
简单 SQL
本章介绍简单SQL的用法。
概念:
从数据文件中查询数据;数据文件可以直接以【文件名.后缀名】作为表名来使用,使用的语法类似于从数据库中查询用的SQL语句,称为简单SQL。数据文件中内容可以类似普通序表一样用来查询。
目前支持的数据文件类型包括:txt、csv、xlsx、xls、btx(集文件)。数据文件均认为有标题,查询数据文件时既可以用相对路径也可以用绝对路径,相对路径相对于集算器主目录。
简单SQL与普通SQL类似, 可用于db.query(sql)和$(db)sql函数中,不同的是,普通SQL是从数据库中查询,要指定连接的数据源名称db,而简单SQL是从文件系统中查询内容的,无需设置数据源名称,数据源参数db直接置空即可,写法为:connect().query(sql)/$()sql。
简单SQL语法:
|
with T as (x) |
用集算器脚本定义数据文件中的表,x可返回序表或游标。 |
|
select x F,… |
从表中选取数据,x为字段或表达式,F为字段别名。 |
|
_file |
如果from文件,该字段表示文件名,其它from时无定义。 |
|
_ext |
扩展名。 |
|
_size |
文件大小。 |
|
_date |
文件最后修改时间。 |
|
* |
*只包含文件内的字段不含文件属性。 |
|
.from T T’ |
使用定义过的表T,T’为表别名,T’可省略。 |
|
from fn T |
直接用文件fn作为表T,文件类型包括: txt、csv、xls、xlsx、btx(集文件),按游标处理;文件均认为有标题,fn文件可以用相对路径或绝对路径,相对路径相对于集算器主目录。 文件名中允许使用通配符,*匹配0个或多个字符,?匹配单个字符;可以对应多个文件,认为是多个同结构的数据文件做并集,暂不支持访问子目录。 |
|
from {x} |
x为当前网格内可执行的表达式,且必须是返回结果为序表或游标的集算器表达式。 |
|
from v |
v是当前网络内的变量名。 |
|
as |
别名前可以用as。 |
|
where |
条件过滤。 |
|
join 、left join、full join |
关联,有join时认为全内存,使用xjoin实现。 |
|
group by |
分组,用groups,认为结果集可内存化。 |
|
group by n |
按select中第n个表达式分组,n只能是常数。 |
|
having |
分组过滤。 |
|
order by |
排序,默认升序。 |
|
order by n |
按select中第n个表达式排序,n只能是常数。 |
|
distinct |
同SQL,只能单表。 |
|
and、 or 、not 、 in、 is null、 case when else end |
使用SQL风格,in只能使用常数集合,暂不支持子查询。
|
|
between |
介于两个值之间的数据范围,例如f1 between 1 and 3,相当于 f1 >= 1 && f1 <= 3,暂不支持子查询。 |
|
like |
模糊查询,支持如下几种通配符: % 多个字符; _ 单个字符; 暂不支持子查询。 |
|
into fn |
将结果集写入到文件中,根据扩展名决定文件类型,目前支持的扩展名包括txt、csv、btx。 文件已存在则判断结构相同后追加,结构不同则报错。 fn文件可以用相对路径或绝对路径,相对路径相对于集算器主目录。 |
|
into ${x}.ext |
可在文件名中使用有宏的串,将计算出x拼入文件名。 |
|
?、?i |
SQL中的参数,i代表第i个参数。 |
|
聚合函数 |
sum、count、 max、 min、avg、distinct、count(distinct) 。 |
|
集合运算 |
union、union all、intersect、minus。 |
|
子查询 |
from之外涉及的子查询均认为全内存,可支持无参数的子查询。 |
|
计算函数 |
在sqltranslate函数参照表中定义(无数据库名称,对应SPL表达式),暂不支持窗口函数。 |
|
top n |
取前n条记录。 |
|
limit n offset m |
跳过m条后取n条记录。 |
|
其他函数 |
符合语法规则的集算器函数。 |
|
字符串函数: |
|
|
LOWER(str) |
转成小写。 |
|
UPPER(str) |
转成大写。 |
|
ISDIGIT(str) |
判定str是否全由数字构成。 |
|
ISALPHA(str) |
判定str是否全由字母构成。 |
|
LTRIM(str) |
删除前导空白。 |
|
RTRIM(str) |
删除后缀空白。 |
|
TRIM(str) |
删除两端空白。 |
|
SUBSTR(str,start,len)
SUBSTR(str,start) |
子串。 |
|
LEN(str) |
串长。 |
|
INDEXOF(sub,str[,start]) |
子串的位置。 |
|
IPOS(str1,str2[,n]) |
在字符串str1中,从左边第n位开始查找子串str2,返回str2的位置。n缺省为1。大小写不敏感。 |
|
GETSUBS(str1,str2[,n]) |
在字符串str1中,从左边开始查找第n个字符串str2,找到后返回str2位置后面的串。n缺省为1。 |
|
IGETSUBS (str1,str2[,n]) |
在字符串str1中,从左边开始查找第n个字符串str2,找到后返回str2位置后面的串。n缺省为1。大小写不敏感。 |
|
LEFT(str,len) |
str中最左边len个字符。 |
|
RIGHT(str,len) |
str中最右边len个字符。 |
|
CONCAT(str1,str2) |
连接2个字符串。 |
|
CONCAT(s1,s2,…) |
连接多个字符串。 |
|
CONCAT_WS(d,str1,str2,…) |
用分隔符d连接多个字符串。 |
|
REPLACE(str,sub,rplc) |
将str中的sub替换成rplc。 |
|
数值函数: |
|
|
ABS(x) |
求绝对值。 |
|
ACOS(x) |
求反余弦。 |
|
ASIN(x) |
求反正弦。 |
|
ATAN(x) |
求反正切。 |
|
ATAN2(x,y) |
求反正切。 |
|
CEIL(x) |
求大于等于x的最小整数。 |
|
CEIL(x,n) |
根据精度n对x向上取整; n缺省为0,n>0 保留 n 位小数,n=0 取整到个位,n<0 按十位、百位、千位等整数位向上取整。 |
|
COS(x) |
求余弦。 |
|
EXP(x) |
求e的x次幂。 |
|
FLOOR(x) |
求小于等于x的最大整数。 |
|
FLOOR(x,n) |
根据精度n对x向下取整; n缺省为0,n>0 保留 n 位小数,n=0 取整到个位,n<0 按十位、百位、千位等整数位向下取整。 |
|
LN(x) |
求自然对数。 |
|
LOG10(x) |
求以10为底的对数。 |
|
MOD(x,m) |
x模m。 |
|
POWER(x,y) |
x的y次幂。 |
|
ROUND(x,n) |
四舍五入。 |
|
SIGN(x) |
求符号。 |
|
SIN(x) |
求正弦。 |
|
SQRT(x) |
平方根。 |
|
TAN(x) |
正切。 |
|
TRUNC(x,n) |
截断。 |
|
RAND(seed) |
随机数。 |
|
PI() |
计算圆周率。 |
|
时间日期函数: |
|
|
YEAR(d) |
取年。 |
|
MONTH(d) |
取月。 |
|
DAY(d) |
取天。 |
|
HOUR(d) |
取小时。 |
|
MINUTE(d) |
取分钟。 |
|
SECOND(d) |
取秒。 |
|
QUARTER(d) |
取季度。 |
|
TODAY() |
今天。 |
|
NOW() |
当前时间。 |
|
ADDYEARS(d,n) |
增加年数。 |
|
ADDMONTHS(d, n) |
增加月数。 |
|
ADDDAYS(d, n) |
增加天数。 |
|
ADDHOURS(d, n) |
增加小时数。 |
|
ADDMINUTES(d, n) |
增加分钟数。 |
|
ADDSECONDS(d, n) |
增加秒数。 |
|
DAYOFYEAR(d) |
当年中第几天。 |
|
DAYOFWEEK(d) |
星期几,1表示星期日。 |
|
WEEKOFYEAR(d) |
当年中第几星期。 |
|
YEARSDIFF(d1,d2) |
计算两个日期相差年数。 |
|
MONTHSDIFF(d1,d2) |
计算两个日期相差月数。 |
|
DAYSDIFF(d1,d2) |
计算两个日期相差天数。 |
|
HOURSDIFF(d1,d2) |
计算两个日期相差小时数。 |
|
MINUTESDIFF(d1,d2) |
计算两个日期相差分钟数。 |
|
SECONDSDIFF(d1,d2) |
计算两个日期相差秒数。 |
|
TRUNCHOUR(d) |
截断到小时。 |
|
TRUNCMINUTE(d) |
截断到分钟。 |
|
TRUNCSECOND(d) |
截断到秒。 |
|
MONTHSTART(d) |
当月首日。 |
|
MONTHEND(d) |
当月末日。 |
|
WEEKSTART(d) |
当周首日,周一为每周第一天。 |
|
WEEKEND(d) |
当周末日,周一为每周第一天。 |
|
QUARTERSTART(d) |
当季首日。 |
|
QUARTEREND(d) |
当季末日。 |
|
YEARSTART(d) |
当年首日。 |
|
YEAREND(d) |
当年末日。 |
|
MONTHDAYS(d) |
当月日数。 |
|
QUARTERDAYS(d) |
当季日数。 |
|
YEARDAYS(d) |
当年日数。 |
|
ITX(s) |
根据时间分量生成时间区间常数,s表示秒。 |
|
ITX (null,d) |
根据时间分量生成时间区间常数,d表示日,第一个参数值固定为null。 |
|
ITX(null,d,m) |
根据时间分量生成时间区间常数,d表示日,m表示月,第一个参数值固定为null。 |
|
ADDX(t,k) |
日期加法。 k可以ITX()返回的时间区间常数。 t是日期/日期时间且 k是数值时,k 表示日。 t / k是其它数据类型则正常做加法。 |
|
SUBX(t1,t2) |
日期减法。 t1是日期/日期时间且 t2是数值时,t2 表示日。 t1 / t2是其它数据类型则正常做减法。 |
|
CMPX(it1,it2) |
日期比较。 it1 / it2 可以是日期/时间/日期时间/时间区间常数/数值。 |
|
转换函数: |
|
|
ASCII(str) |
串中最左边字符的ASCII码。 |
|
CHR(n) |
整数n转换成字符。 |
|
INT(x) |
字符串或数值转成整数。 |
|
DECIMAL(x,len,scale) |
字符串或数值转成数值。 |
|
TIMESTAMP(d[,str]) |
将d根据格式串str转换成日期时间类型。str缺省为yyyy-MM-dd HH:mm:ss。 |
|
NUMTOCHAR(d) |
数值转成字符串。 |
|
DATETOCHAR(date) |
将日期转化成yyyy-MM-dd HH:mm:ss格式串。 |
|
DATE(sd[,fd]) |
将sd根据格式串fd转换成日期类型。fd缺省为yyyy-MM-dd 。 |
|
DATE(y,m,d) |
将整数y,m,d转换成日期型数据,失败则返回null。 |
|
TIME(sdt[,fd]) |
将sdt根据格式串fd转换成时间类型。fd缺省为HH:mm:ss。 |
|
TIME(h,m,s) |
将整数h,m,s转换成时间型数据。 |
|
CAST(x,y) |
将x转换为数据类型y。 |
|
STRING(exp[,format][,loc]) |
将 exp 转为字符串类型,可通过 format 格式化输出、loc 指定语言地区。参数format 、loc 可省略。 |
|
CHN(n) |
将数字n转为中文数字写法。 |
|
其他: |
|
|
NULLIF(x1,x2) |
若x1等于x2返回null,否则返回x1。 |
|
COALESCE(x1,…) |
返回第一个非null的参数。 |
|
CASE(when1,then1,…[,else]) |
when=true则返回相应的then,否则返回else。 |
注意:
在简单SQL语句中,当字段名称、数据文件路径、数据文件名称、别名等位置中的字符串,在使用特殊标识符或者首字母非下划线和字母时,需要使用双引号引起来,否则会报错,并且使用双引号时请注意判断是否需要转义。
示例:
在db.query(sql)中的用法:
|
|
A |
|
|
1 |
=connect() |
|
|
2 |
=A1.query("select * from Persons.txt") |
|
|
3 |
=A1.query("select * from D:/Orders.txt") |
|
|
4 |
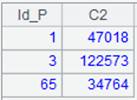
=A1.query("select Id_P, sum(OrderNo) from Orders.csv group by 1 ") |
按照Id_P分组:
|
|
5 |
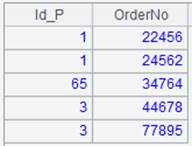
=A1.query("select Id_P, OrderNo from Orders.csv order by 2 ") |
按照OrderNo字段排序,默认升序:
|
|
6 |
=A1.query("select * into p1.txt from Persons.csv ") |
将查询的结果集写入到p1.txt文件中。 |
|
7 |
=A1.query("select * from Persons.csv where Id_P=? or Id_P>? ",2,2) |
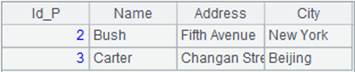
查询Id_P大于2或等于2的数据:
|
|
8 |
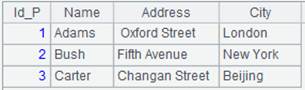
=A1.query("select * from Persons.csv where Id_P=?1 or Id_P>?2 ",2,2) |
查询Id_P大于2或等于2的数据,结果同上,?i表示第i个参数。
|
|
9 |
=A1.query("with persons as (file(\"D:/Persons.btx\").import@b()) select * from persons ") |
从Persons.btx文件中查询的结果集 命名为persons,然后再从persons中查询数据,对于大批量的SQL数据,起到优化的作用。
|
|
10 |
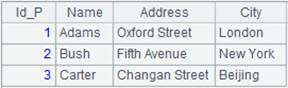
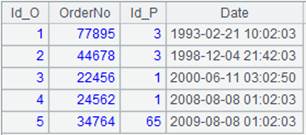
=A1.query("select * from Persons.txt P join Orders.txt O on P.Id_P = O.Id_P ") |
多表联合查询:
|
|
11 |
=A1.query("select distinct _file,_ext,_size,_date from cities.txt") |
去重复值查询,获取数据文件的文件名、扩展名、文件大小、文件最后修改时间:
|
|
12 |
=A1.query("select CASE id_P when 1 then 'one' when 2 then 'tow' else 'other' end from p1.txt") |
使用case when语句。 |
|
13 |
=A1.query("select * from Persons.btx where city like 'N%' ") |
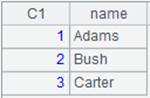
使用like语法,查找文件Persons.btx中字段city首字母为N的记录:
|
|
14 |
=A1.query("select * from Persons.btx where Name like '_a_t%' ") |
使用like语法,查找文件Persons.btx中字段Name第二个字母为a第四个字母为t的记录:
|



from {x}的用法:
|
|
A |
|
|
1 |
=file("score1.txt") |
|
|
2 |
=file("score2.txt") |
|
|
3 |
=A1.cursor@t() |
|
|
4 |
=A2.cursor@t() |
|
|
5 |
=[A3, A4].cursor@t() |
|
|
6 |
=connect().query("select CLASS, max(SCORE) avg_score from {A5} where SUBJECT='math' group by CLASS") |
from {x} 语法,此处x为游标。 |
在$()sql中的用法:
|
|
A |
|
|
1 |
$()select * from Persons.txt |
查询数据文件Persons.txt中的数据,结果返回序表。 |
|
2 |
$select * from D:/Orders.txt |
使用绝对路径方式查询,结果返回序表。 |
|
3 |
$select * from Persons.csv where Id_P=? or Id_P>?;2,2 |
查询Id_P大于2或等于2的数据。 |
|
4 |
$select * from Persons.txt P join Orders.txt O on P.Id_P = O.Id_P |
多表联合查询。 |
|
5 |
=arg1=create(id,num).record([1,11,2,22]) |
设置网格变量。 |
|
6 |
$select * from arg1 |
from v语法,arg1是当前网络内的变量名。 |
into的用法:
|
|
A |
|
|
1 |
=create(id,num).record([1,11,2,22]) |
|
|
2 |
$select * into Num.txt from {A1} |
将A1序表中的数据写入到文件Num.txt中。 |
|
3 |
>fname="Num_"+string(date(now())) |
|
|
4 |
$select * into {fname}.txt from {A1} |
将A1序表中的数据写入到数据文件中,fname为宏,最终生成Num_yyyy-mm-dd.txt名称的文件,yyyy-mm-dd为当前日期。 |