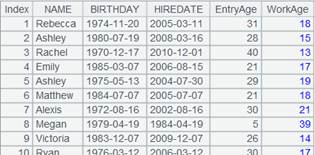
T.cursor(x:C,…;wi,...;mcs)
描述:
根据多路游标同步分段实表/内表/复组表,返回多路游标。
语法:
T.cursor(x:C,…;wi,...;mcs)
备注:
根据多路游标mcs同步分段实表/内表/复组表T,返回多路游标;用T和mcs的首字段对应同步。T为复组表时,将分表按照维度归并。
参数:
|
T |
实表/内表/复组表。T不支持为行存组表。 |
|
x |
表达式。 |
|
C |
列别名。 |
|
wi |
过滤条件,缺省读取全集,多个条件之间用逗号隔开,为AND关系。除常规的过滤表达式外,过滤条件中还支持如下几种写法,其中K表示实表T中的字段: 1.K=w w通常使用表达式Ti.find(K)或Ti.pfind(K),Ti为序表,w为null或false时将被过滤掉;当w为表达式Ti.find(K)且被选出字段C,...中包含K时,K将被赋值为Ti的指引字段; 当w为表达式Ti.pfind(K)且被选出字段C,...中包含K时,K将被赋值为K在Ti 中的序号。 2.(K1=w1,…Ki=wi,w) Ki=wi为赋值表达式,参数wi通常可以使用表达式Ti.find(Ki)或Ti.pfind(K),Ti为序表;当wi为表达式Ti.find(Ki)且被选出字段C,...中包含Ki时,Ki将被赋值为Ti的指引字段; 当wi为表达式Ti.pfind(Ki)且被选出字段C,...中包含Ki时,Ki将被赋值为Ki在Ti 中的序号。 w为过滤表达式, w中可引用Ki。 3.K:Ti Ti为序表,用实表中Ki的值与Ti的键值作对比,匹配不上的将被过滤掉;当选出字段C,...中包含K时,K将被赋值为Ti的指引字段。 4.K:Ti:null 符合K:Ti的记录将被过滤掉。 5.K:Ti:# 用序号定位,根据实表中K的值去对比序表Ti的记录序号,对应不上的记录将被过滤掉;当选出字段C,...中包含K时,K将被赋值为Ti的指引字段。 |
|
mcs |
由实表生成的多路游标。 |
选项:
|
@k |
用mcs的首键对应。 |
|
@v |
生成纯序表列式游标,相较普通游标性能有所提升。仅企业版适用。 |
|
@x |
游标取完则自动关闭T。 |
|
@g |
T为复组表时,如果后续对游标执行group计算,使用@g选项可提升计算速度。 |
|
@w |
用于带有更新标识的复组表。 按更新机制归并,分表间存在相同键值时,忽略分表号较小的分表中的记录。分段要以第1分表为准。 处理更新标记,有删除标识的记录不返回到游标中,删除标识记录的键值在复组表中是唯一时,该条记录也会被保留。 使用该选项时,强制读出键字段,如果表中有删除标识列,则也会被强制读出。 |
|
@p |
T为复组表,按照第一个字段归并。 |
返回值:
多路游标
示例:
|
|
A |
|
|
1 |
for 100 |
|
|
2 |
返回序表:
|
|
|
3 |
=to(10000).new(#:k1,rand(10000):c2).sort@o(k1) |
返回序表:
|
|
4 |
=to(10000).new(#:k1,rand()*1000:c3).sort@o(k1) |
返回序表:
|
|
5 |
=A2.cursor() |
返回游标。 |
|
6 |
=A3.cursor() |
返回游标。 |
|
7 |
=A4.cursor() |
返回游标。 |
|
8 |
=file("D:\\cs1.ctx") |
生成组表文件。 |
|
9 |
=A8.create(#k1,c1) |
创建组表的基表。 |
|
10 |
=A9.append(A5) |
将A5游标中的数据追加到基表中。 |
|
11 |
=A9.attach(table1,c2) |
在基表上创建附表table1。 |
|
12 |
=A11.append(A6) |
将A6游标中的数据追加到附表table1中。 |
|
13 |
=A11.cursor@m(;;2) |
对附表table1进行分段,结果返回多路游标。 |
|
14 |
=A9.attach(table2,c3) |
在基表上创建附表table2。 |
|
15 |
=A14.append(A7) |
将A7游标中的数据追加到附表table2中。 |
|
16 |
=A14.cursor@v(;;A13) |
根据多路游标A13同步分段附表table2。 |



|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME from employee") |
|
|
2 |
=file("emp.ctx") |
生成组表文件。 |
|
3 |
=A2.create@y(#EID,NAME) |
创建组表的基表。 |
|
4 |
=A3.append(A1) |
将A1游标中的数据追加到组表基表中。 |
|
5 |
=A4.cursor@m(;;3) |
将组表生成路数为3的多路游标。 |
|
6 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee") |
|
|
7 |
=file("emp.ctx":[1,2]) |
生成文件组。 |
|
8 |
=A7.create@y(#EID,NAME,GENDER,SALARY;if(GENDER=="F",1,2)) |
创建复组表。 |
|
9 |
=A8.append@x(A6) |
将A6游标中的数据追加到复组表中,此时复组表内容如下:
|
|
10 |
=A8.cursor(EID,NAME,GENDER,SALARY;SALARY>5000;A5) |
将复组表根据多路游标A5同步分段,默认归并,返回游标内容如下:
可以看到两个分表中的内容已经按维归并。 |


多种过滤方式:
|
|
A |
|
|
1 |
=file("emp.ctx") |
|
|
2 |
=A1.open() |
打开组表文件。 |
|
3 |
=A2.import() |
省略参数,返回实表中的所有数据 :
|
|
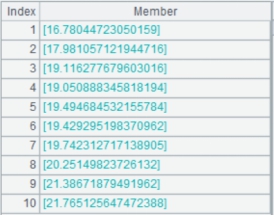
4 |
=file("emp1.ctx").open().cursor@m(;;2) |
返回多路游标。 |
|
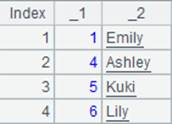
5 |
=5.new(~:ID,~*~:Num).keys(ID) |
生成ID为键的序表:
|
|
6 |
=A2.cursor(EID,NAME;EID=A5.find(EID);A4) |
使用K=w过滤方式,w是Ti.find(K),实表中使EID=A4.find(EID)计算结果为null或false的记录过滤掉;EID为选出字段,赋值为序表A5的指引字段:
|
|
7 |
=A2.cursor(EID,NAME;EID=A5.pfind(EID);A4) |
使用K=w过滤方式,w是Ti.pfind(K),实表中使EID=A4.pfind(EID)计算结果为null或false的记录过滤掉;EID为选出字段,赋值为EID在序表A5中的序号:
|
|
8 |
=A2.cursor(EID,NAME;EID:A5;A4) |
使用K:Ti过滤方式,用实表中EID的值与序表的键值作对比,匹配不上的将被过滤掉:
|
|
9 |
=A2.cursor(NAME,SALARY;EID:A5;A4) |
K不被选出的情况,EID不是选出字段,仅过滤:
|
|
10 |
=A2.cursor(EID,NAME;EID:A5:null;A4) |
使用K:Ti:null过滤方式,用实表中EID的值与序表的键值作对比,可以匹配上的将被过滤掉:
|
|
11 |
=A2.cursor(EID,NAME;EID:A5:#;A4) |
使用K:Ti:#过滤方式,根据实表中EID的值去对比序表的记录序号,对应不上的记录将被过滤掉:
|
|
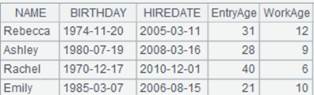
12 |
=connect("demo").query("select top 2 NAME,GENDER from employee").keys(NAME) |
返回序表,键为NAME:
|
|
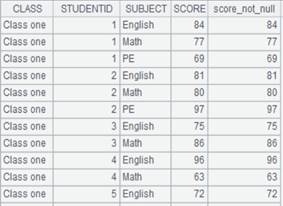
13 |
=A2.cursor(EID,NAME;(EID=A5.find(EID),NAME=A12.find(NAME),EID!=null&&NAME!=null);A4) |
使用(K1=w1,…Ki=wi,w)过滤方式,返回符合所有条件的记录:
|
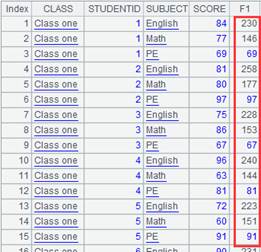
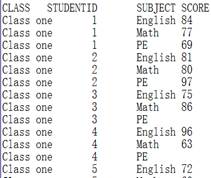




使用@w选项,识别更新标识:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME from employee") |
|
|
2 |
=file("e-mcs.ctx") |
生成组表文件。 |
|
3 |
=A2.create@y(#EID,NAME) |
创建组表的基表。 |
|
4 |
=A3.append(A1) |
将A1游标中的数据追加到组表基表中。 |
|
5 |
=A4.cursor@m(;;3) |
将组表生成路数为3的多路游标。 |
|
6 |
=connect("demo").cursor("select EID,NAME,GENDER from employee") |
|
|
7 |
=A6.derive(:Defiled) |
|
|
8 |
=A7.new(EID,Defiled,NAME,GENDER) |
返回游标,内容如下:
|
|
9 |
=file("ecd.ctx":[1,2]) |
文件组1.ecd.ctx、2.ecd.ctx。 |
|
10 |
=A9.create@yd(#EID,Defiled,NAME,GENDER;if(GENDER=="F",1,2)) |
创建复组表,EID为键,使用@d选项,将Defiled作为更新标识字段,GENDER值为F的记录分到1.ed.ctx中,其余分到2.ed.ctx中。 |
|
11 |
=A10.append@ix(A8) |
将A3游标中的数据追加到复组表中。 |
|
12 |
=create(EID,Defiled,NAME,GENDER).record([0,true,,,1,true,,, 2,false,"BBB","F"]) |
返回序表内容如下:
|
|
13 |
=file("ecd.ctx":[3]) |
|
|
14 |
=A13.create@yd(#EID,Defiled,NAME,GENDER;3) |
增加分表3.ecd.ctx,Defiled为更新标识字段。 |
|
15 |
=A14.append@i(A12) |
将A12序表中的记录追加到分表3.ecd.ctx中。 |
|
16 |
=file("ecd.ctx":[1,2,3]).open() |
|
|
17 |
=A16.cursor(;;A5) |
将复组表ecd.ctx根据A5同步分段,返回多路游标。 |
|
18 |
=A17.fetch() |
读取游标中的数据:
|
|
19 |
=A16.cursor@w(;;A5) |
使用@w选项,将复组表ecd.ctx根据A5分段,返回成游标多路游标,识别更新标识,即: EID为1的记录更新标识为true(删除)不返回到游标中; EID为2的记录更新标识为false(修改),更新该记录; EID为0的记录更新标识为true(删除),规定带删除标识且键值唯一的记录会被保留下来,所以该记录会返回到多路游标中。 |
|
20 |
=A19.fetch() |
读取游标中的数据:
|