select()
本章介绍select()的多种用法。
A.select()
描述:
选出序列中符合条件的成员。
语法:
|
A.select( x ) |
|
|
A.select(x1:y1, x2:y2, ......xi:yi) |
多个条件时用&&组合查询的简化写法,相当于A.select(x1== y1 && x2== y2 &&...... xi==yi)。 |
备注:
针对序列A的每个成员计算表达式x,返回使表达式的值为真的成员组成的新序列。参数省略时返回所有成员。
注意,当序列中的列名与单元格格名冲突时,表达式中引用列名时需要加上序列名称作为前缀。
选项:
|
@1 |
返回第一个成员,找不到符合条件的成员时返回null。 |
|
@z |
从后往前查找。 |
|
@b |
使用二分法查询,要求A必须是升序序列,并且参数必须是使用x:y格式或者是返回数值的表达式,数值表达式结果为0则表示找到。 |
|
@m |
数据量大的复杂运算中并行计算提升性能,计算次序不确定,与@1bz选项互斥。 |
|
@t |
当A是序表且返回值为空时,返回一个保留数据结构的空序表。 |
|
@c |
从第一成员开始取,到第一个不满足x为真的成员停止。 |
|
@r |
从前往后查找第一个满足条件的成员,然后从这个成员一直取到序列的最后一个成员。 |
|
@v |
A是纯序表时,返回成纯序表,该选项缺省时返回纯序列。仅企业版适用。 |
|
@0 |
找不到符合条件的成员时返回null,该选项缺省时返回空序列。 |
参数:
|
A |
序列。 |
|
x |
布尔表达式,可为null。 |
|
xi:yi |
xi 为表达式,yi为比较值。 |
返回值:
序列/序表
示例:
|
|
A |
|
|
1 |
[2,5,4,3,2,1,4,1,3] |
|
|
2 |
=A1.select(~>3) |
[5,4,4] |
|
3 |
=A1.select@1(~>3) |
5,返回符合条件的第一个成员。 |
|
4 |
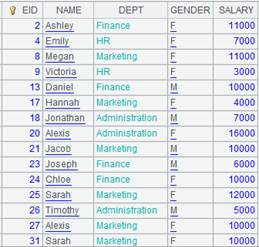
=demo.query("select EID,NAME,GENDER,DEPT,SALARY from EMPLOYEE order by EID") |
|
|
5 |
=A4.select(GENDER:"F",SALARY:16000) |
多条件查询:
|
|
6 |
=A4.select@t(EID==2000) |
返回一个保留数据结构的空序表:
|
|
7 |
=A1.select (~>8) |
返回空序列。 |
|
8 |
=A1.select@0(~>8) |
返回null。 |
指定查询方向:
|
|
A |
|
|
1 |
[2,5,4,3,2,1,4,1,3] |
|
|
2 |
=A1.select(~>3) |
[5,4,4] |
|
3 |
=A1.select@z(~>3) |
[4,4,5],从后往前查。 |
|
4 |
[8,10,3,5,7,9,11,13,7] |
|
|
5 |
=A4.select@c(~>7) |
[8,10],从第一个成员往后取,到第一个不满足条件的成员停止。 |
|
6 |
=A4.select@zc(~>6) |
[7,13,11,9,7],从最后一个成员往前取,到第一个不符合条件的成员停止。 |
|
7 |
=A4.select@r(~>10) |
[11,13,7],从前往后查找第一个满足条件的成员,然后从这个成员一直取到最后。 |
高效率筛选:
|
|
A |
|
|
1 |
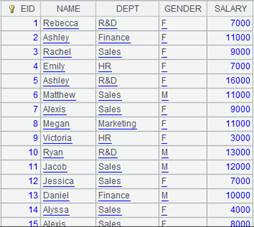
=demo.query("select EID,NAME,GENDER,DEPT,BIRTHDAY from employee") |
|
|
2 |
=A1.select@m(GENDER=="F") |
使用@m选项,数据量大时使用并行计算,提升性能。 |
|
3 |
=A1.sort(GENDER).select@b(GENDER:"F") |
将A1根据GENDER升序排序,此时可使用二分法查询,表达式中使用冒号,查询GENDER值为F的数据。 |
|
4 |
=A1.sort(EID).select@b(EID-10) |
将A1根据EID升序排序,此时可使用二分法查询,参数使用返回数值的表达式,查询EID为10的数据。 |
列名与格名冲突的情况:
|
|
A |
|
|
1 |
=to(3).new(~:ID,~*~:A1) |
|
|
2 |
=A1.select(A1.A1==4) |
当列名与格名冲突时,表达式中引用列名需要加上序列名称作为前缀。
|
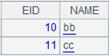
返回纯序表 :
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,GENDER,DEPT,BIRTHDAY from employee").keys(EID) |
|
|
2 |
=A1.i() |
将序表A1转换为纯序表。 |
|
3 |
=A2.select(GENDER=="M") |
返回结果类型为纯序列。 |
|
4 |
=A2.select@v(GENDER=="F") |
使用@v选项,返回结果类型为纯序表。 |
相关概念:
T.select@i()
选出序表中符合条件的成员。
语法:
T.select@i( x )
备注:
针对序表T的每个成员计算表达式x,返回符合过滤条件的成员组成的新序表。
T为建立索引的序表,使用T.select@i()时会复用T的索引,结果集次序可能会被打乱。
参数省略时返回所有成员。
参数:
|
T |
建立了索引的序表。 |
|
x |
过滤条件,可为null。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
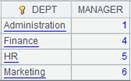
=demo.query("select * from DEPT").keys@i(DEPTID) |
|
|
2 |
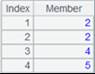
=A1.select@i(FATHER==12) |
复用A1创建的索引,返回A1序表中FATHER为12的记录 :
|

T.select()
描述:
虚表定义筛选记录操作后返回新虚表。
语法:
虚表T定义计算,对每条记录计算表达式x,筛选出表达式x值为真的记录,返回新虚表。
参数x省略时筛选出所有记录。
参数:
|
T |
虚表。 |
|
x |
布尔表达式,过滤条件,可为null。 |
返回值:
虚表对象
示例:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/app.ctx"]) |
组表app.ctx数据内容如下:
|
|
2 |
=pseudo(A1) |
生成虚表对象。 |
|
3 |
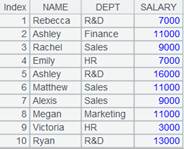
=A2.select(EID>7) |
虚表A2定义计算,筛选出EID>7的记录,返回新虚表。 |
|
4 |
=A3.import() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|
|
5 |
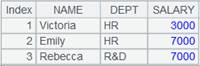
=A2.select() |
虚表A2定义计算,筛选出所有记录,返回新虚表。 |
|
6 |
=A5.import() |
读取A5虚表中的数据,此时A2虚表执行A5中定义的计算操作,返回内容如下:
|
ch.select()
描述:
管道附加筛选记录动作后返回原管道。
ch.select(x)
备注:
管道ch中附加计算,对每条记录计算表达式x,筛选出表达式x值为真的记录,返回原管道ch。
参数x省略时筛选出所有记录。
|
ch |
管道。 |
|
x |
布尔表达式。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
=demo.cursor("select * from SALES") |
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=A2.select(ORDERID>100) |
管道附加计算,筛选出ORDERID>100的记录,返回原管道。 |
|
4 |
=A2.fetch() |
保留管道当前数据。 |
|
5 |
=A1.push(A2) |
将游标A1中的数据推送到管道,此时数据不会立即被推送到管道。 |
|
6 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
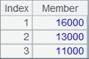
7 |
=A2.result() |
获取管道计算结果:
|
ch.select(x,ch’)
描述:
把管道中不满足条件的记录推送到另一个管道。
语法:
ch.select(x,ch’)
备注:
针对管道ch中每条记录计算表达式x,把表达式x的值为假的记录推送到管道ch’中。
参数:
|
ch |
管道。 |
|
x |
布尔表达式。 |
|
ch’ |
管道。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,SALARY from EMPLOYEE " ) |
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=channel() |
创建管道。 |
|
4 |
=A1.push(A2) |
将游标A1中的数据推送到管道A2。 |
|
5 |
=A2.select(EID<5,A3) |
将管道A2中不满足EID<5的数据推送到管道A3。 |
|
6 |
=A2.fetch() |
A2管道附加结果集函数ch.fetch(),保留管道当前数据。 |
|
7 |
=A3.fetch() |
A3管道附加结果集函数ch.fetch(),保留管道当前数据。 |
|
8 |
=A1.skip() |
游标A1执行取数时程序才会执行管道中的计算,游标中的数据才真正被推送到管道。 |
|
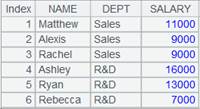
9 |
=A2.result() |
获取管道A2的计算结果:
|
|
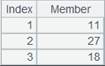
10 |
=A3.result() |
获取管道A3的计算结果:
|
cs.select()
描述:
语法:
cs.select(x)
游标cs中附加计算,对每条记录计算表达式x,筛选出表达式x值为真的记录,返回原游标cs。
参数x省略时筛选出所有记录。支持多路游标。
该函数属于延迟计算函数。
选项:
|
@v |
cs为列式游标时,使用列式计算,结果返回列式游标。 |
参数:
|
cs |
游标。 |
|
x |
布尔表达式。 |
返回值:
游标
示例:
|
|
A |
|
|
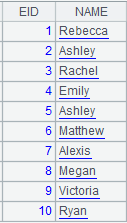
1 |
=demo.cursor("select * from SCORES") |
返回游标:
|
|
2 |
=A1.select(STUDENTID>10) |
A1游标附加计算动作,筛选出STUDENTID大于10的记录,返回A1游标:
|
|
3 |
=A1.fetch() |
读取A1游标执行计算后的数据(数据量较大时建议分批读取):
|
使用@v选项:
|
|
A |
|
|
1 |
=connect("demo").cursor@v("select * from employee") |
返回列式游标。 |
|
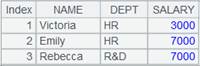
2 |
=A1.select@v(DEPT=="HR") |
使用列式计算。 |
cs.select(x,ch’)
描述:
把游标中不满足条件的记录推送到管道。
语法:
cs.select(x,ch’)
备注:
针对游标cs中每条记录计算表达式x,把表达式x的值为假的记录推送到管道ch’中。
参数:
|
cs |
游标。 |
|
x |
布尔表达式。 |
|
ch’ |
管道。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,SALARY from EMPLOYEE" ) |
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=A1.select(EID<5,A2) |
将游标A1中不满足条件EID<5的数据推送到管道。 |
|
4 |
=A2.fetch() |
保留管道当前数据。 |
|
5 |
=A1.fetch() |
获取筛选后的游标中的数据:
|
|
6 |
=A2.result() |
获取管道计算结果:
|

cs.select(x;f)
游标附加筛选记录动作后返回原游标,并不满足条件的记录写入集文件。
语法:
备注:
游标cs附加筛选记录动作,对每条记录计算表达式x,筛选出x值为真的记录,返回原游标cs,然后把x值为假的记录写入集文件f中。
该函数属于延迟计算函数。
参数:
|
cs |
游标。 |
|
x |
布尔表达式。 |
|
f |
集文件。 |
返回值:
游标
示例:
|
|
A |
|
|
1 |
=demo.cursor("select * from dept") |
返回游标:
|
|
2 |
=file("dept.btx") |
生成集文件对象。 |
|
3 |
=A1.select(DEPTID<5;A2) |
A1游标附加计算,筛选出满足DEPTID <5条件的记录,返回A1游标:
然后将不满足DEPTID <5的记录写入主目录下的集文件dept.btx中。 |
|
4 |
=A1.fetch() |
A1游标执行取数动作后,才会真正生成dept.btx集文件;读取A1游标执行筛选计算后的数据如下(数据量较大时建议分批读取):
|