格文件。在这里我们详细了解一下如何调用不同的网格文件。先来看下面的网格文件createTable2.splx:
|
|
A |
B |
|
1 |
=connect("demo") |
|
|
2 |
=A1.query("select * from EMPLOYEE") |
=A2.select(month(BIRTHDAY)==month(Date) &&day(BIRTHDAY)==day(Date)) |
|
3 |
>A1.close() |
|
|
4 |
if B2.len()>1 |
return B2.new(EID,NAME+ " "+ SURNAME:NAME, GENDER, BIRTHDAY) |
|
5 |
else |
return "None" |
在这个网格文件中,需要从数据源demo中获取数据,同时使用了日期类型的参数Date:
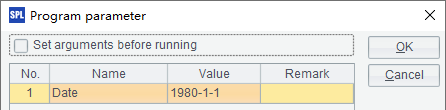
在网格中使用的demo数据源,需要在raqsoftConfig.xml文件中配置,具体方法可以参考JDBC部署。在网格中创建的数据源连接,在使用后应该用db.close() 函数关闭。
在JAVA中调用时,建立连接、输出结果等部分的代码是完全相同的,调用文件部分如下:
//调用存储过程,其中createTable2是脚本文件的文件名,?代表使用的参数
st =con.prepareCall("call createTable2(?)");
//设置参数
java.util.Calendar calendar = java.util.Calendar.getInstance();
calendar.set(1980, 0, 4);
st.setObject(1, calendar.getTime());
//执行存储过程
st.execute();
//获取结果集
ResultSet rs = st.getResultSet();
这个网格文件包含一个参数,因此调用时使用"call createTable2(?)",其中的 ? 代表需要输入的参数。在这种情况下需要用st.setObject() 方法输入参数。输入参数时,通常是按照次序设入参数,使用这种方式时,输入参数的值与网格中参数的名称无关。除此以外,也可以指定参数名称设入值,如将上面例子中的语句改为st.setObject("Date", calendar.getTime())。网格文件将根据输入的日期列出生日与之在同一天的员工,需要注意的是在Calendar类中设置日期时,月份是从0开始的。结果集输出如下:

在输入参数时,除了直接按照类型输入参数对象,日期类型的参数也可以输入字符串,由集算器自动解析:
//设置参数
st.setObject(1, "1980-1-4");
注意输入字符串需要符合raqsoftConfig.xml文件中设置的日期格式。程序运行的结果和上面是相同的。
除了上面的调用方法,还可以把参数写定在语句中,如:
//调用存储过程,其中createTable2是脚本文件的文件名,在语句中写定参数
st =con.prepareCall("call createTable2(\"1980-1-8\")");
//执行存储过程
st.execute();
//获取结果集
ResultSet rs = st.getResultSet();
使用这样的调用方法时,不能根据参数类型输入对象,而只能使用数值型参数,或使用字符串型参数交由集算器解析。计算后,结果如下:
![]()
由于没有找到1月8日出生的员工,因此在网格的B5格中用return语句返回了字符串None。从上面的结果中我们可以发现,即使从网格返回的数据是单值,也会自动生成结果集中的列名,作为标准ResultSet返回。
无结果集和多个结果集
在调用网格文件时,还允许无返回数据。如下面的网格文件outputData1.splx:
|
|
A |
|
1 |
$(demo) select * from CITIES |
|
2 |
=A1.select(Arg.pos(left(NAME,1))>0) |
|
3 |
=file("cities.txt") |
|
4 |
>A3.export@t(A2) |
文件中使用了字符串序列类型的参数Arg:
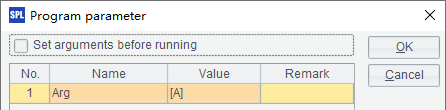
在A1中,直接调用了demo数据库执行查询,而没有用connect语句创建连接。这种时候,需要raqsoftConfig.xml文件中数据库配置中,demo数据源的autoConnect属性为true:
<property name="autoConnect" value="true"/>
具体配置可以参考JDBC部署。在JAVA中调用网格部分的代码如下:
//调用存储过程,其中outputData1是脚本文件的文件名
st =con.prepareCall("call outputData1(?)");
//设置参数
com.scudata.dm.Sequence seq = new com.scudata.dm.Sequence();
seq.add("A");
seq.add("B");
seq.add("C");
st.setObject(1, seq);
//执行存储过程
boolean hasResult = st.execute();
//此时没有结果集,无法获取,hasResult为false
值得注意的是,在网格中使用了序列类型的参数,对于这样的类型,只能生成Sequence对象设入。设入序列参数[A,B,C]后,将首字母为A,B,C的城市信息输出到文件cities.txt。当网格中使用的文件未指定路径时,将存入主路径中,由raqsoftConfig.xml文件的<mainPath/>节点所指定。文件中数据如下:
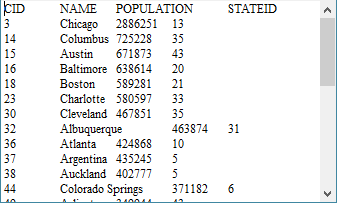
一个网格文件也可能返回多个结果集,如下面的网格文件createTable3.splx:
|
|
A |
B |
|
1 |
$(demo) select EID, NAME+' '+SURNAME FULLNAME, GENDER, STATE, BIRTHDAY from EMPLOYEE |
|
|
2 |
=A1.select(STATE == sState && age(BIRTHDAY)<sAge) |
|
|
3 |
=A2.select(GENDER=="F") |
=A2\A3 |
|
4 |
return A3 |
return B3 |
这个网格将年龄小于设定的sAge,以及在指定州sState的员工,分性别返回为两个序表。网格中使用了两个参数,指定员工的最高年龄与所在州:
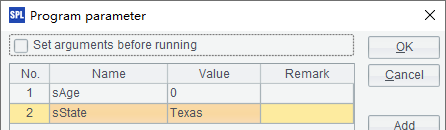
此时,网格文件在执行后,将返回多个结果集
//调用存储过程,其中createTable3是脚本文件的文件名,?代表使用的参数
st =con.prepareCall("call createTable3(?,?)");
//依次设置参数
st.setObject(1, 30);
st.setObject(2, "California");
//执行存储过程
boolean hasResult = st.execute();
//获取多个结果集并输出结果
while (hasResult) {
ResultSet rs = st.getResultSet();
//输出结果
ResultSetMetaData rsmd = rs.getMetaData();
int colCount = rsmd.getColumnCount();
for ( int c = 1; c <= colCount;c++) {
String title = rsmd.getColumnName(c);
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
System.out.print(title);
}
while (rs.next()) {
for (int c = 1; c<= colCount; c++) {
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
Object o = rs.getObject(c);
System.out.print(o.toString());
}
}
System.out.println();
//查看是否返回了其它结果集
hasResult = st.getMoreResults();
}
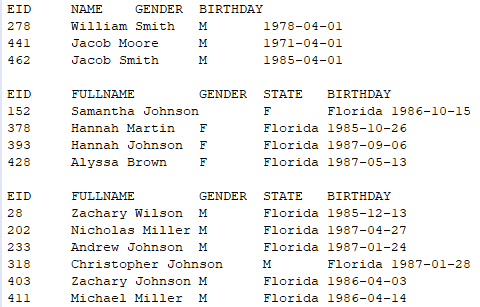
执行后,分别读出California州且30岁以下的女员工与男员工,输出结果如下:
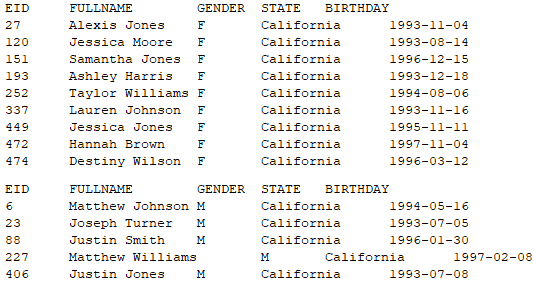
网格文件createTable3.splx中,两个排列也可以用一条语句返回:return A3,B3,在JAVA中调用的情况和上面是相同的。
直接执行语句
在JAVA程序中使用集算器时,除了调用一个网格文件,还可以直接执行语句。实际上,调用网格文件,也可以作为call语句直接执行。在这里我们详细了解一下如何直接执行其它语句。如:
//直接执行语句,返回结果集
st = con.createStatement();
ResultSet rs1 = st.executeQuery("=age(date(\"1/1/1990\"))");
ResultSet rs2 = st.executeQuery("=5.(~*~)");
这里用executeQuery方法直接执行以=开头的集算器表达式,并将表达式的计算结果返回为结果集,注意表达式中的双引号需要在前面添加转义符。如果仍然用前面类似的代码将结果集输出,结果如下:
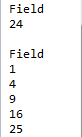
可以注意到如果返回的结果为序列,那么在JDBC中会返回1列多行的结果集。也可以用另外的方法调用:
//先判断是否有结果集,再获取结果
boolean hasResult1 = st.execute("=age(date(\"1/1/1990\"))");
ResultSet rs1,rs2;
if (hasResult1) {
rs1 = st.getResultSet();
}
boolean hasResult2 = st.execute("=5.(~*~)");
if (hasResult2) {
rs2 = st.getResultSet();
}
使用execute方法时,会根据执行的语句返回是否有结果集,代码的效果和前面是相同的。
如果需要在语句中使用参数,可以使用(x1, x2,…)操作符,依次计算表达式,并返回最后一个的结果,如:
st =con.createStatement();
ResultSet rs1 = st.executeQuery("=(pi=3.14,r=4,r*r*pi)");
计算圆的面积,输出结果集如下:
![]()
在执行语句时,语句中可以使用参数,按照PreparedStatement中的设定顺序,在语句中用固定的名称?1,?2,…等调用。如:
PreparedStatement pst = con.prepareStatement("=?1*?1*?2");
pst.setObject(1,3);
pst.setObject(2,3.14);
ResultSet rs = pst.executeQuery();
计算半径为3的圆面积,输出结果集如下:
![]()
在集算器JDBC中还可以使用$开头的数据集查询语句。如:
//执行数据库查询语句
st = con.createStatement();
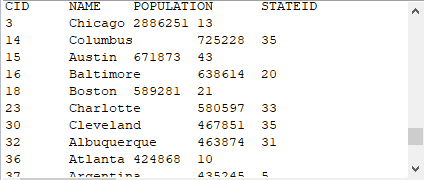
ResultSet rs1 = st.executeQuery("$(demo) select * from CITIES where POPULATION > 2000000");
注意此时使用的数据集demo,需要在配置中设为自动连接。结果如下:
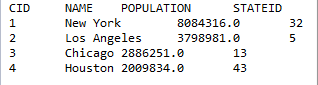
在JDBC中,还可以执行一片多行多列的网格代码。执行时,需要将代码拼为一个字符串,行之间用\n分隔,同一行的各列之间用\t分隔。需要注意的是,执行多行多列的网格代码时,代码拼成的字符串前需要==开头而非=,例如:
ResultSet rs = st.executeQuery("==demo.cursor(\"select * from EMPLOYEE order by SALARY desc\")\t=[]\nfor A1;SALARY\n\t>B1.insert(0,A2)\nreturn B1");
执行这个字符串时,相当于计算下面的网格:
|
|
A |
B |
|
1 |
=demo.cursor("select * from EMPLOYEE order by SALARY desc") |
=[] |
|
2 |
for A1;SALARY |
|
|
3 |
|
>B1.insert(0,A2) |
|
4 |
return B1 |
|
如果将得到的ResultSet输出,则结果如下:

在JAVA程序中直接执行语句时,还可以使用简单SQL,查询主目录中的数据文件,如:
st =con.createStatement();
ResultSet rs = st.executeQuery ("$select * from cities.txt");
在集算器JDBC中使用简单SQL时,和使用数据集查询语句有些类似,语句同样用$符号开头,但不需要指定数据源名称。如果将得到的ResultSet输出,则结果如下:
类似的,在Java代码中调用集算器的普通方式也可以执行简单SQL,有关简单SQL的说明请阅读简单SQL。
JDBC 中使用全局变量
在本章前面的内容中,介绍了如何用JAVA调用集算器JDBC。在例子中可以了解到,如果需要使用参数,需要在代码中使用st.setObject(),除了这样的方式,可以在JDBC的url中,直接用jobVars设置全局变量。
如:
public void testJobVars(){
Connection con = null;
java.sql.CallableStatement st;
try{
//建立连接
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://?jobVars=Date:1990-4-1,sAge:40, sState:Florida");
//调用存储过程,其中createTable1是脚本文件的文件名
st = con.prepareCall("call createTable2(date)");
//执行存储过程
st.execute();
//获取结果集
ResultSet rs = st.getResultSet();
output(rs);
st = con.prepareCall("call createTable3(age,state)");
boolean hasResult = st.execute();
// 获取多个结果集并输出结果
while (hasResult) {
rs = st.getResultSet();
output(rs);
hasResult = st.getMoreResults();
}
}
catch(Exception e){
System.out.println(e);
}
finally{
//关闭连接
if (con!=null) {
try {
con.close();
}
catch(Exception e) {
System.out.println(e);
}
}
}
}
private void output(ResultSet rs) throws SQLException{
//简单处理结果集,将结果集中的字段名与数据输出
ResultSetMetaData rsmd = rs.getMetaData();
int colCount = rsmd.getColumnCount();
for ( int c = 1; c <= colCount;c++) {
String title = rsmd.getColumnName(c);
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
System.out.print(title);
}
while (rs.next()) {
for (int c = 1; c<= colCount; c++) {
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
Object o = rs.getObject(c);
System.out.print(o.toString());
}
}
}
在代码中,url中用jobVars设置全局变量,变量会根据设入的值自动解析类型,多个变量之间用逗号分隔。全局变量设置后,SPL脚本文件在执行时,会使用jobVars设入的全局变量。但是需要注意是,对应的网格文件中,原有的参数设置需要删除。上面的代码执行后,输出结果如下:
如果修改url中的jobVars设置,执行结果也会随之改变。