new()
本章介绍new()函数的多种用法。
new ()
描述:
生成一条记录。
语法:
new(xi:Fi,…)
生成一条字段名称为Fi字段值为xi的记录。
参数:
|
xi |
字段值。 |
|
Fi |
字段名称。 |
选项:
|
@t |
返回成序表。 |
返回值:
记录/序表
示例:
|
|
A |
|
|
1 |
=new(1:ID,"ZHS":name) |
生成一条记录:
|
|
2 |
=new@t(1:ID,"ZHS":name) |
使用@t选项,生成只有一条记录的序表:
|
A.new( xi : Fi ,…)
描述:
计算序列后生成新序表。
语法:
A.new(xi:Fi,…)
备注:
对序列A计算表达式xi,生成一个记录数与A相同,且字段值为xi、字段名为Fi的新序表。
参数:
|
Fi |
结果序表的字段名,缺省用xi ,当xi为#i时使用原列名。 |
|
xi |
表达式,结果作为字段值,缺省为null,省略xi时,不能省略: Fi。 |
|
A |
序列。 |
选项:
|
@m |
并行计算提升性能。 |
|
@i |
有xi并且计算结果为空时,不生成该行记录。 |
|
@o |
A是纯序表时,未改变的旧列直接引用,不再新产生,对结果序表进行更新操作时,会同时更新A的内容。仅企业版适用。 |
|
@z |
逆向计算,仅适用于非纯序列。 |
返回值:
序表
示例:
Ø 从单个序表产生
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
=A1.new(EID:EmployeeID,NAME, #3:dept) |
直接产生新序表,如与A1字段名相同,可以省略Fi。 |
|
3 |
=A1.new(NAME,age(BIRTHDAY):AGE) |
计算字段值生成新序表。 |
|
4 |
=A1.new@m(NAME,age(BIRTHDAY):AGE) |
数据量大时提升性能。 |
|
5 |
=file("D:\\txt_files\\data1.txt").import@t() |
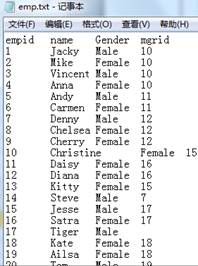
data1.txt中内容如下:
|
|
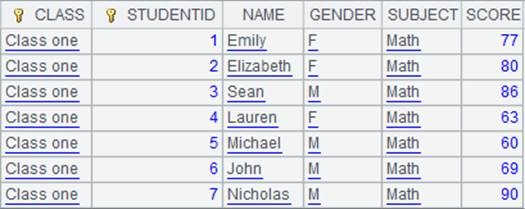
6 |
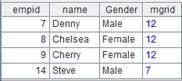
=A5.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
SCORE计算结果为空时,对应的该条记录不生成:
|
Ø A为纯序表时
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE").i() |
返回纯序表。 |
|
2 |
=A1.new@o(EID,NAME, #3:dept) |
|
|
3 |
=A2(1).NAME="aaa" |
修改列值时会同时修改源表的,执行后A2格结果如下:
此时A1格结果如下:
|

Ø 从同序的多个序表关联运算产生
|
|
A |
|
|
1 |
=create(Name,Chinese).record(["Jack",99,"Lucy",90]) |
|
|
2 |
=create(Name,Math).record(["Jack",89,"Lucy",96]) |
|
|
3 |
=A1.new(Name:Name,Chinese:Chinese,A2(#).Math:Math) |
通过A2(#)读取A2同位置的记录 |

Ø 逆向计算
|
|
A |
|
|
1 |
=demo.query("select * from SCORES ") |
返回序表:
|
|
2 |
=A1.new(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
循环函数中迭代运算,对有相同CLASS,STUDENTID值的SCORE值累积计算,结果作为F1列的值,返回的新序表如下:
|
|
3 |
=A1.new@z(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
使用@z选项,逆向计算:
|
相关概念:
ch.new()
描述:
管道中附加计算字段值动作后返回原管道。
语法:
ch.new(xi:Fi,…)
备注:
管道ch附加计算,对ch计算表达式xi,形成一个记录数与cs相同,且字段值为xi、字段名为Fi的新序表,返回原管道ch。
参数:
|
ch |
管道。 |
|
xi |
表达式,结果为字段值,省略则为null,省略xi时,不能省略: Fi。用#时表示用序号定位。 |
|
Fi |
ch的字段名,省略则用xi中解析出的标识符。 |
选项:
|
@i |
有xi并且计算结果为空时,不生成该行记录。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
返回游标。 |
|
2 |
=file("D:\\txt_files\\data1.txt").cursor@t() |
data1.txt中内容如下:
|
|
3 |
=channel() |
创建管道。 |
|
4 |
=channel() |
创建管道。 |
|
5 |
=A3.new(CLASS,#2:ID,SCORE+5:newScores) |
管道A3附加计算,#2:ID表示将A3中的第2个字段重命名为ID;对SCORE字段计算表达式SCORE+5后重命名列名为newScores,然后形成ID、CLASS和newScores列组成序表,返回原管道A3。 |
|
6 |
=A3.fetch() |
A3管道执行结果集函数,保留管道当前数据。 |
|
7 |
=A4.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
管道A4附加计算,使用@i选项,SCORE计算结果为空时,对应的该条记录不生成,返回原管道A4。 |
|
8 |
=A4.fetch() |
A4管道执行结果集函数,保留管道当前数据。 |
|
9 |
=A1.push(A3) |
将游标A1中的数据推送到管道A3,此时数据不会立即被推送到管道。 |
|
10 |
=A2.push(A4) |
将游标A2中的数据推送到管道A4,此时数据不会立即被推送到管道。 |
|
11 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道A3,然后管道执行计算并记录结果。 |
|
12 |
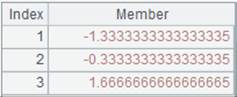
=A3.result() |
获取A3管道计算结果:
|
|
13 |
=A2.fetch() |
A2游标执行取数动作,此时数据才会被推送到管道A4,然后管道执行计算并记录结果。 |
|
14 |
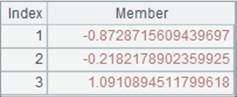
=A4.result() |
获取A4管道计算结果:
|
cs.new()
描述:
语法:
cs.new(xi:Fi,…)
备注:
游标cs附加计算,对cs计算表达式xi,生成一个记录数与cs相同,且字段值为xi、字段名为Fi 的新序表,然后将新序表返回到原游标cs中。
该函数属于延迟计算函数。
参数:
|
cs |
游标。 |
|
xi |
表达式,结果为字段值,省略则为null;省略xi时,不能省略: Fi。用#时表示用序号定位。 |
|
Fi |
cs的字段名,省略则用xi中解析出的标识符。 |
选项:
|
@i |
有xi并且计算结果为空时,不生成该行记录。 |
返回值:
游标
示例:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 5 * from SCORES where SCORE<60") |
|
|
2 |
=A1.new(#2:ID,CLASS,SCORE+5:newScores) |
A1游标中附加表达式计算动作,#2:ID表示将游标A1中的第2个字段重命名为ID;对SCORE字段计算表达式SCORE+5后重命名列名为newScores,然后将ID、CLASS和newScores列组成序表返回到游标A1中。 |
|
3 |
=A1.fetch() |
读取A1游标执行A2计算后的数据(数据量较大时建议分批读取):
|
使用@i选项:
|
|
A |
|
|
1 |
data1.txt中内容如下:
|
|
|
2 |
=A1.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
使用@i选项,SCORE计算结果为空时,对应的该条记录不生成。 |
|
3 |
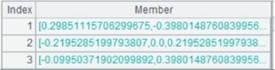
=A1.fetch() |
读取A1游标执行A2计算后的数据:
|
T.new( A/cs:K…,x:C,…;wi )
描述:
根据组表的键(/维)与序表/游标的字段对应,返回由指定字段组成的序表/游标。
语法:
T.new(A/cs:K…,x:C,…;wi)
备注:
组表T为主表,序表A/游标cs为子表,T与A/cs是一对多的关系,按T的键(/维)字段与A/cs(从头开始)的字段对应,返回由x:C字段组成的序表/游标。A/cs对前面字段有序,且要求A/cs前面字段与T的键(/维)同序。
参数为A时返回序表,为cs时返回游标/多路游标。
返回结果集向T对齐并设置维/键,支持对子表字段做聚合运算。
参数:
|
T |
组表。 |
|
A/cs |
序表/游标。 |
|
K |
A/cs的字段,有K时用K与T的键(/维)对应,K缺省用A/cs前面字段。多个K时用 : 隔开。 |
|
x |
字段表达式/聚合函数,支持count/sum/max/min/avg。 |
|
C |
列别名,可省略。 |
|
wi |
T的过滤条件,缺省读取全集,多个条件之间用逗号隔开,为AND关系。除常规的过滤表达式外,过滤条件中还支持如下几种写法,其中K表示实表T中的非键字段: 1.K=w w通常使用表达式Ti.find(K)或Ti.pfind(K),Ti为序表,w为null或false时将被过滤掉;当w为表达式Ti.find(K)且被选出字段C,...中包含K时,K将被赋值为Ti的指引字段; 当w为表达式Ti.pfind(K)且被选出字段C,...中包含K时,K将被赋值为K在Ti 中的序号。 2.(K1=w1,…Ki=wi,w) Ki=wi为赋值表达式,参数wi通常可以使用表达式Ti.find(Ki)或Ti.pfind(K),Ti为序表;当wi为表达式Ti.find(Ki)且被选出字段C,...中包含Ki时,.Ki将被赋值为Ti的指引字段; 当wi为表达式Ti.pfind(Ki)且被选出字段C,...中包含Ki时,Ki将被赋值为Ki在Ti 中的序号。 w为过滤表达式, w中可引用Ki。 3.K:Ti Ti为序表,用实表中Ki的值与Ti的键值作对比,匹配不上的将被过滤掉;当选出字段C,...中包含K时,K将被赋值为Ti的指引字段。 4.K:Ti:null 符合K:Ti的记录将被过滤掉。 |
选项:
|
@r |
复制主表记录,返回结果集向A/cs对齐。 |
返回值:
序表/游标
|
|
A |
|
|
1 |
=connect("demo").cursor("select STATEID,CAPITAL from STATECAPITAL") |
返回游标。 |
|
2 |
=file("spec-new.ctx") |
|
|
3 |
=A2.create@y(#STATEID,CAPITAL) |
创建STATEID为键的组表。 |
|
4 |
=A3.append@i(A1) |
将A1游标中的数据追加到组表中,组表数据内容如下:
|
|
5 |
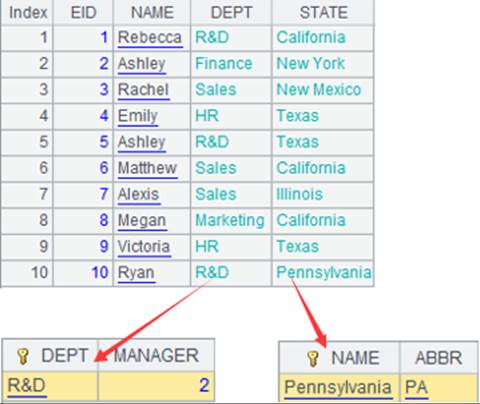
=demo.query("select STATEID ,CID,NAME,POPULATION from CITIES").sort(STATEID) |
返回序表:
|
|
6 |
=A4.new(A5:STATEID,CAPITAL,sum(POPULATION):STA_POP) |
A4为主表,A5为子表,按组表的键STATEID与序表的STATEID字段对应,返回由CAPITAL ,STA_POP组成的序表,STA_POP内容为子表字段POPULATION聚合计算的结果:
|
|
7 |
=A4.new(A5,CAPITAL,sum(POPULATION):STA_POP) |
省略参数K,按组表的键与序表的前面字段即STATEID对应,返回内容同A6。 |
|
8 |
=A4.new@r(A5:STATEID,CAPITAL,NAME,POPULATION) |
使用@r选项,复制主表记录,结果集按子表对齐:
|
|
9 |
=A4.new@r(A5:STATEID,STATEID,CAPITAL,NAME,POPULATION;STATEID<3,left(CAPITAL,1)=="M") |
关联计算时对A4表的数据进行过滤,过滤条件为STATEID<3并且CAPITAL的首字母为M:
|
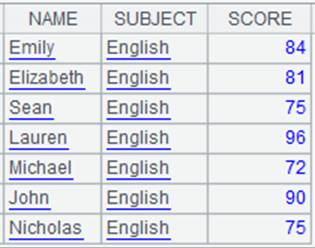

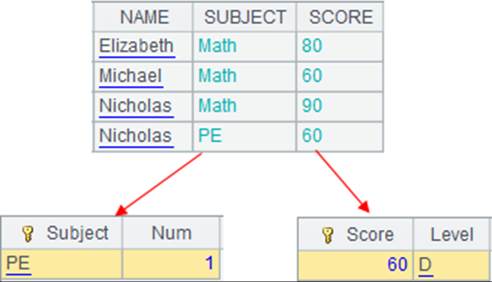
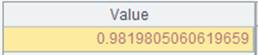
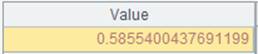
多个K时:
|
|
A |
|
|
1 |
=file("stu.ctx").open() |
打开组表,组表数据内容如下:
|
|
2 |
=file("sco.txt").import@t() |
返回序表,内容如下:
|
|
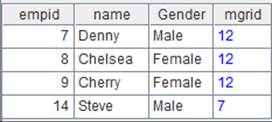
3 |
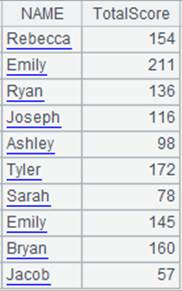
=A1.new(A2:Class:StudentID,NAME,sum(SCORE):TotalScore) |
A1为主表,A2为子表,按组表的键与序表的Class、StudentID字段对应,返回由NAME ,TotalScore组成的序表,TotalScore内容为子表字段SCORE聚合计算的结果:
|
|
4 |
使用@r选项,复制主表记录,结果集按子表对齐:
|



多种过滤方式:
|
|
A |
|
|
1 |
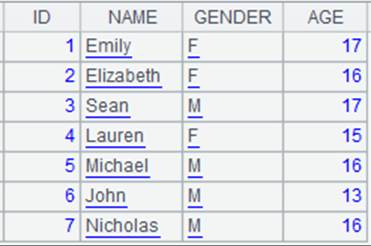
=demo.cursor("select * from STUDENTS") |
游标中数据内容如下:
|
|
2 |
=file("students.ctx") |
|
|
3 |
=A2.create@y(#ID,NAME,GENDER,AGE) |
创建组表。 |
|
4 |
=A3.append@i(A1) |
将A1游标中的数据追加到组表基表中。 |
|
5 |
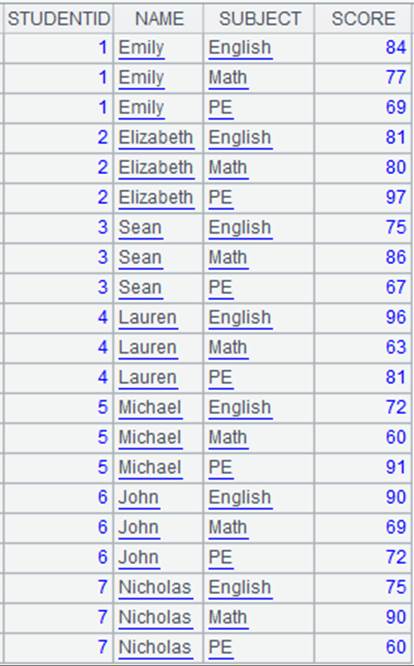
=demo.query("select top 12 STUDENTID,SUBJECT,SCORE from SCORES") |
返回序表:
|
|
6 |
=A3.new(A5:STUDENTID,ID,NAME,AGE) |
将组表的键值与序表字段对应,取出组表字段,返回序表:
|
|
7 |
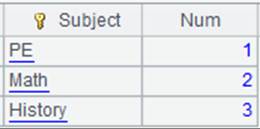
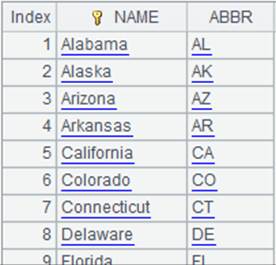
=create(NAME,Num).record(["Emily",12,"Lauren",45]).keys(NAME) |
生成NAME为键的序表:
|
|
8 |
=A3.new(A5:STUDENTID,ID,NAME,AGE;NAME=A7.find(NAME)) |
使用K=w过滤方式,w是Ti.find(K),实表中使NAME=A7.find(NAME)计算结果为null或false的记录过滤掉;NAME为选出字段,赋值为序表A7的指引字段:
|
|
9 |
=A3.new(A5:STUDENTID,ID,NAME;NAME=A7.pfind(NAME)) |
使用K=w过滤方式,w是Ti.pfind(K),实表中使NAME=A7.pfind(NAME)计算结果为null或false的记录过滤掉;NAME为选出字段,赋值为NAME在序表A7的序号:
|
|
10 |
=A3.new(A5:STUDENTID,ID,NAME;NAME:A7) |
使用K:Ti过滤方式,用实表中NAME的值与序表的键值作对比,匹配不上的将被过滤掉:
|
|
11 |
=A3.new(A5:STUDENTID,ID,GENDER;NAME:A7) |
K不被选出的情况,NAME不是选出字段,仅过滤:
|
|
12 |
=A3.new(A5:STUDENTID,ID,NAME;NAME:A7:null) |
使用K:Ti:null过滤方式,用实表中NAME的值与序表的键值作对比,可以匹配上的将被过滤掉:
|
|
13 |
=create(Age,Chinese_zodiac_sign).record([14,"tiger",15,"ox",16,"rat"]).keys(Age) |
返回键为AGE的序表。
|
|
14 |
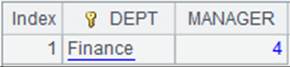
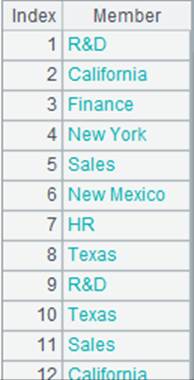
=A3.new(A5:STUDENTID,ID,NAME,AGE;(AGE=A13.find(AGE), NAME=A7.find(NAME),AGE!=null&&NAME!=null)) |
使用(K1=w1,…Ki=wi,w)过滤方式,返回符合所有条件的记录:
|






T.new()
描述:
虚表中定义计算字段值操作后返回新虚表。
语法:
备注:
虚表T中定义计算,对T计算表达式xi,生成一个记录数与T相同,且字段值为xi、字段名为Fi的新虚表。
参数:
|
T |
虚表。 |
|
xi |
表达式,结果为字段值,省略则为null;省略xi时,不能省略: Fi。用#时表示用序号定位。 |
|
Fi |
新虚表的字段名,省略则用xi中解析出的标识符。 |
选项:
|
@i |
有xi并且计算结果为空时,不生成该行记录。 |
返回值:
虚表
示例:
|
|
A |
|
|
1 |
=score=connect("demo").query("select top 5 * from SCORES where SCORE<60") |
|
|
2 |
=create(var).record([score]) |
|
|
3 |
=pseudo(A2) |
定义内存虚表。 |
|
4 |
=A3.import() |
读取A3虚表数据:
|
|
5 |
=A3.new(#2:ID,SUBJECT,SCORE+5:newScores) |
A3虚表中定义计算,#2:ID表示将虚表A3中的第2个字段重命名为ID;对SCORE字段计算表达式SCORE+5后重命名列名为newScores,然后将ID、SUBJECT和newScores列组成新的虚表。 |
|
6 |
=A5.import() |
读取A5虚表中的数据:
|


使用@i选项:
|
|
A |
|
|
1 |
=connect("demo").query("select * from DEPT") |
|
|
2 |
=create(var).record([A1]) |
|
|
3 |
=pseudo(A2) |
定义虚表。 |
|
4 |
=A3.import() |
读取A3虚表数据:
|
|
5 |
=A3.new@i(DEPTID,DEPTNAME,FATHER:father) |
使用@i选项,FATHER计算结果为空时,对应的该条记录不生成。 |
|
6 |
=A5.import() |
读取A5虚表中的数据:
|