
index()
本章介绍index()函数的多种用法。
T.index()
描述:
为序表建立索引表。
语法:
T.index(n)
备注:
为序表T建立长为n的索引表, n为0或序表重置键时将清除索引表。
建立索引时要求T的主键唯一,否则报错。
参数:
|
T |
有键的序表。 |
|
n |
索引长度,缺省使用默认的索引长度。 |
选项:
|
@s |
T的基本键是排号键时建立成多层树状索引,忽略n。 |
|
@n |
为序表建立序号索引,忽略参数n; T中无序号键时直接用记录序号。 序号索引用于外键序号化,即事实表的外键值对应维表记录的序号,使用P.join()、P.switch()等函数做表关联计算时,关联表达式中的序号键可省略。 |
|
@m |
并行建立索引。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,SALARY from EMPLOYEE where EID<4") |
|
|
2 |
=A1.keys(EID) |
设置A1的键为EID。 |
|
3 |
=A1.index(10) |
为序表建立长度为10的索引表。 |
|
4 |
=A1.keys(EID,NAME) |
A1序表重置键,索引表被清除。 |
建立多树状索引:
|
|
A |
|
|
1 |
=3.new(k(~:2):id,~*~:num) |
创建序表,其中id为排号类型。 |
|
2 |
=A1.keys(id) |
设置A1的键为id:
|
|
3 |
=A2.index@s() |
A1的基本键为排号,使用@s选项,建立多层树状索引。 |
|
4 |
=A2.index(0) |
参数为0,清除索引表。 |
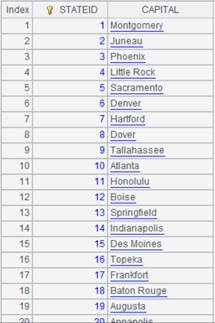
建立序号索引:
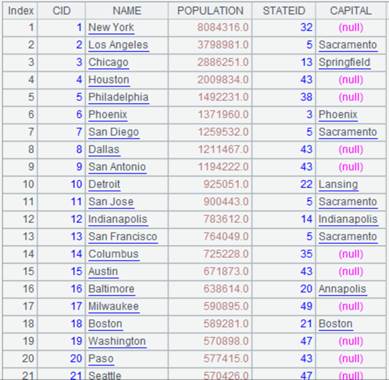
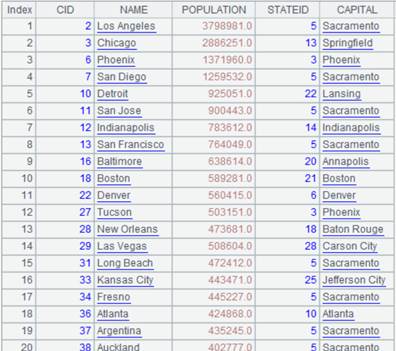
相关概念:
T.index(n)
描述:
语法:
T.index(n)
备注:
为内表T创建长度为n的索引表,n为0或内表重置键时将清除索引表。
建立索引时要求T的主键唯一,否则报错。
参数:
|
T |
主键唯一的内表。 |
|
n |
索引长度,缺省使用默认的索引长度。 |
选项:
|
@m |
并行建立索引。 |
|
@n |
建立序号索引,忽略参数n。T中无序号键时直接用记录序号。 |
|
@s |
T的基本键是排号类型时建立成多层树状索引,忽略参数n。 |
返回值:
内表
示例:
为内表建立索引:
|
|
A |
|
|
1 |
=file("ei.ctx") |
|
|
2 |
=A1.create@y(#EID,NAME,DEPT) |
创建组表基表,EID为键。 |
|
3 |
=demo.cursor("select EID,NAME,DEPT from employee") |
|
|
4 |
=A2.append@i(A3) |
将A3游标中的数据追加到组表中。 |
|
5 |
=A4.memory() |
用组表的实表生成内表,内表继承实表的键。 |
|
6 |
=A5.index(10) |
为内表建立长度为10的索引。 |
|
7 |
=A5.index(0) |
参数为0,清除内表中的索引表。 |
为内表建立多层树状索引:
|
|
A |
|
|
1 |
=3.new(k(~:2):id,~*~:num) |
创建序表。 |
|
2 |
=A1.keys(id) |
设置序表的键为id。 |
|
3 |
=A2.memory() |
将序表转化为内表,继承序表的键:
|
|
4 |
=A3.index@s() |
内表的键为排号类型,使用@s选项,为内表创建多层树状索引。 |

为内表建立序号索引:
|
|
A |
|
|
1 |
=to(100).new(~*2:c1,rand():c2) |
创建序表:
|
|
2 |
=A1.memory() |
用序表生成内表。 |
|
3 |
=A2.index@n() |
|
|
4 |
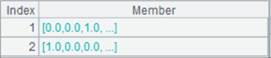
=A3.find(6) |
查询内表中键值为6的记录,即序号为6的记录,返回结果如下:
|
|
5 |
=A2.keys(c1) |
重置内表的键,设置c1为键字段,清除内表中的索引表。 |
|
6 |
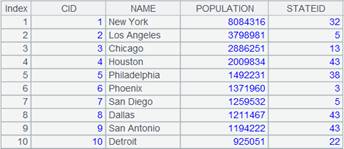
=A3.find(6) |
查询键值为6的记录,返回结果如下:
|

T.index(f:h,w;C,…;F,…)
描述:
备注:
将实表T中满足条件w的记录以列 C,…作为键创建索引文件对象f; 索引不会跟随组表更新(包括reset)。
创建索引文件时参数C和f不可省略。
F为T的字段名,有F时可以提升查询速度,使用索引取数时,只能取出索引字段C和字段F,F省略时可取出所有字段。
有h且无@w选项时,创建长度为h的hash索引文件;有@w选项时创建全文索引文件;参数h及@w选项缺省则创建排序索引文件;创建hash索引与全文索引时,要求参数F省略。
当T是附表时,参数C不允许是从主表继承的字段。
参数:
|
T |
实表。 |
|
f |
索引文件对象。 |
|
w |
筛选条件,可省略,缺省读取全集。 |
|
C |
建立索引的字段。 |
|
h |
hash索引长度,可省略。 |
|
F |
实表的字段名,可省略。 |
选项:
|
@2 |
只有参数f时可使用,用于加载索引文件至内存,可以提高查询性能。 |
|
@3 |
只有参数f时可使用,用于加载索引文件至内存,相对于@2性能更高但占用内存也更多。 |
|
@0 |
只有参数f时,释放索引文件占用的内存。 |
|
@w |
按列C建立全文索引文件,使用@w时只能有一个C,并且C为String类型。 只支持like("*X*")式检索,X可以是字母/数字/常见字符组成的串,也可以是汉字,X是字母/数字/常见字符组成的串时长度必须大于2。 索引串为字母时大小写不敏感。 使用@w时,h解释为每个索引串匹配的最大记录数,h缺省则不限制。 |
返回值:
实表
创建排序索引文件:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,BIRTHDAY,DEPT,GENDER,HIREDATE,SALARY from employee ") |
返回序表。 |
|
2 |
=file("empi.ctx") |
|
|
3 |
=A2.create@y(#EID,NAME,BIRTHDAY,DEPT,GENDER,HIREDATE,SALARY) |
创建组表。 |
|
4 |
=A3.append@i(A1) |
将A1序表中的数据追加到组表中。 |
|
5 |
=file("index_dzdpx") |
索引文件对象。 |
|
6 |
=A3.index(A5,DEPT=="HR";EID;DEPT) |
给组表A3 中满足条件DEPT=="HR"的EID、DEPT字段数据创建排序索引文件index_dzdpx,索引字段为EID。 |
|
7 |
=file("index_px") |
索引文件对象。 |
|
8 |
=A3.index(A7;EID,NAME) |
给组表A3创建索引文件index_px,索引字段为EID、NAME,参数F省略,可读取所有字段。 |
|
9 |
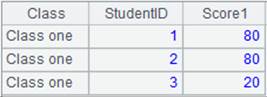
=A3.icursor(EID,NAME,DEPT,SALARY;EID<20;A7,A5) |
通过索引文件查询组表中EID<20的EID、NAME、DEPT、SALARY字段的数据:
|
创建hash索引文件:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
打开组表文件。 |
|
2 |
=file("index_hs") |
索引文件对象。 |
|
3 |
=A1.index(A2:10;DEPT,GENDER) |
为组表empi.ctx创建长度为10的hash索引文件,索引字段为DEPT,GENDER。 |
|
4 |
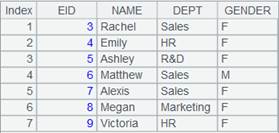
=A1.icursor(NAME,DEPT,GENDER,SALARY;[["HR","M"]].contain(DEPT,GENDER);A2) |
通过索引文件index_hs查询组表中DEPT为HR且GENDER为M的NAME、DEPT、GENDER、SALARY字段的数据,返回游标中的数据内容如下:
|
创建全文索引文件:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
打开组表文件。 |
|
2 |
=file("index_qw") |
索引文件对象。 |
|
3 |
=A1.index@w(A2;NAME) |
使用@w选项,为组表empi.ctx创建全文索引文件,索引字段为NAME。 |
|
4 |
=A1.icursor(EID,NAME,BIRTHDAY;like(NAME,"*ann*");A2) |
通过索引文件index_qw查询组表中NAME值中含有字串“ann”的记录,将记录中的EID、NAME、BIRTHDAY字段的数据返回到游标中,数据内容如下:
|
|
5 |
=file("index_qw1") |
|
|
6 |
=A1.index@w(A5:5;NAME) |
使用@w建立的全文索引文件,索引串大小写不敏感;参数h为5,表示每个索引串匹配的最大记录数。 |
|
7 |
=A1.icursor(EID,NAME,BIRTHDAY;like(NAME,"*ANN*");A5) |
返回游标的数据内容如下:
|

主动加载组表的索引文件:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
打开组表文件。 |
|
2 |
=A1.index@2(file("index_qw")) |
加载组表的索引文件到内存。 |
|
3 |
=A1.icursor(EID,NAME,BIRTHDAY;like(NAME,"A*");file("index_qw")) |
使用已经加载到内存中的索引文件进行组表数据查询。 |
|
4 |
=A1.index@0(file("index_qw")) |
释放索引文件占用的内存。 |
|
5 |
>A1.close() |
关闭组表。 |
T.index(I:h,w;C,…)
为内表建立非主键索引。
语法:
T.index(I:h,w;C,…)
备注:
为内表T中满足条件w的记录基于非键字段 C,…创建索引I,其中w可以省略。
有h时创建长度为h的hash索引,h为0时用缺省自动计算出HASH表长度。
无C参数时删除索引I,无参数I时删除所有索引。
为内表T建立的非主键索引,在生成游标时可用,可以建立多个。
参数:
|
T |
内表。 |
|
I |
索引名称。 |
|
w |
筛选条件,缺省读取全集。 |
|
C |
建立索引的字段。 |
|
h |
索引长度。 |
返回值:
内表
示例:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES ") |
|
|
2 |
=file("SCORES_ClassTwo.ctx") |
创建组表文件。 |
|
3 |
=A2.create@y(#CLASS,#STUDENTID,SUBJECT,SCORE) |
创建组表的基表,其中CLASS,#STUDENTID为组表的键。 |
|
4 |
=A3.append@i(A1) |
将A1游标中的数据追加到基表中。 |
|
5 |
=A4.memory() |
生成内表。 |
|
6 |
=A5.index(index1:10,CLASS =="Class one";SCORE) |
对内表建立非主键索引,索引名称为index1。 |
|
7 |
=A5.icursor(;;index1) |
通过内表索引名称查询内表数据,结果返回游标。 |