
T.icursor( C,…;w;f,… )
描述:
T.icursor(C,…;w;f,…)
用索引文件f查询实表/内表T的数据,w为过滤条件,C,…为查询字段名。
hash索引时,只能等值查询,且查询条件w中的字段要与索引字段一致。
全文索引时,w只能对String类型的字段过滤,支持like("*X*")式查询。
参数:
|
T |
实表/内表。 |
|
C |
实表中的列名,缺省时读取全部列。 |
|
w |
过滤条件,语法支持>、>=、<、<=、==、contain,过滤条件中用到的T表字段必须是索引字段。参数w不可省略。 |
|
f |
索引文件对象,多个f时程序会自动使用合适的索引文件。T为内表时,f为内表索引名称。 |
选项:
|
@s |
返回结果集对索引字段有序,支持大结果集。 |
|
@u |
从左到右处理多&&条件,缺省会根据条件优化过滤次序。 |
返回值:
单路游标
示例:
使用排序索引文件:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,BIRTHDAY,DEPT,GENDER,HIREDATE,SALARY from employee ") |
返回序表。 |
|
2 |
=file("empi.ctx") |
|
|
3 |
=A2.create@y(#EID,NAME,BIRTHDAY,DEPT,GENDER,HIREDATE,SALARY) |
创建组表。 |
|
4 |
=A3.append@i(A1) |
将A1序表中的数据追加到组表中。 |
|
5 |
=file("index_dzdpx") |
索引文件对象。 |
|
6 |
=A3.index(A5,DEPT=="HR";EID;DEPT) |
给组表A3 中满足条件DEPT=="HR"的EID、DEPT字段数据创建排序索引文件index_dzdpx,索引字段为EID。 |
|
7 |
=file("index_px") |
索引文件对象。 |
|
8 |
=A3.index(A7;EID,NAME) |
给组表A3创建索引文件index_px,索引字段为EID、NAME,参数F省略,可读取所有字段。 |
|
9 |
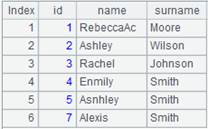
=A3.icursor@u(EID,NAME,DEPT,SALARY;EID<20&&EID>15;A7,A5) |
通过索引文件查询组表中EID<20的EID、NAME、DEPT、SALARY字段的数据,由于A5索引文件中不包含字段NAME、DEPT,所以执行该表达式时自动使用了A7索引,使用@u选项,从左到右处理多&&条件:
|
使用hash索引文件:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
打开组表文件。 |
|
2 |
=file("index_hs") |
索引文件对象。 |
|
3 |
=A1.index(A2:10;DEPT,GENDER) |
为组表empi.ctx创建长度为10的hash索引文件,索引字段为DEPT,GENDER。 |
|
4 |
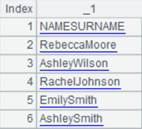
=A1.icursor(NAME,DEPT,GENDER,SALARY;[["HR","M"]].contain(DEPT,GENDER);A2) |
通过索引文件index_hs查询组表中DEPT为HR且GENDER为M的NAME、DEPT、GENDER、SALARY字段的数据,使用hash索引时,只能等值查询,并且过滤条件中的字段值要与索引字段一致,返回游标中的数据内容如下:
|
使用全文索引文件:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
打开组表文件。 |
|
2 |
=file("index_qw") |
索引文件对象。 |
|
3 |
=A1.index@w(A2;NAME) |
使用@w选项,为组表empi.ctx创建全文索引文件,索引字段为NAME。 |
|
4 |
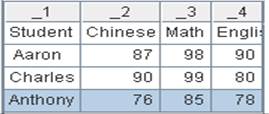
=A1.icursor (EID,NAME,GENDER,BIRTHDAY;like(NAME,"A*");A2) |
通过索引文件index_qw查询组表中NAME值为A开头的EID、NAME、GENDER、BIRTHDAY字段的数据,。返回游标中的数据内容如下:
|

使用@s选项,返回结果集对索引字段有序:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
打开组表文件。 |
|
2 |
=file("index_px") |
索引文件对象。 |
|
3 |
=A1.index(A2;DEPT) |
创建索引文件,索引字段为DEPT。 |
|
4 |
根据索引文件查询组表数据,C参数省略返回所有列:
|
|
|
5 |
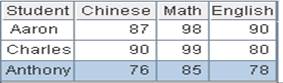
=A1.icursor@s(;DEPT=="HR"||DEPT=="R&D";A2).fetch() |
使用@s选项,返回结果集对索引字段有序:
|
使用内表索引:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES ") |
|
|
2 |
=file("SCORES_ClassTwo.ctx") |
|
|
3 |
=A2.create@y(#CLASS,#STUDENTID,SUBJECT,SCORE) |
创建组表。 |
|
4 |
=A3.append@i(A1) |
将A1游标中的数据追加到组表中。 |
|
5 |
=A4.memory() |
用实表生成内表。 |
|
6 |
=A5.index(index1:10,CLASS =="Class one";SCORE) |
为内表建立非主键索引,索引名称为index1。 |
|
7 |
=A5.icursor(;;index1) |
通过内表索引名称查询内表数据。 |