
regex()
本章介绍regex()函数的多种用法。
s.regex()
描述:
用正则表达式匹配字符串。
语法:
s.regex(rs,rpls)
备注:
用正则表达式rs匹配字符串s,并将s里第一个匹配的字符替换成字符串rpls,返回替换后的字符串。
参数rpls缺省则返回可匹配的字符串组成的序列,不匹配时返回null。
参数:
|
s |
字符串。 |
|
rs |
正则表达式。 |
|
rpls |
字符串。 |
选项:
|
@c |
大小写不敏感。 |
|
@u |
使用unicode。 |
|
@a |
替换所有匹配的字符。 |
|
@w |
整个字符串匹配。 |
|
@p |
将返回的数字串解析成数值。 |
返回值:
序列/字符串/数值
|
|
A |
|
|
1 |
4,23,a,test |
|
|
2 |
a,D |
|
|
3 |
小明,中国 |
|
|
4 |
=A1.regex("(\\d),([0-9]*),([a-z]),([a-z]*)") |
|
|
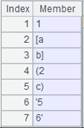
5 |
=A2.regex@c("([a-z]),([a-z])") |
使用@c选项,不区分大小写:
|
|
6 |
=A2.regex("([a-z]),([a-z])") |
不匹配返回null。 |
|
7 |
=A3.regex@u("(\\u5c0f\\u660e),(\\u4e2d\\u56fd)") |
使用unicode匹配:
|
|
8 |
=A1.regex("([0-9])","hello") |
hello,23,a,test |
|
9 |
=A1.regex@a("([0-9])","hello") |
hello,hellohello,a,test |
|
10 |
="123abc".regex("[0-9]a") |
123abc |
|
11 |
="123abc".regex@w("[0-9]a") |
使用@w选项,整个字符串匹配,结果返回null。 |
|
12 |
="9,20,hello,6.269".regex("([0-9.]+)") |
返回字符串组成的序列:
|
|
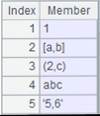
13 |
="9,20,hello,6.269".regex@p("([0-9.]+)") |
将返回的数字串解析成数值:
|
相关概念:
A.regex()
描述:
用正则表达式匹配序列中的字符串成员。
语法:
|
A.regex(rs,Fi) |
正则表达式rs无拆出项时,用数据类型为字符串的字段Fi和rs匹配。返回排列A中经过过滤后的新排列。Fi省略时用当前记录和rs匹配。 |
|
A.regex(rs;Fi,…) |
正则表达式rs有拆出项时,用正则表达式rs拆分序列A中的字符串成员,返回结果拼成以Fi为字段的序表。 |
备注:
用正则表达式rs匹配序列A中的字符串成员,返回结果拼成以Fi为字段的序表。
参数:
|
A |
成员为字符串的序列或排列。 |
|
rs |
正则表达式。 拆出项指的是以分隔符分隔的多个正则表达式,并且每个正则表达式用括号括起来。每个拆出项匹配按顺序对应的字段。例如:"(.*),(a.*)" 为逗号分隔的两个拆出项。 |
|
Fi |
字段名,数据类型为字符串。 |
选项:
|
@c |
大小写不敏感。 |
|
@u |
使用unicode。 |
|
@p |
将结果序表中的数字串解析成数值。 |
返回值:
序表
|
|
A |
|
|
1 |
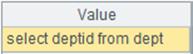
=demo.query("select NAME,SURNAME from EMPLOYEE") |
|
|
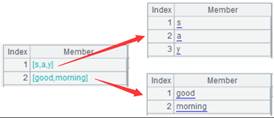
2 |
=A1.(~. array().concat@c()) |
转换为字串序列:
|
|
3 |
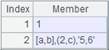
=A2.regex("A.*") |
省略Fi,默认用当前记录和rs匹配:
|
|
4 |
=A2.regex("(V.*),(.*)";name,surname) |
对A2成员正则匹配后返回序表:
|
|
5 |
=file("D:\\a.txt").import@ts() |
|
|
6 |
=A5.(#1).regex@c("(.*),(a.*)";id,name) |
匹配姓名以a或A开头的人员:
|
|
7 |
=demo.query("select 部门,姓名 from 员工表") |
|
|
8 |
=A7.(~.array().concat@c()) |
|
|
9 |
=A8.regex@u("(\\u9500\\u552e\\u90e8),(.*)";销售部,员工姓名) |
使用unicode匹配销售部:
|
|
10 |
=A1.regex("V.*",NAME) |
正则表达式rs无拆出项时,用数据类型为字符串的字段Fi和rs匹配:
|
|
11 |
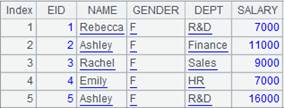
=demo.query("select EID,NAME,SALARY from EMPLOYEE").(~. array().concat@c()) |
返回成员为字符串的序列:
|
|
12 |
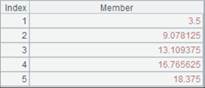
=A11.regex@p("(.*),(V.*),(.*)";id,name,salary) |
使用@p选项,将结果序表中的数字串解析成数值:
|



相关概念:
cs.regex()
描述:
游标中附加正则匹配动作后返回原游标。
cs.regex(rs;Fi,…)
备注:
游标cs中附加计算,用正则表达式rs匹配cs中的字符串成员,结果形成以Fi 为字段的序表返回到原游标cs中,支持多路游标。
该函数属于延迟计算函数。
参数:
|
cs |
成员为字符串的游标。 |
|
rs |
正则表达式。 |
|
Fi |
结果字段名。 |
选项:
|
@c |
大小写不敏感。 |
|
@u |
使用unicode。 |
|
@p |
将数字串解析为数值。 |
返回值:
游标
示例:
|
|
A |
|
|
1 |
["1,Rebecca","2,ashley","3,Rachel","4,Emily","5,Ashley","6,Matthew", "7,Alexis","8,Megan","9,Victoria","10,Ryan"] |
|
|
2 |
=A1.cursor() |
返回游标。 |
|
3 |
=A2.regex("(.*),(A.*)";id,name) |
A2游标附加计算,匹配逗号后面以A开头的成员,默认大小写敏感,返回A2游标。 |
|
4 |
=A2.fetch() |
读取A2游标执行A3计算后的数据:
|

使用@c选项,大小写不敏感:
|
|
A |
|
|
1 |
["1,Rebecca","2,ashley","3,Rachel","4,Emily","5,Ashley","6,Matthew", "7,Alexis","8,Megan","9,Victoria","10,Ryan"] |
|
|
2 |
=A1.cursor() |
返回游标。 |
|
3 |
=A2.regex@c("(.*),(A.*)";id,name) |
A2游标附加计算,使用@c选项,大小写不敏感,匹配逗号后面以A或a开头的成员,返回A2游标。 |
|
4 |
=A2.fetch() |
读取A2游标执行A3计算后的数据:
|

使用@u选项:
|
|
A |
|
|
1 |
["销售部,李英梅","人事部,王芳","技术部,张峰","销售部,孙超"] |
|
|
2 |
=A1.cursor() |
返回游标。 |
|
3 |
=A2.regex@u("(\\u9500\\u552e\\u90e8),(.*)";部门,员工姓名) |
A2游标附加计算,使用@u选项,匹配“销售部”开头的成员,返回A2游标。 |
|
4 |
=A2.fetch() |
读取A2游标执行A3计算后的数据:
|

使用@p选项:
|
|
A |
|
|
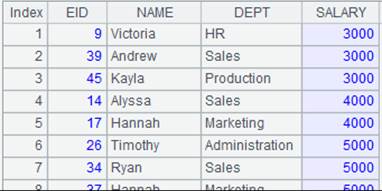
1 |
=demo.cursor("select EID,NAME,SALARY from EMPLOYEE").(~. array().concat@c()) |
返回游标,数据内容如下:
|
|
2 |
=A1.regex@p("(.*),(V.*),(.*)";id,name,salary) |
使用@p选项,将结果中的数字串解析成数值。 |
|
3 |
=A2.fetch() |
读取A1游标执行A2计算后的数据:
|
相关概念: