订购了所有产品的客户
l 问题
下面是一个企业订单情况的数据库内的一些表格,首先是Customers表,记录了客户ID和客户的账户余额:

Orders表记录了每个订单以及它的客户:

OrderDetails表记录了每个订单的详细信息,包括订购的产品ID以及数量:
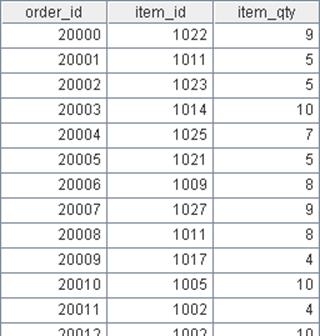
Products表记录了企业所有的产品信息:

现在问题是为每一个订购了公司所有产品的顾客求出平均acct_balance(账户余额),并为每一个没有订购所有产品的顾客求出平均账户余额。
l 思路
大致思路:首先要利用集算器指针引用的特性,将各个表的关联实质化起来,即将item_id、order_id、customer_id等字段都替换成对应的记录,这样最后得到的Orders表就关联了其它所有的表,从Order表的任一记录出发都可以直接提取其它表内其相应的记录。而后将Orders表按顾客分组,并同时算出每人购买的不重复产品数量,比较这个数量和Products表中的总产品数量,选出相等的客户,即为购买了所有产品的客户了,而全部客户的集合和它们的差集也就是未购买所有产品的顾客了,分别求出他们的平均账户余额即可。
1. 定义好OrderDetails、Customers、Products表中的主键,即*_id字段。
2. 用switch函数,将Orders表中的order_id字段值都替换成OrderDetails表中相应的记录,customer_id字段值替换成Customers表中相应的记录,OrderDetails表中item_id字段值替换成Products表中相应的记录。
3. 将Orders表按客户分组,并算出每个客户购买的不重复产品数量,创建新序表。
4. 选出产品数量等于Products表中记录总数的客户。
5. 求出这些客户的平均账户余额。
6. 求出剩下那些客户的平均账户余额。
l 代码
|
|
A |
|
|
1 |
=file("C:\\txt\\Orders.txt").import@t() |
Orders表 |
|
2 |
=file("C:\\txt\\OrderDetails.txt").import@t() |
OrderDetails表 |
|
3 |
=file("C:\\txt\\Customers.txt").import@t() |
Customers表 |
|
4 |
=file("C:\\txt\\Products2.txt").import@t() |
Products表 |
|
5 |
>A3.keys(customer_id), A2.keys(order_id), A4.keys(item_id) |
定义各表的主键 |
|
6 |
>A1.switch(order_id,A2; customer_id,A3), A2.switch(item_id,A4) |
将Orders和OrderDetails表中的id字段都替换为记录 |
|
7 |
=A1.group(customer_id:customer;~:orders,~.id(order_id.item_id).len():items_cnt) |
将Orders表按顾客分组,同时算出每人购买的不重复产品数量 |
|
8 |
=A7.select(items_cnt==A4.len()) |
产品数量等于总产品数量的记录 |
|
9 |
=A8.avg(customer.acct_balance) |
这些客户的平均账户余额 |
|
10 |
=(A7\A8).avg(customer.acct_balance) |
其他客户的平均账户余额 |
l 结果
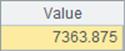
订购了所有产品的客户的平均账户余额:
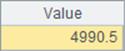
没有订购所有产品的客户的平均账户余额: