T.group(x:F,…;y:G,…)
描述:
备注:
对虚表T定义计算,T根据x分组后计算聚合表达式y,x为字段F的值,y为字段G的值,x只和相邻的记录对比, 结果返回以F,... G,…为字段的新虚表
该函数仅适用于企业版。
参数:
|
T |
虚表。 |
|
x |
分组表达式。 |
|
F |
字段名。 |
|
G |
汇总字段名。 |
|
y |
聚合表达式。 |
选项:
|
@s |
用累积方式聚合。 |
|
@q(x:F,…;x’:F’,…;…) |
T已对x,…有序,仅后面的字段需要排序时可用该选项,可以内存排序。 |
|
@sq(x:F,…;x’:F’,…;…) |
没有y:G参数时仅排序,不分组;有y:G参数时按累计方式聚合。该用法中@s必须与@q配合使用。 |
|
@e |
返回y的结果组成的虚表。其中x为T的字段名,y是T的函数,y的计算结果要求是T的一条记录,当y是聚合函数时仅支持maxp/minp/top@1。 |
返回值:
虚表
示例:
|
|
A |
|
|
1 |
=create(file).record(["scores-g.ctx"]) |
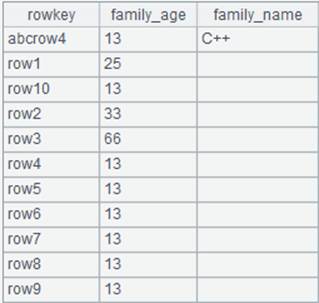
scores-g.ctx 为对STUDENTID有序的组表文件,内容如下:
|
|
2 |
=pseudo(A1) |
由A1组表生成虚表。 |
|
3 |
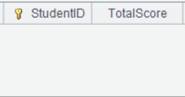
=A2.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
虚表A2定义计算,将虚表根据STUDENTID字段分组,并计算每组的SCORE的总值,结果返回新虚表。 |
|
4 |
=A3.import() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|
|
|
A |
|
|
1 |
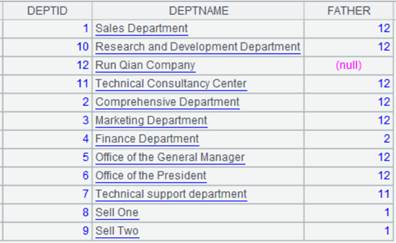
=create(file).record(["emp-g.ctx"]) |
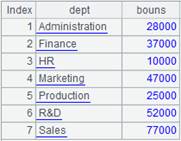
emp-g.ctx为对DEPT有序的组表文件,内容如下:
|
|
2 |
=pseudo(A1) |
由A1组表产生虚表。 |
|
3 |
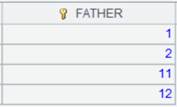
=A2.group@q(DEPT;GENDER) |
虚表A2定义计算,虚表已经对DEPT有序,所以分组时仅对GENDER排序,返回新虚表。 |
|
4 |
=A3.cursor().fetch() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|
|
5 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER) |
虚表A2定义计算,没有y:G参数时仅排序,不分组,返回新虚表。 |
|
6 |
=A5.import() |
读取A5虚表中的数据,此时A2虚表执行A5中定义的计算操作,返回内容如下:
|
|
7 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER;count(GENDER):count) |
虚表A2定义计算,有y:G参数,按累计方式聚合,返回新虚表。 |
|
8 |
=A7.import() |
读取A7虚表中的数据,此时A2虚表执行A7中定义的计算操作,返回内容如下:
|

使用@e选项,返回y的结果组成的虚表:
|
|
A |
|
|
1 |
=create(file).record(["emp-g.ctx"]) |
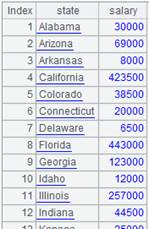
组表emp-g.ctx中的内容如下:
|
|
2 |
=pseudo(A1) |
由A1组表产生虚表。 |
|
3 |
=A2.group@e(DEPT;~.minp(SALARY)) |
虚表A2定义计算,使用@e选项,返回由minp(SALARY)结果记录构成的新虚表。 |
|
4 |
=A3.cursor().fetch() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|