
query()
本章介绍query()函数的多种用法。
db.query()
描述:
在数据源中查询指定的SQL,返回查询结果所组成的序表。
|
db.query( sql {,args …}) |
|
|
db.query(A,sql{,args …}) |
针对A执行sql,返回结果集合并的序表,args可以是A的表达式。支持选项@idx。 |
备注:
在数据源db中查询指定的SQL,返回SQL的查询结果所组成的序表。
sql中FROM后是单表时,自动设置结果序表的键。
当数据源名称为空时,认为该语句为简单SQL。
参数:
|
db |
数据库连接,其中包含esProc-JDBC数据源。 |
|
sql |
可以是sql查询,也可以是call spl()调用语句; 参数为”call spl()”时,表示通过esProc-ODBC数据源db调用集算器网格文件,文件格式为splx,网格文件可使用相对路径或绝对路径,相对路径时相对于寻址路径,返回网格文件的结果集。 |
|
args |
传递给sql的参数;可以是参数值,也可以是定义过的参数名称,多个参数之间用逗号分隔。 |
|
A |
序列,对着A循环执行sql,一般是利用A计算出不同的args传给sql去执行。 |
选项:
|
@1( sql {,args …}) |
只返回符合条件的第一条记录, 返回成单值或序列。 |
|
@i |
结果集只有1列时返回成序列。 |
|
@d |
将numeric型数据转换成double型数据,而非decimal型数据。 |
|
@x |
结束时自动关闭数据库连接,仅限用connect连接的数据库连接。 |
|
@v |
返回纯序列/纯序表。仅企业版适用。 |
返回值:
示例:
sql查询语句:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES") |
db参数为数据源名称,此时要求demo是连接成功的状态,查询SCORES表中的所有数据。 |
|
2 |
=connect("demo") |
|
|
3 |
=A2.query@x("select * from SCORES") |
connect连接方式,可以使用@x选项。 |
|
4 |
=A2.query("select * from STUDENTS") |
正常会出现报错:Data Source demo is shutdown or wrong setup.,提示数据源未启动,这是由于A3计算结束时自动关闭了数据库连接。 |
sql中有参数:
|
|
A |
|
|
1 |
>arg2="R&D" |
定义参数名为arg2,参数值为"R&D"。 |
|
2 |
=demo.query("select EID,NAME,DEPT,GENDER from employee where EID<? and DEPT=? and GENDER=?",arg1,arg2,"M") |
查询employee表中的内容,其中arg1为网格参数,参数值为100,arg2为A1格中定义的参数,第三个参数直接传递参数值为“M”。
|
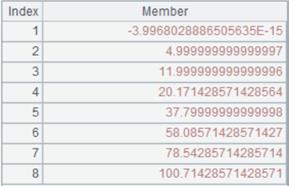
根据序列A查询sql:
|
|
A |
|
|
1 |
|
|
|
2 |
=demo.query(A1,"select EID,NAME from EMPLOYEE where EID=?",~*~) |
通过序列A1计算出参数值为[1,4,9,16],参数值传入SQL中返回计算结果:
|
sql中使用call spl()语法, t1.splx如下:
|
|
A |
|
|
1 |
=power(a,b) |
a,b分别为t1.splx中的网格参数。 |
|
|
A |
|
|
1 |
=connect("MyOdbc").query("call D:/t1(?,?)",2,3) |
调用t1.splx,并向其中传递参数值,a值为2,b值为3,返回结果为8。 MyOdbc为esproc-ODBC数据源名称。 |
sql为简单SQL:
|
|
A |
|
|
1 |
=connect().query("select * from D:/cities.txt") |
数据源名称为空时,参数sql为简单SQL,查询cities.txt数据文件内容。 |
返回其他类型结果:
|
|
A |
|
|
1 |
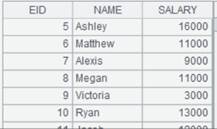
从demo数据源中查询STUDENTS表的NAME字段,返回内容如下:
|
|
|
2 |
=demo.query@i("select NAME from STUDENTS") |
结果集只有一列时,使用@i选项,返回序列。
|
|
3 |
=demo.query@v("select * from STUDENTS") |
返回纯序表。 |
|
4 |
=demo.query@iv("select NAME from STUDENTS") |
返回纯序列。 |
|
5 |
=mysql.query@d("select * from ta") |
使用@d选项,numeric型数据将被转换成double:
|
|
6 |
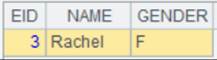
=demo.query@1("select NAME from STUDENTS") |
返回单值:Emily。 |


相关概念: