group()
本章介绍group()函数的多种用法。
A.group(x i ,…)
按xi,…做等值分组。
语法:
A.group(xi,…)
备注:
将序列A按照表达式xi,…等值分组,结果为组集构成的序列/排列。
选项:
|
@o |
只和相邻对比,相当于归并,结果集不再排序。 |
|
@1 |
取每个分组的第一条记录,组成排列后返回(注意是数字1,不是字母l),可以与@v配合使用。 |
|
@n |
x取值为分组序号,可直接定位;与@o互斥;将x<1的数据组丢弃。 |
|
@u |
结果集不再按x排序;与@o/@n互斥。 |
|
@i |
x是布尔表达式,如果x的结果为true则开始新的一组。相当于A.group@o(a+=if(x,1,0))中a=0且只有一个x。 |
|
@0 |
将x的计算结果为空的组丢弃,当只有一个x时可以用该选项,与@n一起使用时,也将空组丢弃。 |
|
@s |
分组后序列/排列和列,相当于A.group(xi,…).conj(),可以与@v配合使用。 |
|
@p |
返回组成员在A中位置构成的数列的序列。 |
|
@h |
用于分段有序的数据,可提高分组效率。 |
|
@v |
A为纯序表时,返回成纯序表构成的集合。仅企业版适用。 |
参数:
|
A |
序列。 |
|
xi |
分组表达式。 |
返回值:
序列/排列
示例:
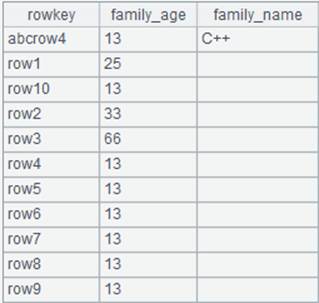
Ø 对数列分组
|
|
A |
|
|
1 |
[6,9,12,15,16,5,1,7,8] |
|
|
2 |
=A1.group(~%2) |
[[6,12,16,8],[ 9,15,5,1,7]]数列被分为2组,一组成员除以2余数为0,另一组成员除以2余数为1。 |
|
3 |
=A1.group(~%2,~%3) |
[[6,12],[16],[8],[9,15],[1,7],[5]]按照多个表达式分组。 |
|
4 |
=[6,9,16,5,1,7,8].group@s(~%2) |
按照奇偶数分组后和列:
|
|
5 |
=A1.group((#-1)\3) |
对序列A1分组,每3个一组:
|
Ø 对分组结果重复利用
|
|
A |
|
|
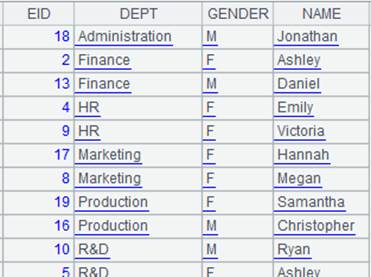
1 |
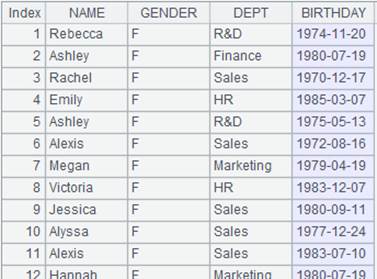
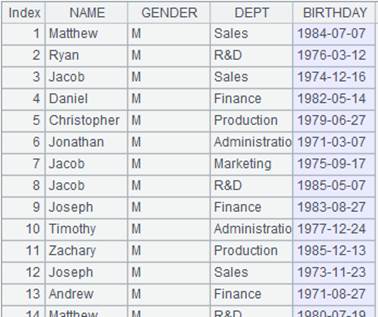
=demo.query("select NAME,BIRTHDAY,GENDER from EMPLOYEE") |
|
|
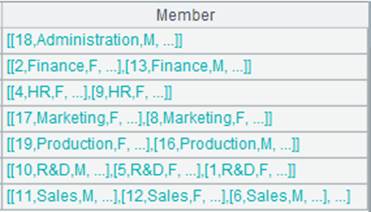
2 |
=A1.group(GENDER) |
A1序表根据GENDER分组:
点开分组后每个成员就是一个序列。
|
|
3 |
=A2.new(GENDER:Gender,~.count():Number) |
对分组后的成员统计。 |
|
4 |
=A2.new(GENDER:Gender,~.avg(age(BIRTHDAY)):Average) |
对分组结果重复利用,再次进行不同的统计。 |

Ø 多种分组方式
|
|
A |
|
|
1 |
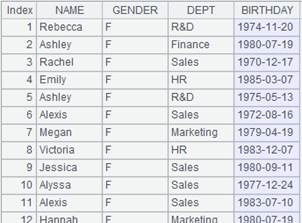
=demo.query("select NAME,GENDER,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
=A1.group(GENDER,DEPT) |
多字段分组。 |
|
3 |
=A1.group@o(GENDER) |
不排序,相邻的记录比较,相同的记录归为一组。不相邻但相同的记录可能变成两组,因此会出现重复的组,返回序列集。
|
|
4 |
=A1.group@1(GENDER) |
返回每组第一条记录:
|
|
5 |
=A1.group@n(if(GENDER=="F",1,2)) |
x取值为分组序号,可直接定位 [[Rebecca,Ashley,Rachel,…],[Matthew,Ryan,Jacob,…]]。 |
|
6 |
=A1.group@u(GENDER,DEPT) |
结果集不按分组字段排序。 |
|
7 |
=A1.group@i(GENDER=="F") |
遇到GENDER=="F"则开始新的分组。 |
|
8 |
=A1.group@p(GENDER,DEPT) |
返回按照字段GENDER,DEPT分组后,记录在原序表中的位置构成的序列。 |
|
9 |
=file("D:\\Salesman.txt").import@t() |
|
|
10 |
=A9.group@0(Gender) |
按照字段Gender分组,为空的组丢弃不显示。 |
|
11 |
=file("D:/emp10.txt").import@t() |
数据文件emp10.txt中,每10条数据根据DEPT进行了一次排序:
|
|
12 |
=A11.group@h(DEPT) |
A11是以DEPT分段有序的数据,使用@h选项提高分组效率:
|
|
13 |
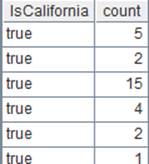
=A1.group@n(if(DEPT=="HR":1,DEPT=="Sales":2;0)) |
使用@n选项,函数参数值小于1的数据丢弃,即将DEPT不为HR也不是Sales的数据组丢弃:
|


Ø A为序表
|
|
A |
|
|
1 |
=demo.query@v("select * from EMPLOYEE order by GENDER,DEPT ") |
返回纯序表。 |
|
2 |
=A1.group@v(GENDER,DEPT) |
使用@v选项,返回纯序表构成的集合。 |
相关概念:
A.group(x:F,...;y:G,…)
描述:
对序列先分组再聚合。
语法:
A.group(x:F,...;y:G,…)
备注:
将序列按照一个或多个字段/表达式分组,然后再聚合。按照x分组后,形成以F,... G,…为字段的新序表。新序表按分组表达式x排序,G字段值为对每一组执行聚合函数y后的结果。
选项:
|
@o |
只和相邻对比,相当于归并,结果集不再排序。 |
|
@n |
x取值为分组序号,可直接定位;与@o互斥。 |
|
@u |
结果集不再按x排序;与@o/@n互斥。 |
|
@i |
x是布尔表达式,如果x的结果为true则开始新的一组。此时只有一个x。 |
|
@0 |
将x的计算结果为空的组丢弃。 |
|
@h |
用于分段有序的数据,可提高分组效率。 |
|
@t |
当A的返回值为空,则返回一个保留数据结构的空序表。 |
|
@s |
以累计方式计算。 |
参数:
|
A |
序列。 |
|
x |
分组表达式,x:F省略则不分组针对全集聚合,此时分号;不可省略。 |
|
F |
结果序表的字段名。 |
|
G |
结果序表中的汇总字段名。 |
|
y |
聚合表达式,用~引用组。 |
返回值:
序列
示例:
|
|
A |
|
|
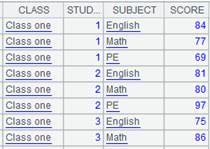
1 |
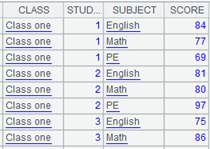
=demo.query("select * from SCORES") |
|
|
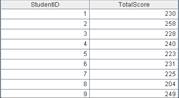
2 |
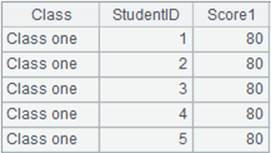
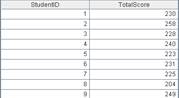
=A1.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
|
|
3 |
=A1.group@o(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
只和相邻的对比归并,结果集不排序。 |
|
4 |
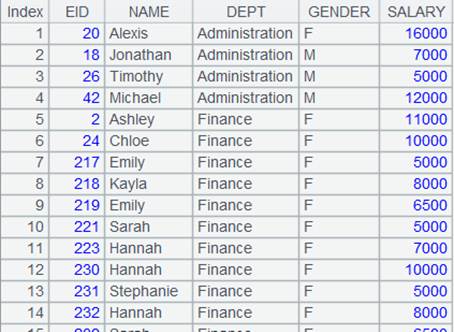
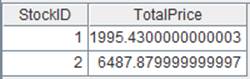
=demo.query("select * from STOCKRECORDS where STOCKID<'002242'") |
|
|
5 |
=A4.group@n(if(STOCKID=="000062",1,2):StockID;~.sum(CLOSING):TotalPrice) |
x取值为分组序号。 |
|
6 |
=A1.group(;~.sum(SCORE):TotalScore) |
省略x:F求所有学生的总成绩。 |
|
7 |
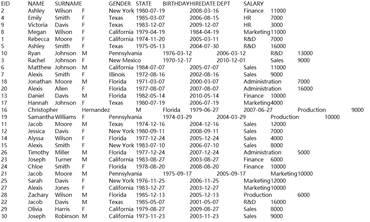
=demo.query("select * from EMPLOYEE") |
|
|
8 |
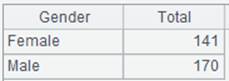
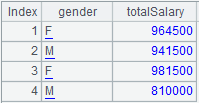
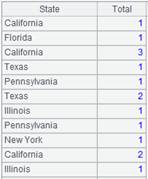
=A7.group@u(STATE:State;~.count(STATE):TotalScore) |
结果集不按分组字段排序。 |
|
9 |
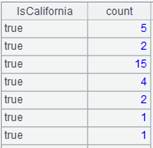
=A7.group@i((GENDER=="F"):IsF;~.count():Number) |
遇到GENDER=="F"则开始新的分组。 |
|
10 |
=file("D:\\Salesman.txt").import@t() |
|
|
11 |
=A10.group@0(Gender:Gender;~.sum(Age):Total) |
Gender为空的组丢弃。 |
|
12 |
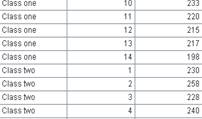
=file("D:/emp10.txt").import@t() |
数据文件emp10.txt中,每10条数据根据DEPT进行了一次排序:
|
|
13 |
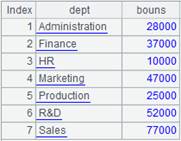
=A12.group@h(DEPT:dept;~.sum(SALARY):bouns) |
A12是以DEPT分段有序的数据,使用@h选项提高分组效率:
|
|
14 |
=demo.query("select * from EMPLOYEE where EID > 500") |
返回空序表。 |
|
15 |
=A14.group@t(STATE:State;~.count(STATE):TotalScore) |
返回保留数据结构的空序表:
|
|
16 |
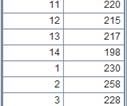
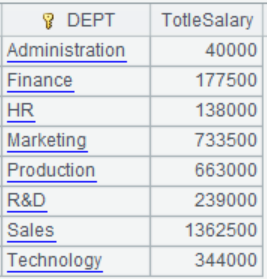
=demo.query("select * from employee").group@s(DEPT;sum(SALARY):TotleSalary) |
以累计方式计算:
|



相关概念:
ch.group()
管道中附加相邻值分组动作后返回原管道。
ch.group(x,…)
备注:
管道ch附加计算,ch按照x分组,x只和相邻的记录对比,相当于归并,要求ch有序,返回原管道。
选项:
|
@i |
x是布尔表达式,如果x的结果为true则开始新的一组。此时只有一个x。 |
|
@1 |
取每组的第一条记录组成排列返回到原管道(注意是数字1,不是字母l)。 |
参数:
|
ch |
管道。 |
|
x |
分组表达式。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
=demo.cursor("select EID,GENDER,DEPT,NAME,SALARY from EMPLOYEE").sortx(GENDER,DEPT) |
返回游标,游标中的数据对GENDER,DEPT有序。 |
|
2 |
=channel() |
创建管道。 |
|
3 |
=A2.group(GENDER,DEPT) |
A2管道附加计算,按照GENDER,DEPT分组。 |
|
4 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据。 |
|
5 |
=A1.push(A2) |
将游标A1中的数据推送到管道A2,此时数据不会立即被推送到管道。 |
|
6 |
=A1.skip() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
7 |
=A2.result() |
获取管道计算结果:
|

|
|
A |
|
|
1 |
=demo.cursor("select EID,GENDER,DEPT,NAME,SALARY from EMPLOYEE").sortx(DEPT) |
返回游标,游标中的数据对DEPT有序。 |
|
2 |
=channel() |
创建管道。 |
|
3 |
=channel() |
创建管道。 |
|
4 |
=A2.group@1(DEPT) |
管道A2附加计算,按照DEPT分组,使用@1选项,取每组的第一条记录组成排列,返回原管道A2。 |
|
5 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据。 |
|
6 |
=A3.group@i(DEPT=="HR") |
管道A3附加计算,按照DEPT分组,使用@i选项,遇到DEPT ==" HR "则开始新的分组,返回原管道A3。 |
|
7 |
=A3.fetch() |
A3管道执行结果集函数,保留管道当前数据。 |
|
8 |
=A1.push(A2,A3) |
将游标A1中的数据推送到管道A2和A3,此时数据不会立即被推送到管道。 |
|
9 |
=A1.skip() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
10 |
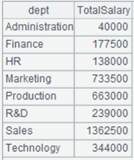
=A2.result() |
获取A2管道计算结果:
|
|
11 |
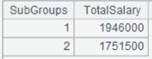
=A3.result() |
获取A3管道计算结果:
|
cs.group()
游标中附加相邻值分组动作后返回原游标。
语法:
cs.group(x,…)
备注:
游标cs附加计算,cs按照x分组,x只和相邻的记录对比,相当于归并,要求cs有序,返回原游标cs,支持多路游标。
选项:
|
@i |
x是布尔表达式,如果x的结果为true则开始新的一组。此时只有一个x。 |
|
@1 |
取每组的第一条记录组成排列返回到原游标(注意是数字1,不是字母l)。 |
|
@v |
cs是纯序表游标时,每组子集将复制成新的纯序表。仅企业版适用。 |
参数:
|
cs |
游标/多路游标。 |
|
x |
分组表达式。 |
返回值:
游标
示例:
|
|
A |
|
|
1 |
=demo.cursor("select * from EMPLOYEE").sortx(GENDER,DEPT) |
返回游标,游标中的数据对GENDER、DEPT有序。 |
|
2 |
=A1.group(GENDER,DEPT) |
游标A1附加计算,相邻记录中GENDER与DEPT字段值都相同时,记录分到同一组中,返回原A1游标。 |
|
3 |
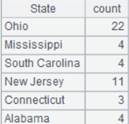
=A1.fetch() |
读取游标A1执行A2计算后的数据(数据量较大时建议分批读取):
|
使用@i选项:
|
|
A |
|
|
1 |
=demo.cursor("select * from STOCKRECORDS where STOCKID='000062' ").sortx(DATE) |
返回游标,游标中的数据对DATE有序。 |
|
2 |
=A1.group@i(CLOSING<CLOSING[-1]) |
游标A1附加计算,使用@i选项,当记录中的CLOSING值小于上一条记录中的CLOSING值时,开始新的一组,返回原A1游标。 |
|
3 |
读取游标A1执行A2计算后的数据:
|

使用@1选项:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,HIREDATE from EMPLOYEE").sortx(DEPT,HIREDATE) |
返回游标,游标中的数据对DEPT、HIREDATE有序。 |
|
2 |
=A1.group@1 (DEPT) |
游标A1附加计算,使用@1选项,游标记录根据DEPT分组,取每组的第一条记录,返回原A1游标。 |
|
3 |
=A1.fetch() |
读取游标A1执行A2计算后的数据:
|
cs为纯序表游标:
|
|
A |
|
|
1 |
=demo.cursor@v("select * from EMPLOYEE order by GENDER,DEPT ") |
返回纯序表游标。 |
|
2 |
=A1.group@v(GENDER,DEPT) |
游标A1附加计算,使用@v选项,每组子集将复制成新的纯序表,返回原游标。 |
|
3 |
=A1.() |
获取A1游标执行A2计算后的分组数。 |
相关概念:
cs.group()
描述:
针对集群游标记录做相邻值分组。
语法:
cs.group(x,…)
备注:
针对集群游标记录cs按照x分组,x只和相邻的记录对比,相当于归并,要求cs有序,返回由序列构成的原集群游标,支持多路游标。
该函数仅适用于企业版。
参数:
|
cs |
集群游标记录。 |
|
x |
分组表达式,多个字段/表达式组合分组时,每个分组表达式用逗号隔开。 |
返回值:
原集群游标
示例:
|
|
A |
|
|
1 |
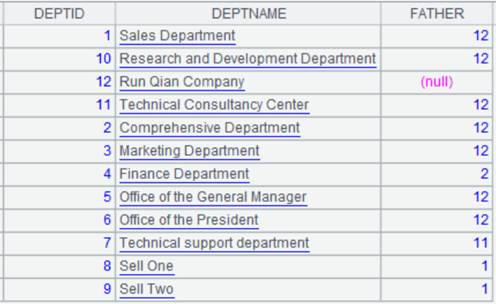
=file("employees.ctx","192.168.0.111:8281") |
employees.ctx文件对DEPT有序,数据内容如下:
|
|
2 |
=A1.open() |
打开集群组表。 |
|
3 |
=A2.cursor() |
返回集群游标。 |
|
4 |
=A3.group(DEPT) |
将集群游标记录根据DEPT分组,结果返回原集群游标。 |
|
5 |
=A4.fetch() |
|
cs.group(x:F,…;y:G,…)
描述:
游标中附加相邻值分组聚合动作后返回原游标。
语法:
备注:
游标cs附加计算,cs根据x分组后计算聚合表达式y,x为字段F的值,y为字段G的值, 形成以F,... G,…为字段的序表返回到原游标cs。支持多路游标。
cs对x有序,x只和相邻的记录对比,结果集不再排序。
该函数属于延迟计算函数。
参数:
|
cs |
游标。 |
|
x |
分组表达式。 |
|
F |
字段名。 |
|
G |
汇总字段名。 |
|
y |
聚合表达式。 |
选项:
|
@s |
用累积方式聚合。 |
|
@q(x:F,…;x’:F’,…; y:G,…) |
cs已对x,…有序,仅后面的字段需要排序时可用该选项,可以内存排序。 |
|
@sq(x:F,…;x’:F’,…; y:G,…) |
没有y:G参数时仅排序,不分组;有y:G参数时按累计方式聚合。该用法中@s必须与@q配合使用。 |
|
@e |
将y的结果组成的序表返回到原游标。其中x为cs的字段名,y是cs的函数,y的计算结果要求是cs的一条记录,当y是聚合函数时仅支持maxp/minp/top@1。 组合使用@sev选项时,返回结果为纯序表。 |
返回值:
游标
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES").sortx(CLASS,STUDENTID) |
返回游标,游标内容对CLASS,STUDENTID有序,数据内容如下:
|
|
2 |
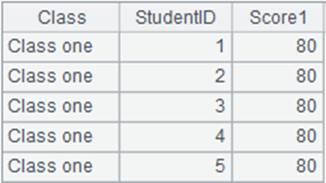
=A1.group(CLASS:Class,STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
游标A1附加计算,根据CLASS,STUDENTID相邻值分组,汇总每组的SCORE值,汇总结果作为TotalScore字段值,返回原游标cs。 |
|
3 |
=A1.fetch() |
读取游标A1执行A2计算后的数据:
|

使用@q选项:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE ").sortx(DEPT) |
返回游标,游标内容对DEPT有序,数据内容如下:
|
|
2 |
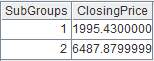
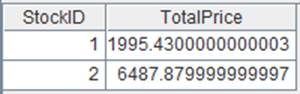
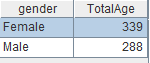
=A1.group@q(DEPT;GENDER;~.avg(SALARY):Avg_Salary) |
游标A1附加计算,游标对DEPT有序,仅GENDER字段需要排序,使用@q选项进行内存排序,返回原游标cs。 |
|
3 |
=A1.fetch() |
读取游标A1执行A2计算后的数据:
|
使用@sq选项,无需汇总仅排序时:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE ").sortx(DEPT) |
返回游标,游标内容对DEPT有序,数据内容如下:
|
|
2 |
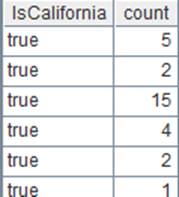
=A1.group@sq(DEPT;GENDER) |
游标A1附加计算,游标仅对DEPT有序,且省略汇总聚合参数,使用@sq选项仅排序不分组,返回原游标cs。 |
|
3 |
=A1.fetch() |
读取游标A1执行A2计算后的数据:
|
使用@e选项,将y的结果组成的序表返回到原游标:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,SALARY from EMPLOYEE ").sortx(DEPT) |
返回游标,游标内容对DEPT有序。 |
|
2 |
=A1.group@e(DEPT;~.maxp(SALARY)) |
游标A1附加计算,使用@e选项,将maxp(SALARY)结果记录返回到原游标。 |
|
3 |
=A1.fetch() |
读取游标A1执行A2计算后的数据:
|
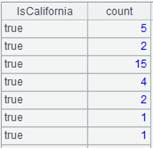
cs.group(x:F,…;y:G,…)
描述:
对集群游标做相邻分组聚合,返回原集群游标。
语法:
cs.group(x:F,...;y:G,…)
备注:
针对集群游标记录cs按照x分组,cs对x有序,x只和相邻的记录对比,同时计算出y,结果集不再排序。按照x分组后,形成以F,... G,…为字段的原游标。G字段值为对每一组执行聚合函数y后的结果,支持多路游标。
参数:
|
cs |
集群游标。 |
|
x |
分组表达式。 |
|
F |
字段名。 |
|
G |
汇总字段名。 |
|
y |
聚合表达式。 |
返回值:
集群游标
示例:
|
|
|
|
|
1 |
=file("employees.ctx","192.168.0.111:8281") |
employees.ctx文件对DEPT有序,数据内容如下:
|
|
2 |
=A1.open() |
打开集群组表。 |
|
3 |
=A2.cursor() |
返回集群游标。 |
|
4 |
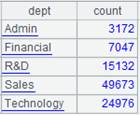
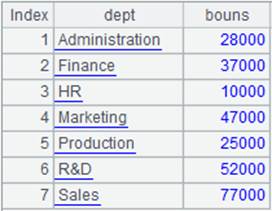
=A3.group(DEPT:dept;~.count(NAME):count) |
根据DEPT相邻分组,然后聚合,结果返回原集群游标。 |
|
5 |
=A4.fetch() |
|
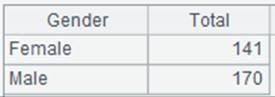
T. group ()
描述:
虚表定义相邻值分组操作后返回新虚表。
语法:
备注:
虚表T定义计算, xi只和相邻的记录对比,返回新虚表。
该函数仅适用于企业版。
参数:
|
T |
虚表。 |
|
xi |
分组表达式,多个字段/表达式组合分组时,每个分组表达式用逗号隔开。 |
选项:
|
@i |
x是布尔表达式,如果x的结果为true则开始新的一组。此时只有一个x。 |
|
@1 |
取每一个分组的第一条记录组成排列后返回(注意是数字1,不是字母l)。 |
返回值:
虚表
示例:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/empT.ctx"]) |
|
|
2 |
=pseudo(A1) |
生成虚表对象,虚表数据内容如下:
数据对DEPT、 GENDER有序。 |
|
3 |
=A2.group(GENDER,DEPT) |
虚表A2定义计算,相邻记录中GENDER与DEPT字段值皆相同时,记录分到同一组中,结果返回新虚表。 |
|
4 |
=A3.import() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|
|
5 |
=A2.group@i(GENDER=="F") |
使用@i选项,遇到GENDER=="F"则开始新的分组。 |
|
6 |
读取A5虚表数据:
|
|
|
7 |
=A2.group@1(GENDER) |
使用@1选项,返回每组第一条记录。 |
|
8 |
=A7.cursor().fetch() |
读取A7虚表数据:
|
T.group(x:F,…;y:G,…)
描述:
备注:
对虚表T定义计算,T根据x分组后计算聚合表达式y,x为字段F的值,y为字段G的值,x只和相邻的记录对比, 结果返回以F,... G,…为字段的新虚表
该函数仅适用于企业版。
参数:
|
T |
虚表。 |
|
x |
分组表达式。 |
|
F |
字段名。 |
|
G |
汇总字段名。 |
|
y |
聚合表达式。 |
选项:
|
@s |
用累积方式聚合。 |
|
@q(x:F,…;x’:F’,…;…) |
T已对x,…有序,仅后面的字段需要排序时可用该选项,可以内存排序。 |
|
@sq(x:F,…;x’:F’,…;…) |
没有y:G参数时仅排序,不分组;有y:G参数时按累计方式聚合。该用法中@s必须与@q配合使用。 |
|
@e |
返回y的结果组成的虚表。其中x为T的字段名,y是T的函数,y的计算结果要求是T的一条记录,当y是聚合函数时仅支持maxp/minp/top@1。 |
返回值:
虚表
示例:
|
|
A |
|
|
1 |
=create(file).record(["scores-g.ctx"]) |
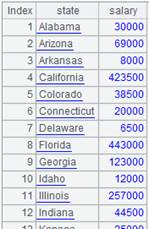
scores-g.ctx 为对STUDENTID有序的组表文件,内容如下:
|
|
2 |
=pseudo(A1) |
由A1组表生成虚表。 |
|
3 |
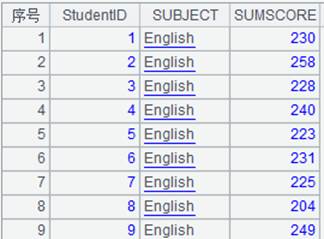
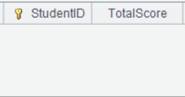
=A2.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
虚表A2定义计算,将虚表根据STUDENTID字段分组,并计算每组的SCORE的总值,结果返回新虚表。 |
|
4 |
=A3.import() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|
|
|
A |
|
|
1 |
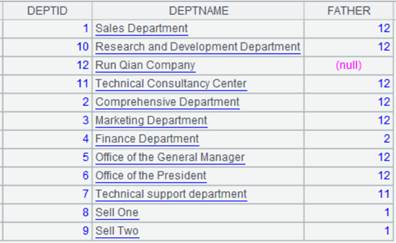
=create(file).record(["emp-g.ctx"]) |
emp-g.ctx为对DEPT有序的组表文件,内容如下:
|
|
2 |
=pseudo(A1) |
由A1组表产生虚表。 |
|
3 |
=A2.group@q(DEPT;GENDER) |
虚表A2定义计算,虚表已经对DEPT有序,所以分组时仅对GENDER排序,返回新虚表。 |
|
4 |
=A3.cursor().fetch() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|
|
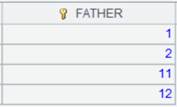
5 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER) |
虚表A2定义计算,没有y:G参数时仅排序,不分组,返回新虚表。 |
|
6 |
=A5.import() |
读取A5虚表中的数据,此时A2虚表执行A5中定义的计算操作,返回内容如下:
|
|
7 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER;count(GENDER):count) |
虚表A2定义计算,有y:G参数,按累计方式聚合,返回新虚表。 |
|
8 |
=A7.import() |
读取A7虚表中的数据,此时A2虚表执行A7中定义的计算操作,返回内容如下:
|

使用@e选项,返回y的结果组成的虚表:
|
|
A |
|
|
1 |
=create(file).record(["emp-g.ctx"]) |
组表emp-g.ctx中的内容如下:
|
|
2 |
=pseudo(A1) |
由A1组表产生虚表。 |
|
3 |
=A2.group@e(DEPT;~.minp(SALARY)) |
虚表A2定义计算,使用@e选项,返回由minp(SALARY)结果记录构成的新虚表。 |
|
4 |
=A3.cursor().fetch() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|