T.update(P:D)
描述:
更新实表的记录。
语法:
T.update(P:D)
备注:
根据排列P与D更新实表T的记录,保证P的结构和实表T结构一致;
P的键值在实表T中存在则更新该条记录,P的键值在T中不存在,则将此记录插入到T中。
D的键值在T中存在则删除该条记录,参数D可以省略。
参数P和D都存在时,先计算P再计算D。
实表T没有维时忽略D,此时P中数据全部追加到T的末尾。
参数:
|
T |
组表的实表。 |
|
P |
要更新的内容,和T同构的排列/序表,可省略。 |
|
D |
根据D的键值删除T的记录,可省略。 |
选项:
|
@i |
只处理插入,键值能找到的忽略。 |
|
@u |
只处理更新,键值找不到的忽略。 |
|
@n |
返回更新/插入/删除的记录。 |
|
@w |
P是游标与原表同序,重写P涉及的字段,该选项仅支持T列存格式时使用,不可增加记录。 |
|
@y |
保持在内存,在计算时归并,不写入外存。 |
返回值:
实表
示例:
更新实表数据:
|
|
A |
|
|
1 |
=file("emp.ctx") |
生成组表文件。 |
|
2 |
=A1.create@y(#EID,NAME) |
创建组表的基表。 |
|
3 |
=connect("demo").cursor("select EID,NAME from employee where EID<20") |
返回游标。 |
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到组表的基表中。 |
|
5 |
=A2.attach(table3,SURNAME) |
在基表上增加名为table3的附表,EID为键,SURNAME为字段。 |
|
6 |
=connect("demo").cursor("select EID,SURNAME from employee where EID< 5") |
返回游标。 |
|
7 |
=A5.append@i(A6) |
将A6游标中的数据追加到附表table3中。 |
|
8 |
=A2.cursor().fetch() |
查看基表中的数据。
|
|
9 |
=A5.cursor().fetch() |
查看附表中的数据:
|
|
10 |
=create(EID,NAME).record([1,"A",21,"B"]) |
返回序表。 |
|
11 |
=A2.update(A10) |
根据A8序表更新基表中的数据,A10序表键值在基表中存在时更新记录,键值不存在时追加记录。 |
|
12 |
=A2.cursor().fetch() |
此时查看基表中的数据:
|
|
13 |
=create(EID,SURNAME).record([2,"aa",10,"bb"]) |
返回序表。 |
|
14 |
=A5.update@in(A13) |
使用@i选项,只处理插入,相同键值的忽略,组合使用@n选项,返回插入的记录:
|
|
15 |
=A5.cursor().fetch() |
此时查看附表中的数据:
|
|
16 |
=create(EID,SURNAME).record([1,"ss",6,"cc"]) |
返回序表。 |
|
17 |
=A5.update@un(A16) |
使用@u选项,只处理更新,键值不同的忽略,组合使用@n选项,返回更新的记录:
|
|
18 |
=A5.cursor().fetch() |
此时查看附表中的数据:
|




删除实表数据:
|
|
A |
|
|
1 |
=file("empD.ctx") |
|
|
2 |
=A1.create@y(#EID,NAME) |
创建EID为键的组表。 |
|
3 |
=connect("demo").cursor("select top 10 EID,NAME from employee") |
返回游标,其中数据内容如下:
|
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到实表A2中。 |
|
5 |
=create(EID,NAME).record([10,"bb",11,"cc"]) |
生成序表:
|
|
6 |
=create(EID,NAME).record([1,"Rebecca"]) |
生成序表:
|
|
7 |
=A2.update@n(A5:A6) |
更新实表A2,A5的键值在实表A2中存在时更新否则插入,A6的键值在A2中存在时删除,使用@n选项,返回更新和插入及删除的记录:
|
|
8 |
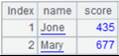
=A2.import() |
此时读取实表A2的数据如下:
|



P、D中存在同键值记录时:
|
|
A |
|
|
1 |
=file("empPD.ctx") |
|
|
2 |
=A1.create@y(#EID,NAME) |
创建EID为键的组表。 |
|
3 |
=connect("demo").cursor("select top 10 EID,NAME from employee") |
返回游标,其中数据内容如下:
|
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到实表A2中。 |
|
5 |
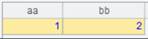
=create(EID,NAME).record([1,"bb",2,"cc"]) |
生成序表:
|
|
6 |
=create(EID,NAME).record([1,]) |
生成序表:
|
|
7 |
=A2.update@n(A5:A6) |
更新实表A2,A5的键值在实表A2中存在则更新,A6的键值在A2中存在时删除,使用@n选项,返回更新和插入及删除的记录:
|
|
8 |
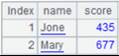
=A2.import() |
由于P、D参数同时存在时先执行P再执行D,所以键值为1的记录最终会被删除掉,读取实表A2的数据如下:
|


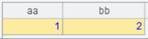
实表没有维的情况:
|
|
A |
|
|
1 |
=file("empD.ctx") |
|
|
2 |
=A1.create@y(EID,NAME) |
创建组表。 |
|
3 |
=connect("demo").cursor("select top 10 EID,NAME from employee") |
返回游标,其中数据内容如下:
|
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到实表A2中。 |
|
5 |
=create(EID,NAME).record([10,"bb"]) |
生成序表:
|
|
6 |
=create(EID,NAME).record([1,"Rebecca"]) |
生成序表:
|
|
7 |
=A2.update(A5:A6) |
实表A2无维,所以更新时忽略参数D,并且将P中的所有记录追加进实表,所以此处将A5的记录全部追加进实表,忽略此处的参数A6。 |
|
8 |
=A2.import() |
此时读取实表A2的数据如下:
|
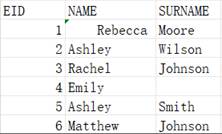

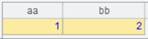
使用@y选项:
|
|
A |
|
|
1 |
=file("empD.ctx") |
|
|
2 |
=A1.create@y(#EID,NAME) |
创建组表。 |
|
3 |
=connect("demo").cursor("select top 10 EID,NAME from employee") |
返回游标,其中数据内容如下:
|
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到实表A2中。 |
|
5 |
=create(EID,NAME).record([1,"Rebecca"]) |
生成序表:
|
|
6 |
=A2.update@y(:A5) |
更新实表A2,A5的键值在A2中存在时删除,使用@y选项,更新保存在内存中,计算时才归并。 |
|
7 |
=A2.import() |
此时查看实表内容:
|
|
8 |
=A2.close() |
关闭实表。 |
|
9 |
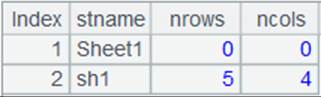
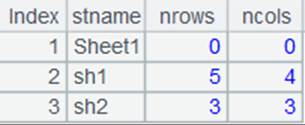
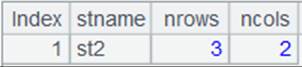
=A1.open().import@x() |
重新打开实表,读取实表中的数据,可以看到A6中的更新内容已经被还原:
|

使用@w选项:
|
|
A |
|
|
1 |
=demo.cursor("select STOCKID,DATE,CLOSING from STOCKRECORDS where STOCKID = ? and DATE<?","000062","2015-01-20") |
|
|
2 |
=file("STOCKRECORDS.ctx") |
创建组表文件。 |
|
3 |
=A2.create@y(#STOCKID,DATE,CLOSING) |
创建组表的基表。 |
|
4 |
=A3.append@i(A1) |
将A1游标中的数据追加到组表基表中。 |
|
5 |
=A2.open().cursor@x().fetch() |
读取组表数据内容:
|
|
6 |
=demo.cursor("select STOCKID,DATE from STOCKRECORDS where STOCKID = ?","000792") |
|
|
7 |
=A2.open() |
|
|
8 |
=A7.update@w(A6) |
将游标A6的内容更新到组表STOCKRECORDS.ctx中,使用@w选项,重写A6涉及的字段,即:将A6中的STOCKID,DATE字段更新到组表A7中,A7中的CLOSING字段内容保持不变,并且更新时不增加新的记录 ,保持组表A7原有的记录条数。 |
|
9 |
=A7.cursor@x().fetch() |
读取更新后的组表文件数据内容:
|