reset()
本章介绍reset()函数的多种用法。
cs.reset()
描述:
回转游标再移回头。
语法:
cs.reset()
备注:
当游标到头之后,将游标回转再移回头。
注意,以下计算方式返回的游标不可回转:db.cursor@x(),f.cursor@x(), cs.groupx(), cs.sortx(), cs.joinx(),cursor(spl,…)。
参数:
|
cs |
游标。 |
返回值:
游标
示例:
|
|
A |
|
|
1 |
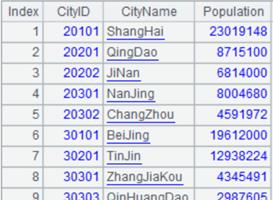
=demo.cursor("select * from scores") |
返回取数游标。 |
|
2 |
=A1.fetch() |
从游标中获取数据:
|
|
3 |
=A1.fetch() |
因为A1游标已到头,所以返回空。 |
|
4 |
=A1.reset() |
|
|
5 |
=A1.fetch() |
获取到数据,返回结果与A2相同。 |
相关概念:
f.reset()
描述:
重整组表文件/文件组进新组表文件/文件组。
语法:
|
f.reset(f’:b;cs) |
重整组表文件/文件组进新组表文件。 |
|
f.reset(f’:b,x;cs) |
重整组表文件/文件组进新文件组。 |
备注:
重整组表文件/文件组f进新组表文件/文件组f’。
f为组表文件时,参数f’可以是组表文件也可以是文件组,f’是文件组时,x为分表表达式,x不可省略;参数f’省略则重整f并重建索引。
f为文件组时,f’不能省略;f’为组表文件则按维度归并;f’是文件组时可以通过x改变分表分布结构,x省略时分表的分布结构不变。
有参数cs时,将cs中的数据一起合并进f’。
参数:
|
f |
组表文件/文件组。 |
|
f’ |
组表文件/文件组。 |
|
b |
区块大小,单位为字节,缺省使用选项中设置的组表区块大小的值;第三方应用程序中集成使用时,缺省为raqsoftConfig.xml文件中配置的blockSize的值。 |
|
x |
分表表达式。 |
|
cs |
游标/序表。 |
选项:
|
@u |
写成不压缩的文件,无选项则保持原来属性。 |
|
@z |
写成压缩文件,无选项则保持原来属性。 |
|
@r |
写成行存,无选项则保持原来属性。 |
|
@c |
写成列存。 |
|
@w |
用于带有更新标识的复组表,用更新机制归并,分表间存在相同键值时,忽略分表号较小的分表中的记录。 处理更新标识,有删除标记的记录不写入新组表文件中,删除标记记录的键值在分表是唯一时,该条记录也会被保留。 |
|
@q |
f是文件组且f’是组表文件时使用,不做归并,仅做简单合并,忽略参数x与cs。 |
|
@y |
目标文件存在时强行覆盖,缺省会报错失败。 |
返回值:
Boolean值
示例:
f为组表文件时:
|
|
A |
|
|
1 |
=file("D:\\test1.ctx") |
已存在的组表文件。 |
|
2 |
=A1.reset(file("D:\\e1.ctx")) |
重整组表文件test1.ctx数据到组表文件e1.ctx中。 |
|
3 |
=A1.reset() |
省略参数f’,清理test1.ctx并重建索引。 |
|
4 |
=A1.reset@r(file("D:\\e5.ctx")) |
复制组表文件test1 为行存文件。 |
|
5 |
=file("D:\\emp12.ctx") |
|
|
6 |
打开组表文件,组表基表数据内容如下:
|
|
|
7 |
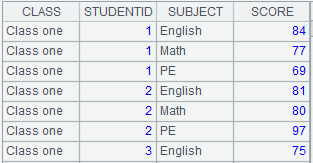
=create(EID,NAME).record([4,"Emily"]) |
|
|
8 |
=A6.delete(A7) |
从组表中删除A7的记录。 |
|
9 |
>A6.close() |
关闭组表。 |
|
10 |
=A5.reset(file("empNew.ctx"):1048576) |
重整组表文件emp12.ctx到empNew.ctx中,同时设置区块大小为1048576字节。 |
f为复组表时:
|
|
A |
|
|
1 |
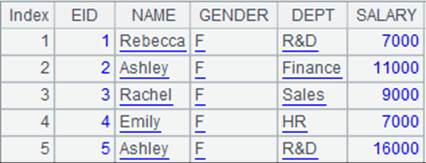
=file("emp.ctx":[1,2]) |
已存在的文件组,内容分别为:
分表1.emp.ctx中为GENDER为F的数据,分表2.emp.ctx中为GENDER为M的数据。 |
|
2 |
=A1.reset(file("empAll.ctx")) |
将复组表1.emp.ctx、2.emp.ctx按维度归并到组表文件empAll.ctx中:
|
|
3 |
=file("empRe.ctx":[1,2]) |
返回文件组对象。 |
|
4 |
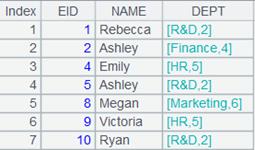
=A1.reset(A3) |
将复组表1.emp.ctx、2.emp.ctx数据重整后写入复组表empRe.ctx中,分表的分布结构不改变, 内容分别为:
|
|
3 |
=file("empN.ctx":[1,2]) |
返回文件组对象。 |
|
4 |
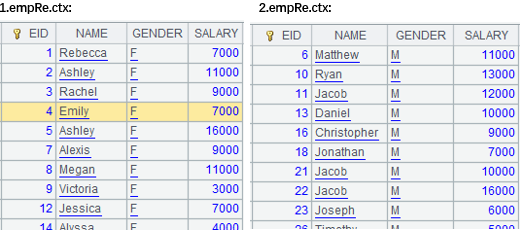
=A1.reset(A5,if(SALARY<10000,1,2)) |
将复组表1.emp.ctx、2.emp.ctx数据重整后写入复组表empN.ctx中,并通过分表表达式改变分表 的分布结构,SALARY<1000的记录写入1.empN.ctx中,其余写入2.empN.ctx中:
|
有cs参数时:
|
|
A |
|
|
1 |
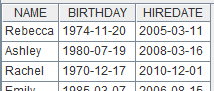
=file("apm.ctx") |
已存在的组表文件,内容如下:
|
|
2 |
=create(EID,NAME).record([5,"Ashley"]).cursor() |
返回游标,数据内容如下:
|
|
3 |
=file("re1.ctx") |
返回组表文件对象。 |
|
4 |
=A1.reset(A3;A2) |
重整组表文件apm.ctx的数据及A2游标中的数据一起合并进re1.ctx中。 |
|
5 |
=create(EID,NAME).record([10,"Ryan"]) |
返回序表:
|
|
6 |
=A3.reset(;A5) |
重整组表文件re1.ctx的数据,并将A5序表中的数据一起合并进去。 |
|
7 |
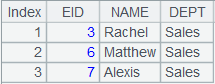
=A3.open().import() |
读取re1.ctx中的数据,返回内容如下:
|

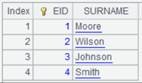
使用@q选项,将文件组简单合并到组表文件中:
|
|
A |
|
|
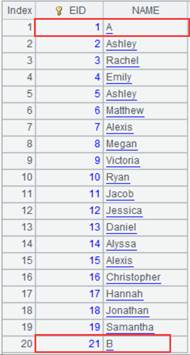
1 |
=file("emr.ctx":[1,2]) |
已存在的文件组,分表1.emr.ctx中为GENDER为F的数据:
分表2.emr.ctx中为GENDER为M的数据:
|
|
2 |
=file("empHb.ctx") |
|
|
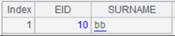
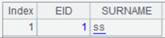
3 |
=A1.reset@q(A2) |
使用@q选项,将复组表1.emr.ctx、2.emr.ctx简单合并到组表文件empHb.ctx中,empHb.ctx内容如下:
|
使用@w选项,处理更新标识:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME,GENDER from employee") |
|
|
2 |
=A1.derive(:Defiled) |
|
|
3 |
=A2.new(EID,Defiled,NAME,GENDER) |
返回游标,内容如下:
|
|
4 |
=file("er.ctx":[1,2]) |
文件组1.er.ctx、2.er.ctx。 |
|
5 |
=A4.create@yd(#EID,Defiled,NAME,GENDER;if(GENDER=="F",1,2)) |
创建复组表,EID为键,使用@d选项,将Defiled作为更新标识字段,GENDER值为F的记录分到1.ed.ctx中,其余分到2.ed.ctx中。 |
|
6 |
=A5.append@ix(A3) |
将A3游标中的数据追加到复组表中。 |
|
7 |
=create(EID,Defiled,NAME,GENDER).record([0,true,,,1,false,"AAA","M",2,true,,]) |
返回序表内容如下:
|
|
8 |
=file("er.ctx":[3]) |
|
|
9 |
=A8.create@yd(#EID,Defiled,NAME,GENDER;3) |
增加分表3.er.ctx。 |
|
10 |
=A9.append@i(A7) |
将A7序表中的内容追加到分表3.er.ctx中。 |
|
11 |
=file("er.ctx":[1,2,3]) |
|
|
12 |
=A11.open().import() |
读取复组表er.ctx中的数据:
|
|
13 |
=file("er_w.ctx") |
返回组表对象。 |
|
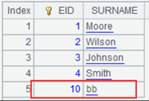
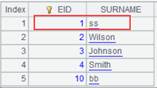
14 |
=A11.reset@w(A13) |
将er.ctx文件组中的数据重整进er_w.ctx中,使用@w选项,用更新机制归并,即: EID为1的记录更新标识为false(修改),更新该记录; EID为2的记录更新标识为true(删除)不写入er_w.ctx中; EID为0的记录更新标识为true(删除),规定带删除标识且键值唯一的记录会被保留下来,所以该记录会被保留下来。 |
|
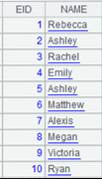
15 |
=A13.open().import() |
读取复组表er_w.ctx中的数据:
|

T.reset ()
描述:
清空序表成员。
语法:
T.reset()
备注:
清空序表T的成员,保留数据结构。
参数:
|
T |
序表。 |
返回值:
空序表
示例:
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE") |
|
|
2 |
=A1.reset() |
|