nodes()
本章节介绍nodes()函数的用法。
P.nodes()
描述:
递归查询在外键中引用到指定记录的数据。
P.nodes(F,r,n)
备注:
在排列P中,递归查找所有在外键F中引用到记录r的记录,返回r的子节点记录。
记录r可以看作是根节点,其下层记录可以统称为r的子节点,当其下层不再有记录,则可称为叶子节点,反之下层仍有记录则称为枝干节点。
若r记录在排列P中不存在,结果返回NULL。参数n表示最大递归深度,缺省为1000。
参数:
|
P |
排列。 |
|
F |
字段名称。 |
|
r |
记录。 |
|
n |
数值。 |
选项:
|
@d |
返回叶子层的节点。 |
|
@p |
返回子节点及子节点到根节点的引用层次。 |
返回值:
序列
示例:
|
|
A |
|
|
1 |
|
|
|
2 |
>A1.switch(mgrid,A1:empid) |
|
|
3 |
=A1.nodes(mgrid,A1.select@1(name=="Diana"),5) |
根据mgrid外键引用,查询Diana的所有下属的记录,包括下属的下属的记录。 |
|
4 |
=A1.nodes@d(mgrid,A1.select@1(name=="Diana"),5) |
查询Diana的所有不是领导的下属的记录。 |
|
5 |
=A1.nodes@p(mgrid,A1.select@1(name=="Diana"),5) |
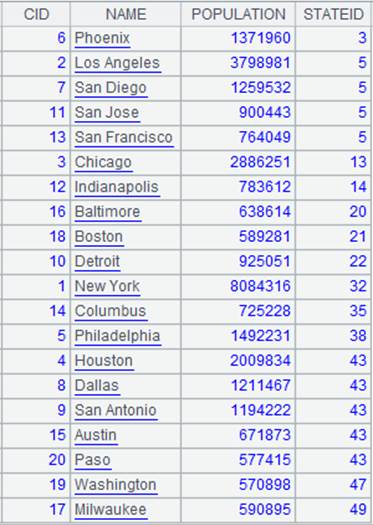
列出Diana的下属的关系。由此看出Diana是empid=7的领导,而empid=7为empid=14的上司。 |
x.nodes@r(Fi,...)
描述:
多层递归展开指引字段。
语法:
x.nodes@r(Fi,...)
备注:
多层递归展开x中的指引字段。
x是单值,返回空序列;
x是记录,如果Fi,…都是单值,返回x组成的序列,否则返回x.Fi.nodes@r(Fi,... )|... ;
x是序列/排列,返回x.conj(~.nodes@r(Fi,...))。
Fi省略时遍历x的所有字段。
参数:
|
x |
单值/序列/记录。 |
|
Fi |
字段名称。 |
返回值:
序列
示例:
x为单值:
|
|
A |
|
|
1 |
=rand(10) |
返回10以内的随机值。 |
|
2 |
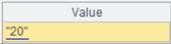
=A1.nodes@r() |
返回[] :
|
x为记录/序列:
|
|
A |
|
|
1 |
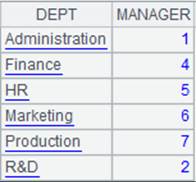
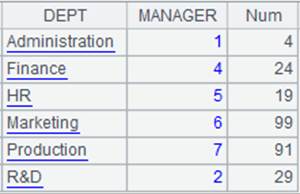
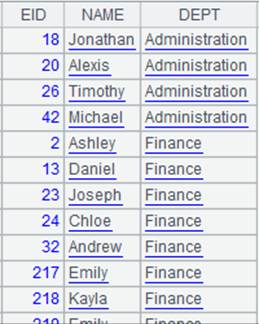
=demo.query("select * from DEPARTMENT").keys(DEPT) |
返回序表内容:
|
|
2 |
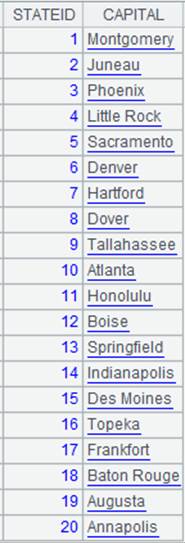
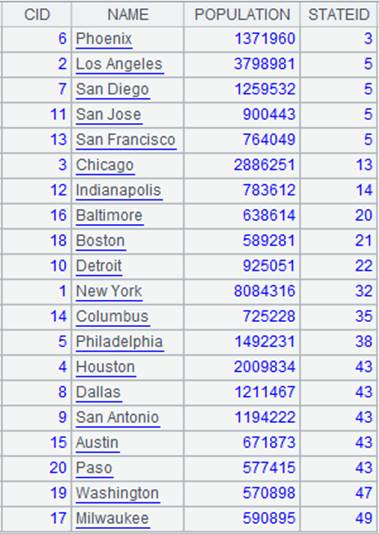
=demo.query("select NAME,ABBR from STATES").keys(NAME) |
返回序表内容:
|
|
3 |
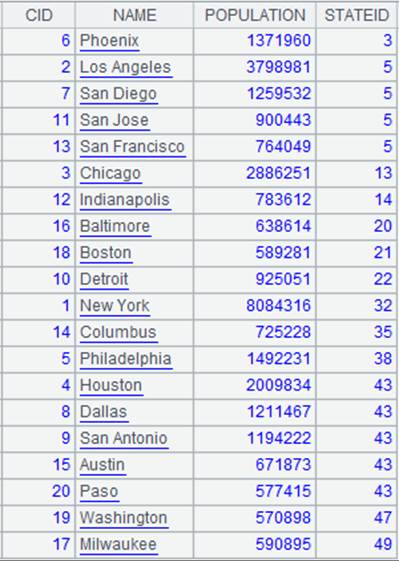
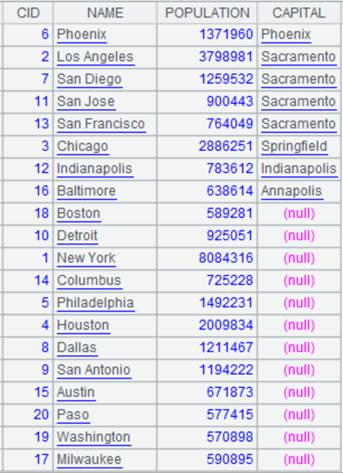
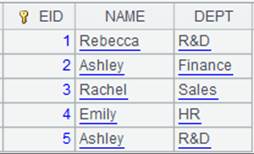
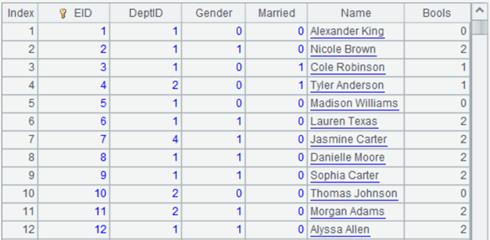
=demo.query("select top 10 EID,NAME,DEPT,STATE from EMPLOYEE") |
返回序表内容:
|
|
4 |
>A3.switch(DEPT,A1:DEPT) |
将A3中的DEPT字段值根据A1键值DEPT切换成指引字段。 |
|
5 |
>A3.switch(STATE,A2:NAME) |
将A3中的STATE字段值根据A2键值NAME切换成指引字段,A4、A5执行成功后A3格的序列内容如下:
|
|
6 |
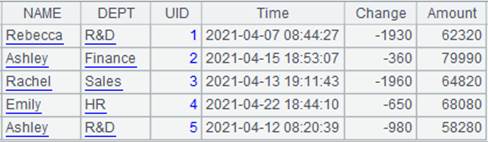
=A3.select@1(NAME=="Ashley") |
计算A3中NAME值为Ashley的第1条记录:
|
|
7 |
=A6.nodes@r(EID,NAME) |
获取A6中EID、NAME都为单值的记录,返回这些记录组成的序列:
|
|
8 |
=A6.nodes@r(DEPT,STATE) |
获取A6中DEPT、STATE都为单值的记录,返回这些记录组成的序列:
|
|
9 |
=A6.nodes@r(DEPT) |
获取A6中DEPT都为单值的记录,返回这些记录组成的序列:
|
|
10 |
=A3.nodes@r() |
Fi省略,遍历A3的所有字段,获取A3所有字段都为单值的记录,返回这些记录组成的序列:
|