pivot()
本章节介绍pivot()函数的用法。
A.pivot( g:G , … ; F , V ; N i : N' i ,… )
描述:
将序表/排列进行行列转换操作。
语法:
A.pivot(g:G,…;F,V;Ni:N'i,…)
备注:
将序表/排列A进行行列转换操作,默认为行转列。A根据字段/表达式g分组, G为g列的列名,将字段F中的值Ni作为新的列字段,N'i为Ni的新列名,字段V的值根据新列重新对照分布。
参数:
|
A |
序表/排列。 |
|
g |
分组字段/表达式。 |
|
G |
结果集中的字段名,缺省为g。 |
|
F |
A中的字段名称。 |
|
V |
A中的字段名称。 |
|
Ni |
F的字段值,可省略,缺省为F中所有不重复字段值。 |
|
N'i |
新列字段名,缺省为Ni。 |
选项:
|
@r |
将序表/排列进行列转行操作。 其中Ni为字段名,转换后作为字段F的值,有参数N'i时,N'i将代替Ni作为F的字段值;原Ni字段的值作为新列V的列数据。 Ni缺省值为A中除g,…以外的所有字段名称。 |
|
@s(g:G,…;F,f(V);Ni:N'i,…) |
f可以为聚合函数:sum/count/max/min/avg,支持~.f()的写法,~表示引用当前组;有N'i且 Ni省略时表示聚合其它未进行聚合的Ni中的V。 |
返回值:
序表
示例:
行转列:
|
|
A |
|
|
1 |
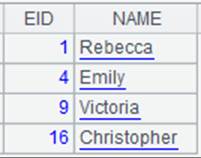
=demo.query("select * from SCORES") |
返回序表:
。。。
|
|
2 |
=A1.pivot(CLASS:ClassNew,STUDENTID:StudentID;SUBJECT,SCORE;"English":"new_English","Math","PE") |
行转列操作,将A1按照CLASS与STUDENTID分组,并将结果集中CLASS列的列名设置为ClassNew,STUDENTID列的列名设置为StudentID,然后将SUBJECT的字段值English、Math、PE作为新的列字段,其中English列字段名改为ENGLISH;最后SCORE的列值根据新列重新分布数据:
|
|
3 |
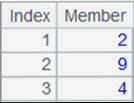
=A1.pivot(CLASS,STUDENTID;SUBJECT,SCORE;"English","Math") |
省略参数G及N'i ,结果集中的列名称分别使用g及Ni :
|
|
4 |
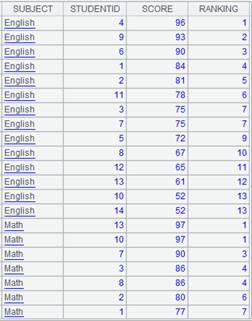
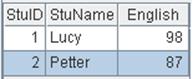
=A1.pivot(CLASS,STUDENTID;SUBJECT,SCORE) |
省略Ni,缺省使用SUBJECT中的所有不重复字段值:
|



列转行:
|
|
A |
|
|
1 |
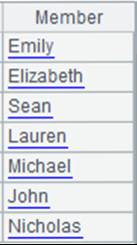
=demo.query("select * from SCORES") |
|
|
2 |
=A1.pivot(CLASS:ClassNew,STUDENTID;SUBJECT,SCORE;"English":"new_English","Math","PE") |
返回序表如下:
|
|
3 |
=A2.pivot@r(ClassNew:CLASS,STUDENTID;SUBJECT,SCORE;new_English:"English",Math,PE) |
对A2进行列转行操作,将列名English、Math和PE作为SUBJECT的字段值,原字段ENGLISH、Math和PE对应的数据值作为SCORE列的列数据,CLASS为ClassNew列的新列名:
|
|
4 |
=A1.pivot(CLASS,STUDENTID;SUBJECT,SCORE) |
返回序表如下:
|
|
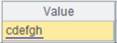
5 |
=A4.pivot@r(CLASS,STUDENTID;SUBJECT,SCORE) |
对A4进行列转行操作,省略Ni,缺省使用除CLASS,STUDENTID以外的所有字段名称:
|

使用@s选项,转换时使用聚合函数:
|
|
A |
|
|
1 |
=demo.query("select * from employee") |
返回序表如下:
|
|
2 |
=A1.pivot@s(DEPT;GENDER,avg(SALARY);"F":"female","M":"male") |
行转列操作,每组中将F、M的SALARY平均值作为新列的值,新列名分别为female和male:
|
|
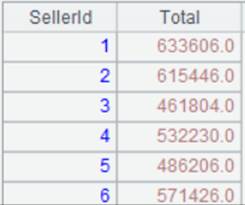
3 |
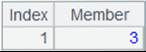
=A1.pivot@s(DEPT;GENDER,max(SALARY);"F":"female",:"other") |
省略一个Ni,表示对除F之外的所有SALARY列值里取最大值:
|
|
4 |
在所有字段里取最大值:
|
|
|
5 |
=A1.pivot@s(DEPT;GENDER,~.(NAME).concat@c()) |
使用~表示引用当前组,将A1按照DEPT分组后,将各组中的NAME值用逗号作为分隔符连接成字符串,作为F、M列的值:
|