T.memory(C,…;w)
描述:
用实表生成内表。
语法:
T.memory(C,…;w)
将实表T中的数据根据过滤条件w过滤之后,读入内存中生成列为C的内表,内表可像序表一样使用。当省略C列不省略过滤条件w时,w前面的分号不可省略。实表中如果C列带#,则生成内表后C列作为T的键。C在T中不存在则填null。内表未设置键时可继承实表的键。
参数:
|
C |
列名,可省略,缺省读入全部列。 |
|
w |
过滤条件,缺省不过滤。 |
|
T |
组表的实表。 |
选项:
|
@p |
用第一字段作分段,要求T对第一个字段有序;当T有分段且参数C中包含T的第一个字段时,内表将继承组表T的分段属性。 |
|
@v |
使用该选项时,表T必须为纯序表,结果返回列式内表。 |
|
@x |
生成内表 自动关闭T。 |
|
@w |
用于复组表。 按更新机制归并,分表间存在相同键值时,忽略分表号较小的分表中的记录。分段要以第1分表为准,后面有些分表可能非常小可先全读。 |
返回值:
示例:
|
|
A |
|
|
1 |
=file("D:\\ employees.ctx") |
employees为已存在的组表文件。 |
|
2 |
=A1.open() |
打开组表。 |
|
3 |
=A2.attach(t1) |
返回组表上已存在的附表t1。 |
|
4 |
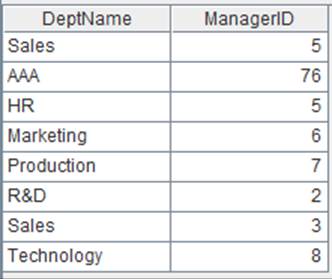
=A2.memory() |
用基表全部列生成内表:
|
|
5 |
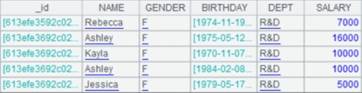
=A2.memory(EID,Dept,Name;EID<5) |
取基表的部分列并筛选出EID<5的数据生成内表:
|
|
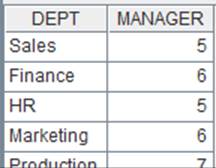
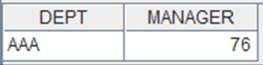
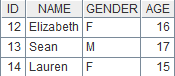
6 |
=A3.memory() |
取附表全部列生成内表:
|
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee").sortx(EID ) |
返回游标,游标中数据对EID有序。 |
|
2 |
=file("emp.ctx") |
生成组表文件。 |
|
3 |
=A2.create@yp(#EID,NAME,GENDER,SALARY) |
创建组表的基表,并且将第一个字段作为分段键。 |
|
4 |
=A3.append@i(A1) |
将游标中的数据追加到基表中。 |
|
5 |
=A2.open() |
打开组表文件。 |
|
6 |
=A5.memory@p(EID,NAME) |
用实表A5生成内表,使用@p选项,将第一个字段作为分段键,组表T有分段且A6的读取的字段中包含第一个字段EID,所以内表会继承组表A5的分段属性。 |
生成列式内表:
|
|
A |
|
|
1 |
=to(1000).new(~:ID,~*~:pNum).cursor() |
返回游标,游标中的数据为纯序表,表结构如下:
|
|
2 |
=file("tb1.ctx") |
生成组表文件。 |
|
3 |
=A2.create@y(#ID,pNum) |
创建组表的基表。 |
|
4 |
=A3.append@i(A1) |
将游标中的数据追加到基表中。 |
|
5 |
=A4.memory@v() |
使用@v选项,结果返回列式内表。 |
用复组表生成内表: